
学习机器学习默认导入库:
%matplotlib notebook import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn
分析过程:
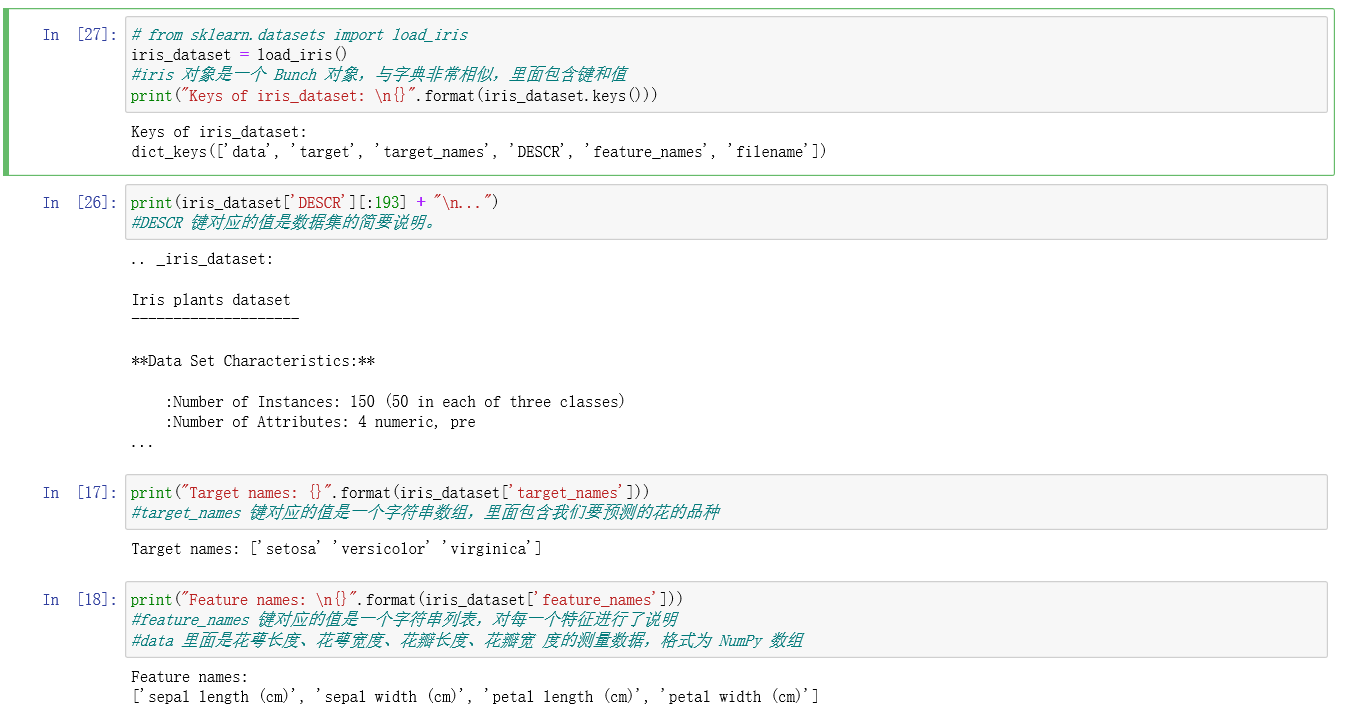
我们构思了一项任务,要利用鸢尾花的物理测量数据来预测其品种。我们在构建模型时用到了由专家标注过 的测量数据集,专家已经给出了花的正确品种,因此这是一个监督学习问题。一共有三个 品种:setosa、versicolor 或 virginica,因此这是一个三分类问题。在分类问题中,可能的 品种被称为类别(class),每朵花的品种被称为它的标签(label)。
