
近端策略优化算法(Proximal Policy Optimization Algorithms, PPO)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
这篇博文是Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. Advances in Neural Information Processing Systems, 2017.的阅读笔记,用来介绍PPO优化方法及其一些公式的推导。文中给出了三种优化方法,其中第三种是第一种的拓展,这两种使用广泛,第二种实验验证效果不好,但也是一个小技巧。阅读本文,需要事先了解信赖域策略优化(Trust Region Policy Optimization, TRPO),从Proximal这个词汇中,可以联想到一类涉及矩阵范数的优化问题中的软阈值算子(soft thresholding/shrinkage operator)以及图Lasso求逆协方差矩阵(Graphical Lasso for inverse covariance matrix)中使用近端梯度下降(Proximal Gradient Descent, PGD)求解Lasso问题。更多强化学习内容,请看:随笔分类 - Reinforcement Learning。
1. 前提知识
策略梯度法(Policy Gradient Methods)与信赖域策略优化(Trust Region Policy Optimization, TRPO)

由于TRPO使用了一个硬约束来计算策略梯度,因此很难选择一个在不同问题中都表现良好的单一约束值。
2. 方法一:Clipped Surrogate Objective
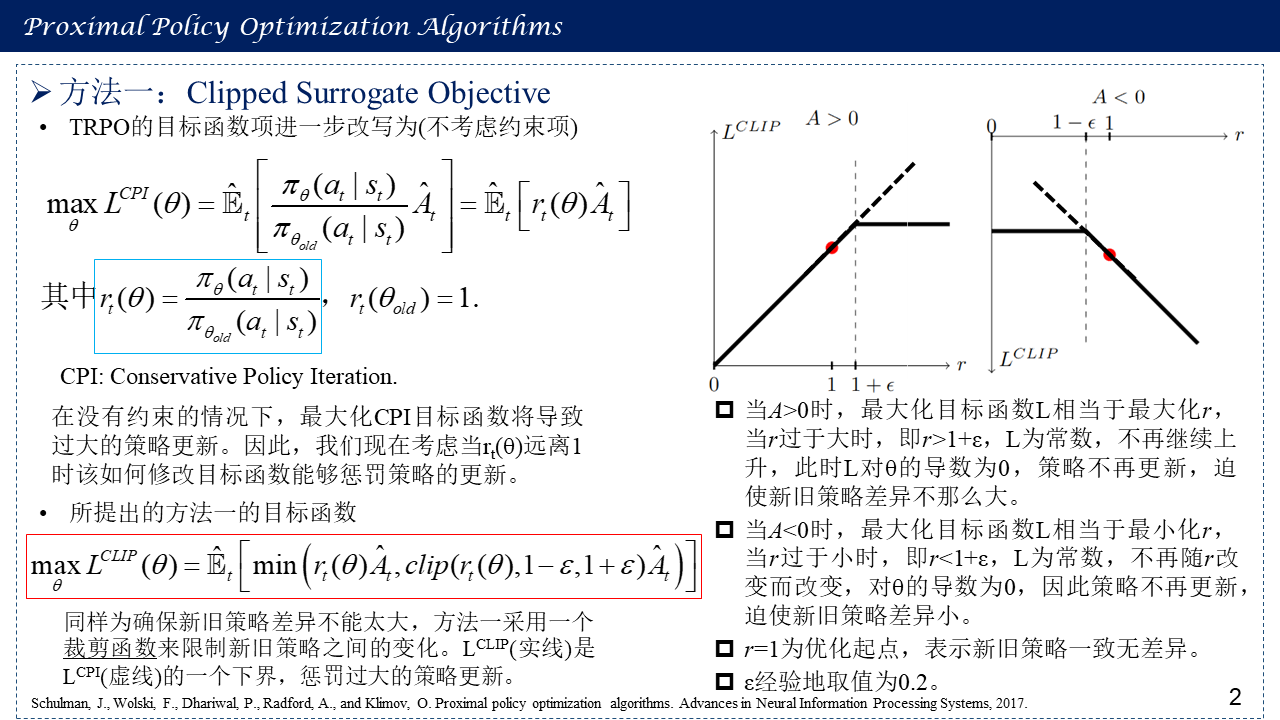

3. 方法二:Adaptive KL Penalty Coefficient

4. 方法三:Actor-Critic-Style Algorithm



5. 参考文献
[1] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. Advances in Neural Information Processing Systems, 2017.
[2] Proximal Policy Optimization — Spinning Up documentation https://spinningup.openai.com/en/latest/algorithms/ppo.html
[3] V. Mnih, A.Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, K. Kavukcuoglu. Asynchronous Methods for Deep Reinforcement Learning. ICML, 2016.
[4] Proximal Policy Optimization Algorithms, slides, https://dvl.in.tum.de/slides/automl-ss19/01_stadler_ppo.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号