
聚类——认识FCM算法
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
一、FCM概述
FCM算法是基于对目标函数的优化基础上的一种数据聚类方法。聚类结果是每一个数据点对聚类中心的隶属程度,该隶属程度用一个数值来表示。该算法允许同一数据属于多个不同的类。
FCM算法是一种无监督的模糊聚类方法,在算法实现过程中不需要人为的干预。
这种算法的不足之处:首先,算法中需要设定一些参数,若参数的初始化选取的不合适,可能影响聚类结果的正确性;其次,当数据样本集合较大并且特征数目较多时,算法的实时性不太好。
K-means也叫硬C均值聚类(HCM),而FCM是模糊C均值聚类,它是HCM的延伸与拓展,HCM与FCM最大的区别在于隶属函数(划分矩阵)的取值不同,HCM的隶属函数只取两个值:0和1,而FCM的隶属函数可以取[0,1]之间的任何数。K-means和FCM都需要事先给定聚类的类别数,而FCM还需要选取恰当的加权指数α,α的选取对结果有一定的影响,α属于[0,+∞)。
二、FCM算法
C是聚类数,N是样本个数。U是隶属度矩阵,V是聚类中心。
目标函数:
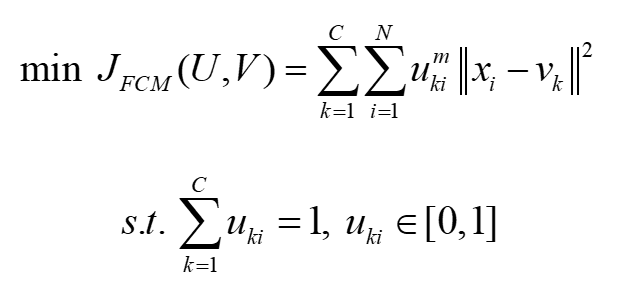
更新公式:
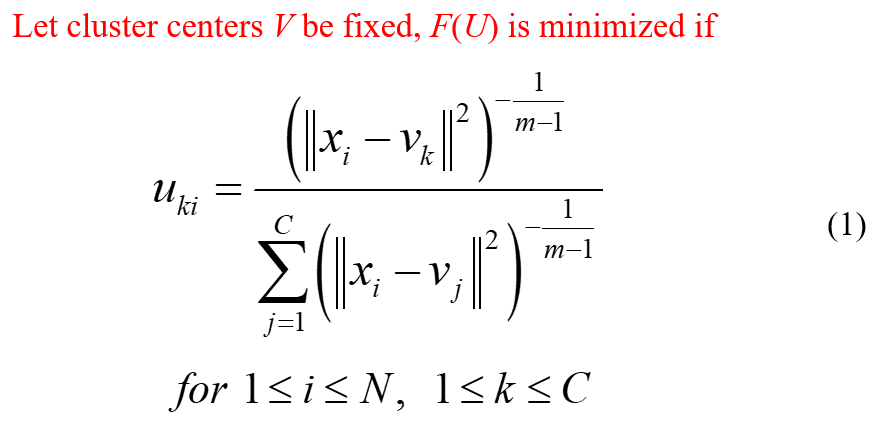
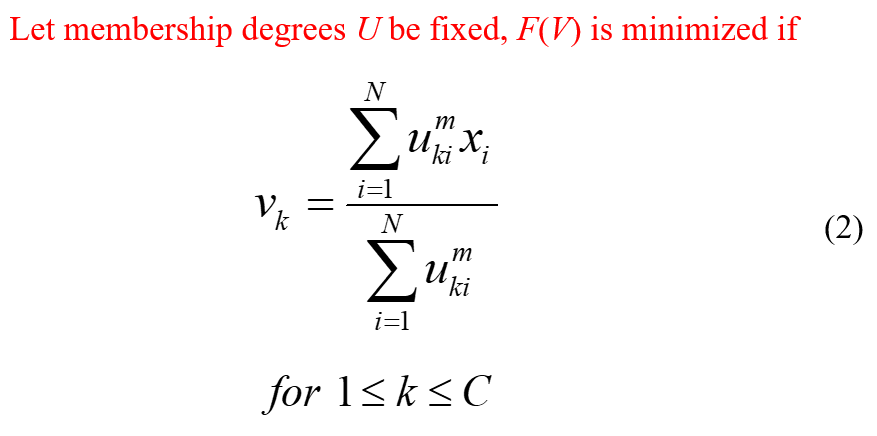
三、算法流程

四、FCM改进算法汇总




FCM改进版本汇总参考:J. Gu, L. Jiao, S. Yang and F. Liu, "Fuzzy Double C-Means Clustering Based on Sparse Self-Representation," in IEEE Transactions on Fuzzy Systems, vol. 26, no. 2, pp. 612-626, April 2018.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号