
Meta-RL——Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
这篇博客是“Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables”的简要阅读笔记,围绕如何从过去学习的任务中针对新的任务获取有效的信息以及如何对新任务的不确定性做出更准确的判断这两个问题,论文通过一个任务编码器来学习任务的表征(概率上下文变量z),融合软演员评论员算法(Soft Actor-Critic, SAC)与变分推断KL损失,提出一种异策略元强化学习算法,通过分离任务推断与智能体学习过程来提高元学习中任务的学习样本利用效率。
深度强化学习算法需要大量的经验来学习单个任务。虽然元强化学习(meta-RL)算法可以让智能体从少量经验中学习新技能,但一些主要的挑战阻碍了它们的实用性。目前的方法严重依赖于同策略经验,限制了它们的样本效率。在适应新任务时,它们也缺乏推理任务不确定性的机制,这限制了它们在稀疏奖励问题上的有效性。本文通过开发一种异策略元强化学习算法来解决这些挑战,所提算法(Probabilistic Embeddings for Actor-critic meta-RL, PEARL)将任务推理和控制分离开来。算法对潜在的任务变量进行在线概率滤波,从少量的经验中推断出如何解决新任务。这种概率解释使得后验采样能够用于结构化和高效的探索。论文证明了如何将这些任务变量与异策略强化学习算法集成,以实现元训练和自适应效率。所提方法在样本效率和在几个元强化学习基准上的渐近性能上都比以前的算法高出20-100倍。
1. 基础知识
1.1 传统的强化学习 vs 元强化学习 (Standard RL vs Meta-RL)

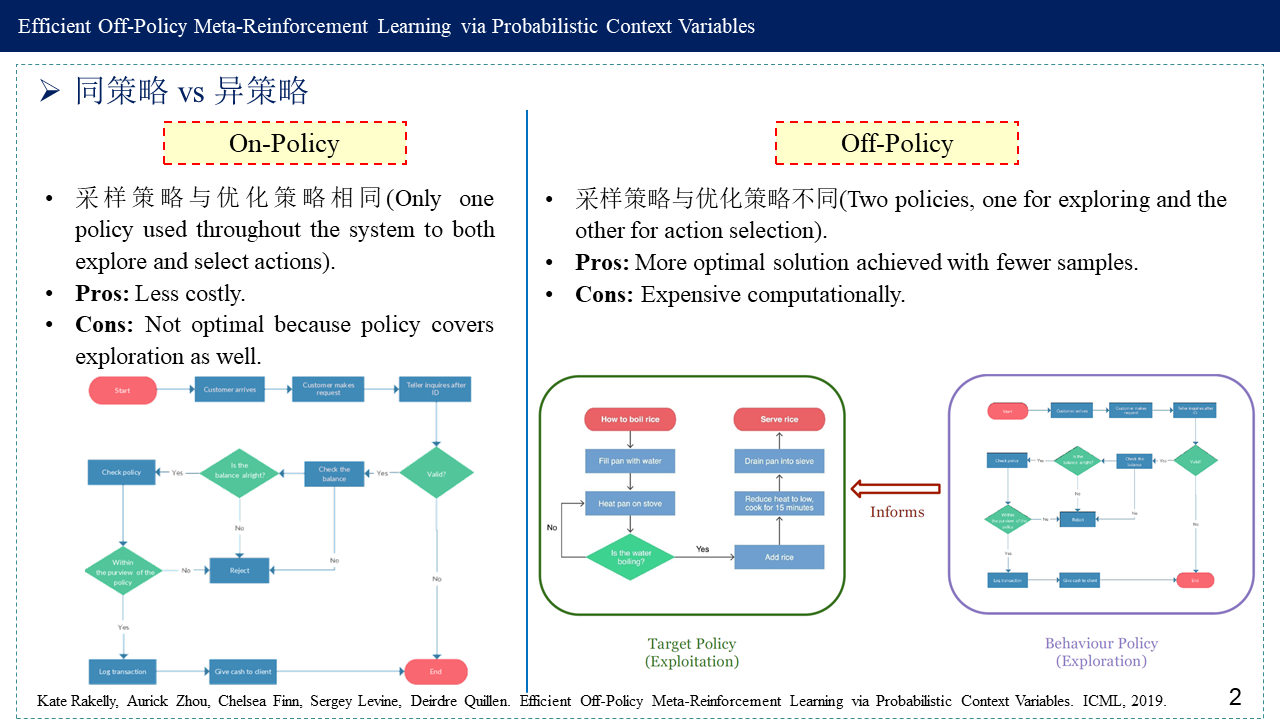
1.2 同策略 vs 异策略 (On-Policy vs Off-Policy)
1.3 软演员评论员算法(Soft Actor-Critic, SAC)

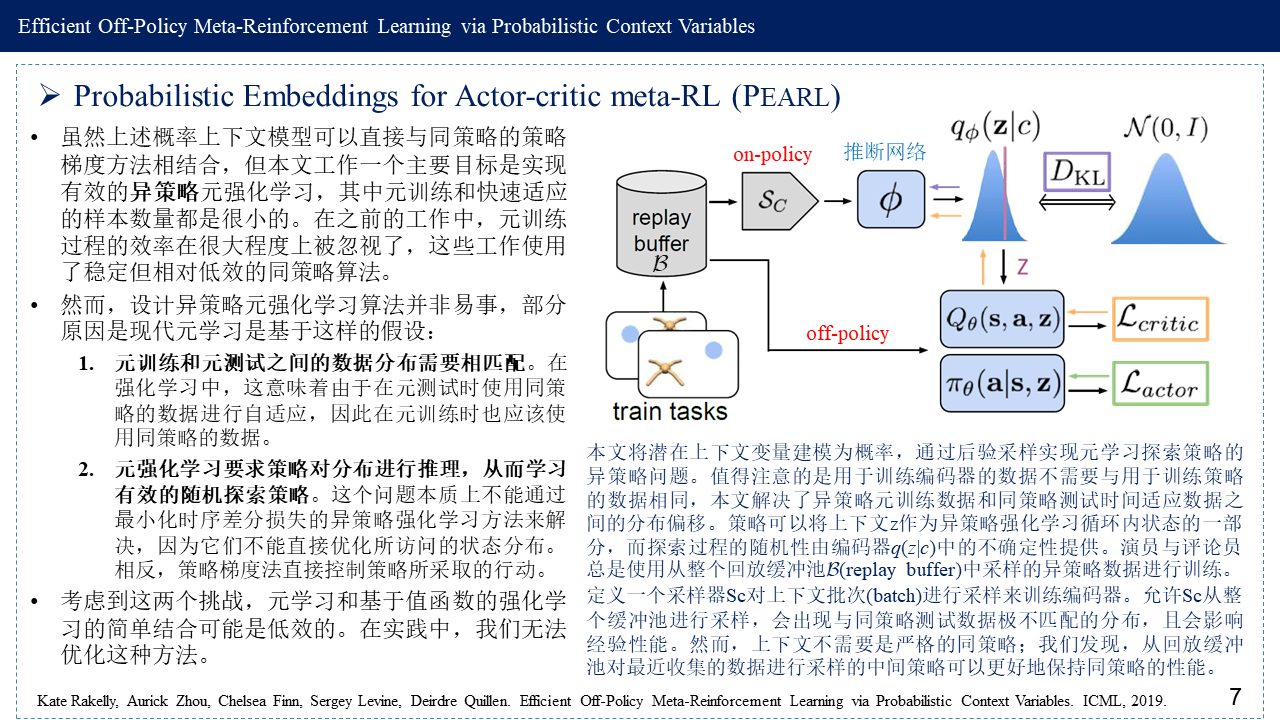
2. 概率潜在上下文 (Probabilistic Latent Context)



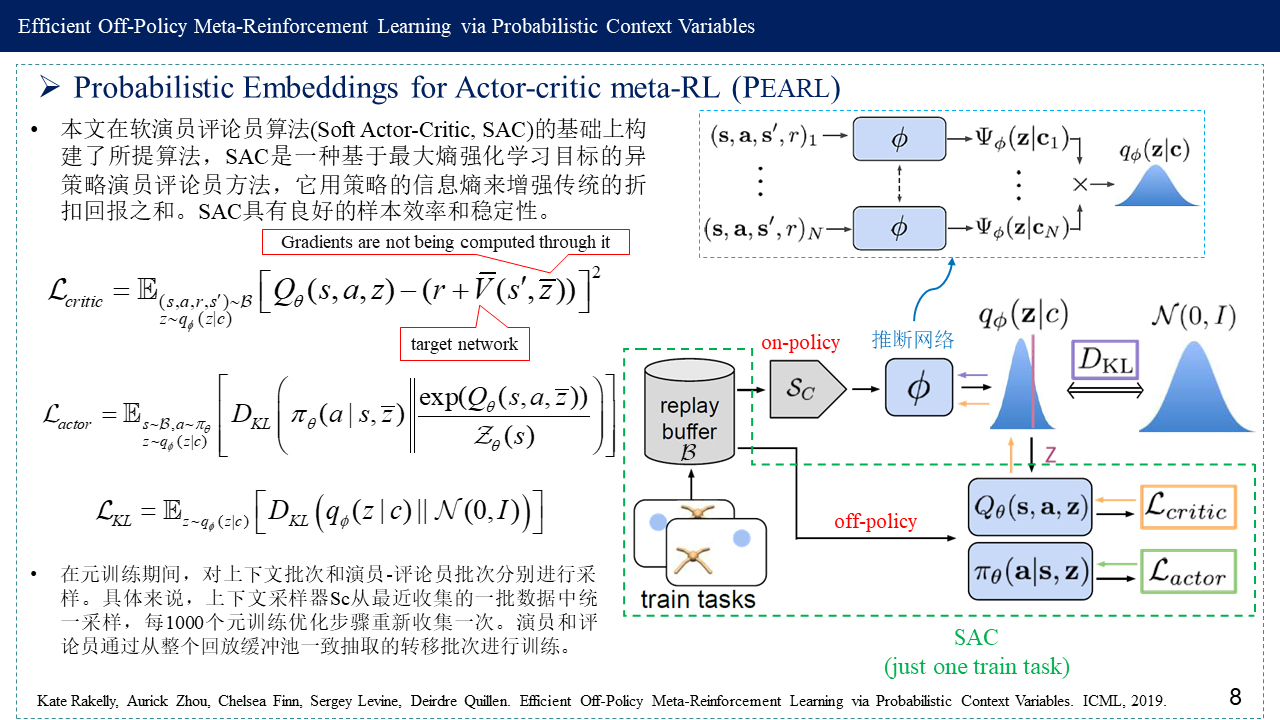
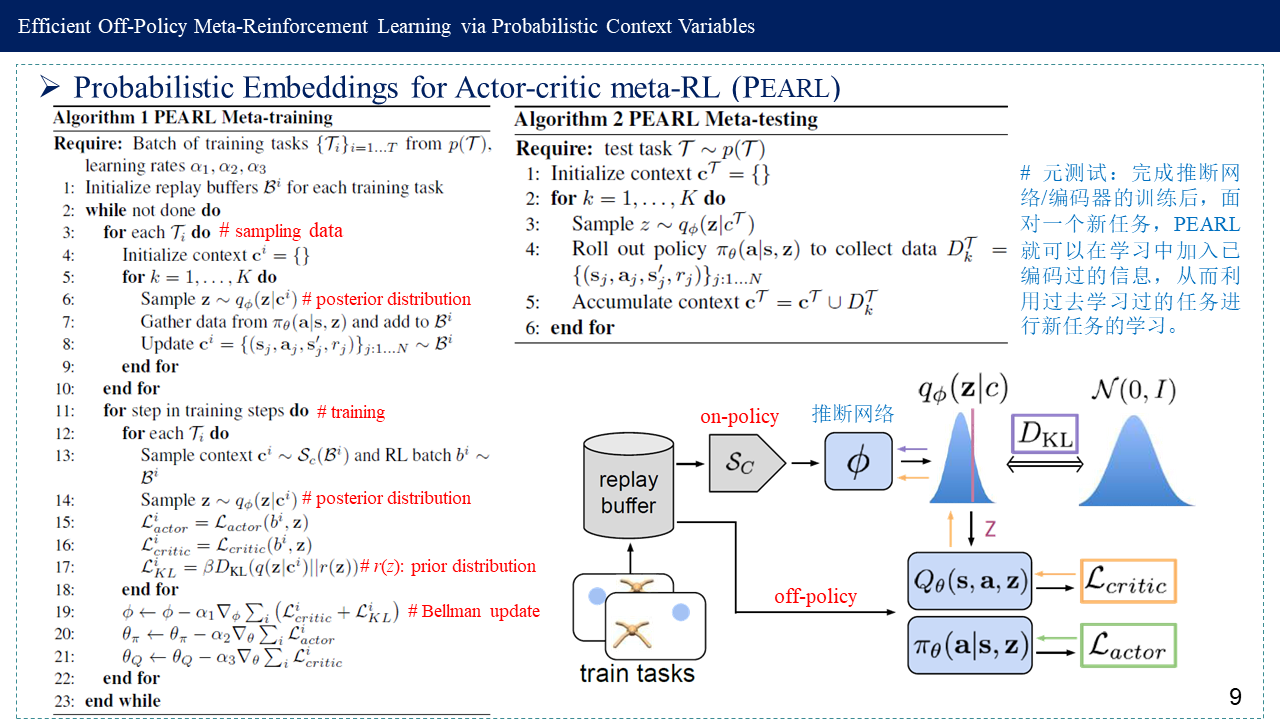
3. Probabilistic Embeddings for Actor-critic meta-RL (PEARL)
4. 参考文献
