
点击”下一页“检查元素:

网页阻止了链接,通过Ajax方式加载,抓包得到了一个网址
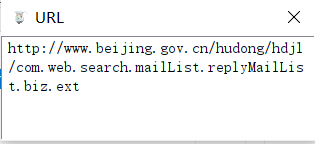
用POST方法返回了json数据:
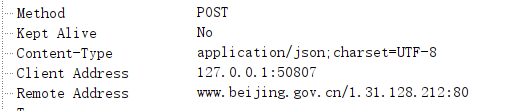

并且发现请求时的数据是这样的:

所以不用再在网页上爬取网址,可以直接请求json数据
import urllib.request import random import re #取消证书验证 import ssl ssl._create_default_https_context = ssl._create_unverified_context def moni(): #模拟请求头 agentList=[ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0" "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)" "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)" ] agentStr= random.choice(agentList) return agentStr def jsonCrawler(url): i=0 j=i+4 while(i<j): data = { "PageCond/begin": 6*i, "PageCond/length": 6, "PageCond/isCount": "true", "keywords": "", "orgids": "", "startDate": "", "endDate": "", "letterType": "2", "letterStatue": "" } i+=1 postData = urllib.parse.urlencode(data).encode("utf-8") req = urllib.request.Request(url, postData) req.add_header('User-Agent', moni()) response = urllib.request.urlopen(req) pattern = re.compile('{"letter_type":"(.*?)","original_id":"(.*?)"', re.S) results = pattern.findall(response.read().decode('utf-8')) with open("E:/A.txt", "ab")as f: for result in results: type, id= result id = re.sub("\s", "", id) if (type == "建议"): newurl = "http://www.beijing.gov.cn/hudong/hdjl/com.web.suggest.suggesDetail.flow?originalId=" + id elif (type == "咨询"): newurl = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=" + id f.write(newurl.encode("utf-8") + "\n".encode("utf-8")) def htmlCrawler(): for line in open("E:/A.txt"): req = urllib.request.Request(line) req.add_header('User-Agent', moni()) response = urllib.request.urlopen(req) pattern = re.compile('<div class="col-xs-12 col-md-12 column p-2 text-muted mx-2">(.*?)</div>', re.S) results = pattern.findall(response.read().decode('utf-8')) with open("E:/B.txt", "ab")as f: for result in results: result = re.sub("\s", "", result) f.write(result.encode("utf-8")+"\n".encode("utf-8")) url="http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.replyMailList.biz.ext" jsonCrawler(url) htmlCrawler()
一次爬取了4页

24条数据的爬取使用了大概6秒,一页6条数据,相当于1秒爬取一页,效率还是比较低,而且是写入txt文档,读写时占用内存资源
到此为止,暂时算完成了爬虫的学习。
之后继续在使用中不断的优化代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号