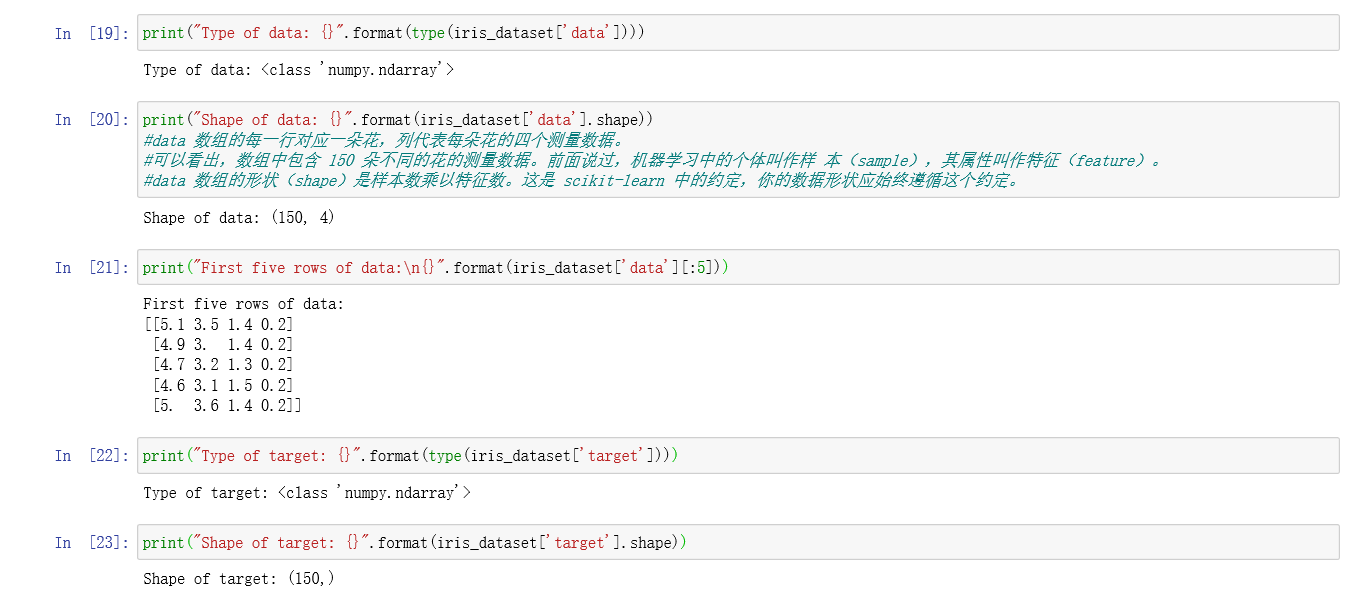
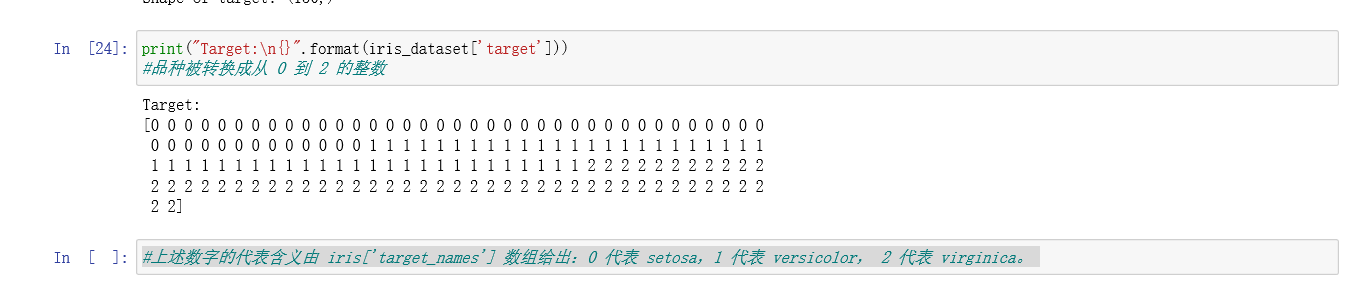
鸢尾花(Iris)数据集包含两个 NumPy 数组:一个包含数据,在 scikit-learn 中被称为 X; 一个包含正确的输出或预期输出,被称为 y。数组 X 是特征的二维数组,每个数据点对应 一行,每个特征对应一列。数组 y 是一维数组,里面包含一个类别标签,对每个样本都是 一个 0 到 2 之间的整数。
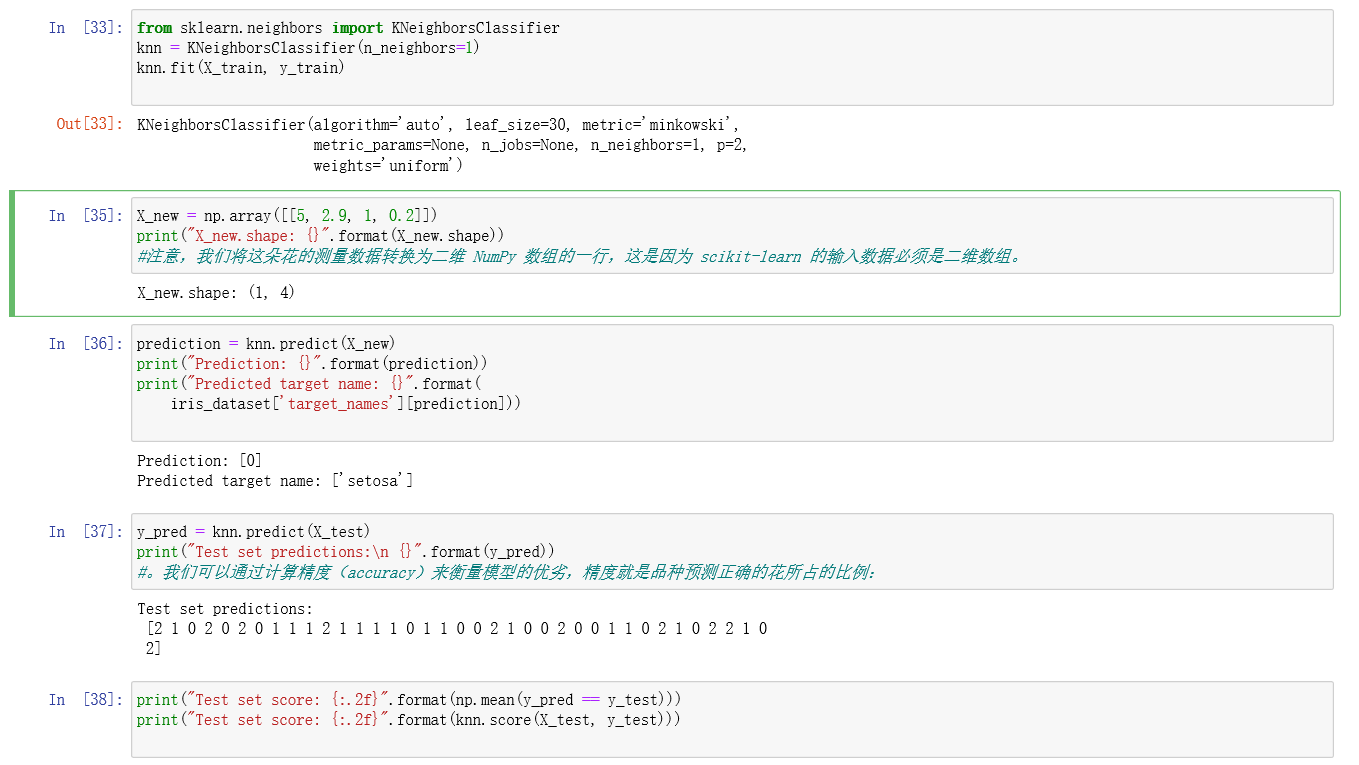
我们将数据集分成训练集(training set)和测试集(test set),前者用于构建模型,后者用 于评估模型对前所未见的新数据的泛化能力。
我们选择了 k 近邻分类算法,根据新数据点在训练集中距离最近的邻居来进行预测。该算 法在 KNeighborsClassifier 类中实现,里面既包含构建模型的算法,也包含利用模型进行 预测的算法。我们将类实例化,并设定参数。然后调用 fit 方法来构建模型,传入训练数 据(X_train)和训练输出(y_trian)作为参数。我们用 score 方法来评估模型,该方法 计算的是模型精度。我们将 score 方法用于测试集数据和测试集标签,得出模型的精度约 为 97%,也就是说,该模型在测试集上 97% 的预测都是正确的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号