[1] Kate Rakelly, Aurick Zhou, Chelsea Finn, Sergey Levine, Deirdre Quillen. Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables. ICML, 2019.
Paper: http://proceedings.mlr.press/v97/rakelly19a.html
Code: https://github.com/katerakelly/oyster
Slides: https://icml.cc/media/Slides/icml/2019/hallb(12-11-00)-12-12-15-4607-efficient_off-p.pdf and https://cs.uwaterloo.ca/~ppoupart/teaching/cs885-spring20/slides/cs885-efficient-off-policy-meta-reinforcement-learning.pdf
Video: https://youtube.videoken.com/embed/D0UmVbbJxS8?tocitem=100
[2] CS285 Meta-Learning http://rail.eecs.berkeley.edu/deeprlcourse-fa20/static/slides/lec-22.pdf
[3] CS330 Meta-RL http://cs330.stanford.edu/fall2019/slides/Exploration%20in%20Meta-RL.pdf and https://web.stanford.edu/class/cs330/slides/cs330_metarl2_2021.pdf
[4] PEARL — Probabilistic Embedding for Actor-critic RL | Zero https://xlnwel.github.io/blog/reinforcement%20learning/PEARL/
[5] RL——Deep Reinforcement Learning amidst Continual/Lifelong Structured Non-Stationarity – 凯鲁嘎吉 – 博客园 https://www.cnblogs.com/kailugaji/p/15562366.html
[6] 变分推断与变分自编码器 – 凯鲁嘎吉 – 博客园 https://www.cnblogs.com/kailugaji/p/12463966.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号