
RL——Deep Reinforcement Learning amidst Continual/Lifelong Structured Non-Stationarity
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
这篇博客简要回顾论文“Deep Reinforcement Learning amidst Continual/Lifelong Structured Non-Stationarity”,并记录一下阅读笔记,大多数强化学习算法都用于求解无限阶段且平稳的马尔可夫决策过程(MDP),求解有限阶段非平稳的MDP的强化学习算法很少见到。论文主要研究求解有限时段非平稳的MDP的强化学习算法,这篇文章可理解为变分自编码器(VAE)框架下的软演员评论员(Soft Actor-Critic, SAC)异策略(off-policy)强化学习算法。看这篇博文的前提需要了解变分推断与变分自编码器(许多推导用到了变分推断的推导过程),强化学习中的演员-评论员算法。主要讲解有关变分推断的基础知识(涉及到贝叶斯公式),Jensen不等式(推导证据下界时用到),平均场理论(RL推导中涉及的因式分解用到这个变分理论),将强化学习形式化为变分推断问题,非平稳性形式化为概率模型,基于变分推断的联合表示和强化学习(对论文中的公式进行推导,其中,$L_{KL}$项与原文推导有些许出入,但无非是z采样问题,并无大碍),以及Lifelong Latent Actor-Critic (LILAC)算法流程。
作为人类,我们的目标和环境在我们的一生中不断变化,这是基于我们的经验、行动以及内在和外在的驱动力。相比之下,经典的强化学习问题设置考虑的决策过程是跨回合的平稳过程。我们能否提出一种强化学习算法来应对先前更现实的问题设置的持续变化?虽然同策略(on-policy)的算法,如策略梯度,在原则上可以扩展到非平稳设置,但更有效的异策略(off-policy)算法(在学习时回放过去的经验)却不能这样。这篇论文形式化了这个问题设置,并借鉴在线学习和概率推理文献的思想,得出了一个异策略强化学习算法,该算法可以推理和处理这种终身非平稳性。所提方法利用潜在变量模型从当前和过去的经验中学习环境的表示,并使用该表示执行异策略强化学习。论文进一步介绍了几个具有终生非平稳性的模拟环境,并根据经验发现,所提方法大大优于那些不考虑环境变化的方法。
1. 前提基础
包括参数估计、贝叶斯估计、变分推断、Jensen不等式、平均场理论,以及软演员评论员(Soft Actor-Critic, SAC)算法。



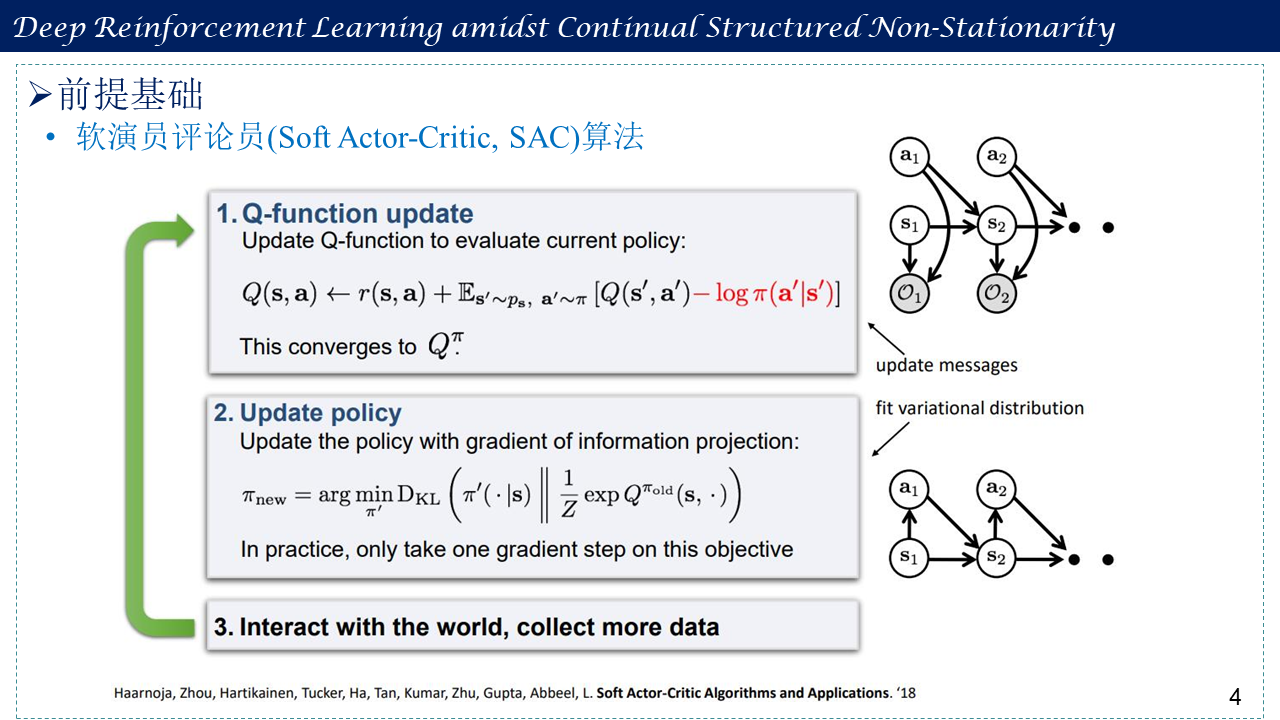
2. 强化学习作为变分推断

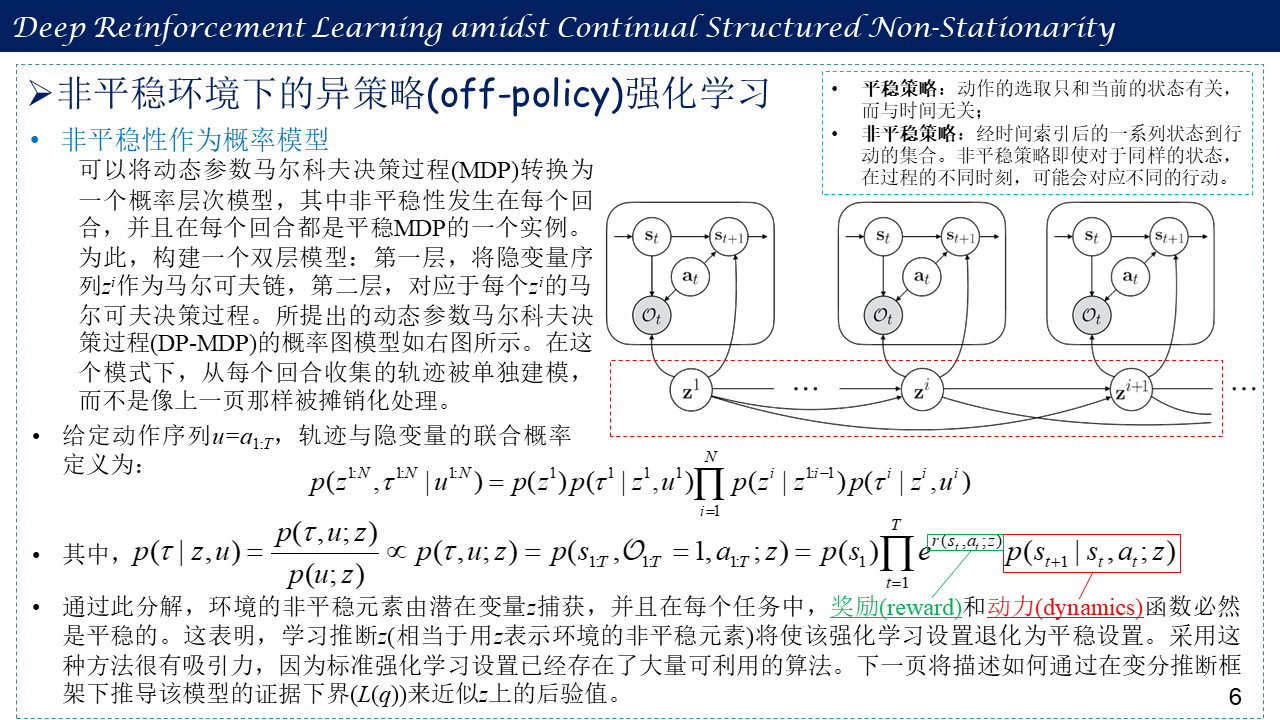
3. 非平稳环境下的异策略(off-policy)强化学习
包括非平稳性作为概率模型、基于变分推断的联合表示和强化学习,以及Lifelong Latent Actor-Critic (LILAC)算法流程。




4. 参考文献
[1] Annie Xie, James Harrison, Chelsea Finn. Deep Reinforcement Learning amidst Continual/Lifelong Structured Non-Stationarity. ICML, 2021.
Paper and Code: http://proceedings.mlr.press/v139/xie21c.html
Video: https://icml.cc/virtual/2021/spotlight/10468 or https://slideslive.com/38931572/deep-reinforcement-learning-amidst-lifelong-nonstationarity?ref=speaker-38044-latest or https://www.youtube.com/watch?v=FyKPO7LV06I
Experiments: https://sites.google.com/stanford.edu/lilac/
[2] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, Sergey Levine. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. ICML, 2018. http://proceedings.mlr.press/v80/haarnoja18b
