
强化学习(Reinforcement Learning)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
通过阅读《神经网络与深度学习》及其他资料,了解强化学习(Reinforcement Learning)的基本知识,并介绍相关强化学习算法。更多强化学习内容,请看:随笔分类 - Reinforcement Learning。
1. 强化学习背景与基本概念
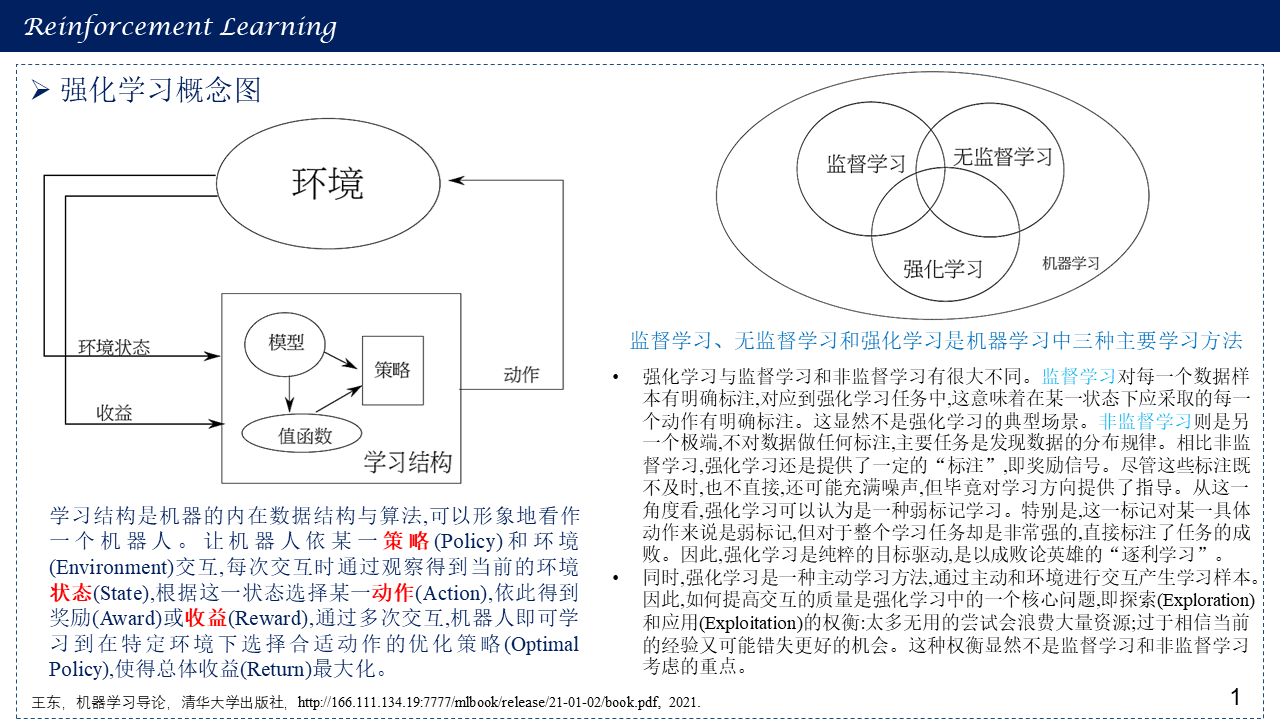
1.1 强化学习概念图
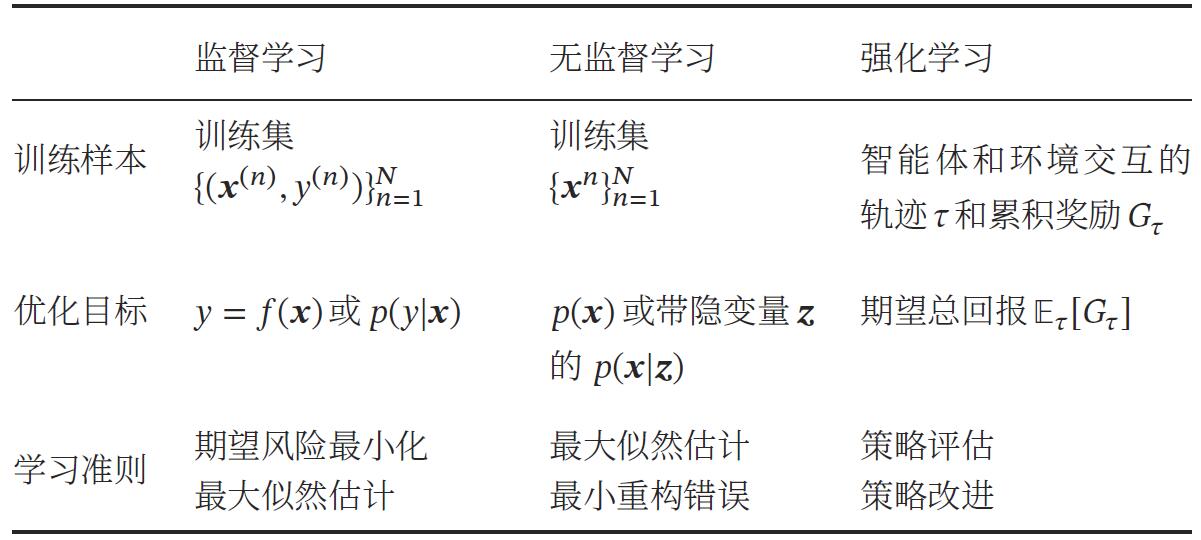
三种机器学习方法(监督学习,无监督学习与强化学习)比较:
1.2 基于学习信号的结构复杂度和时序复杂度对机器学习方法进行归类

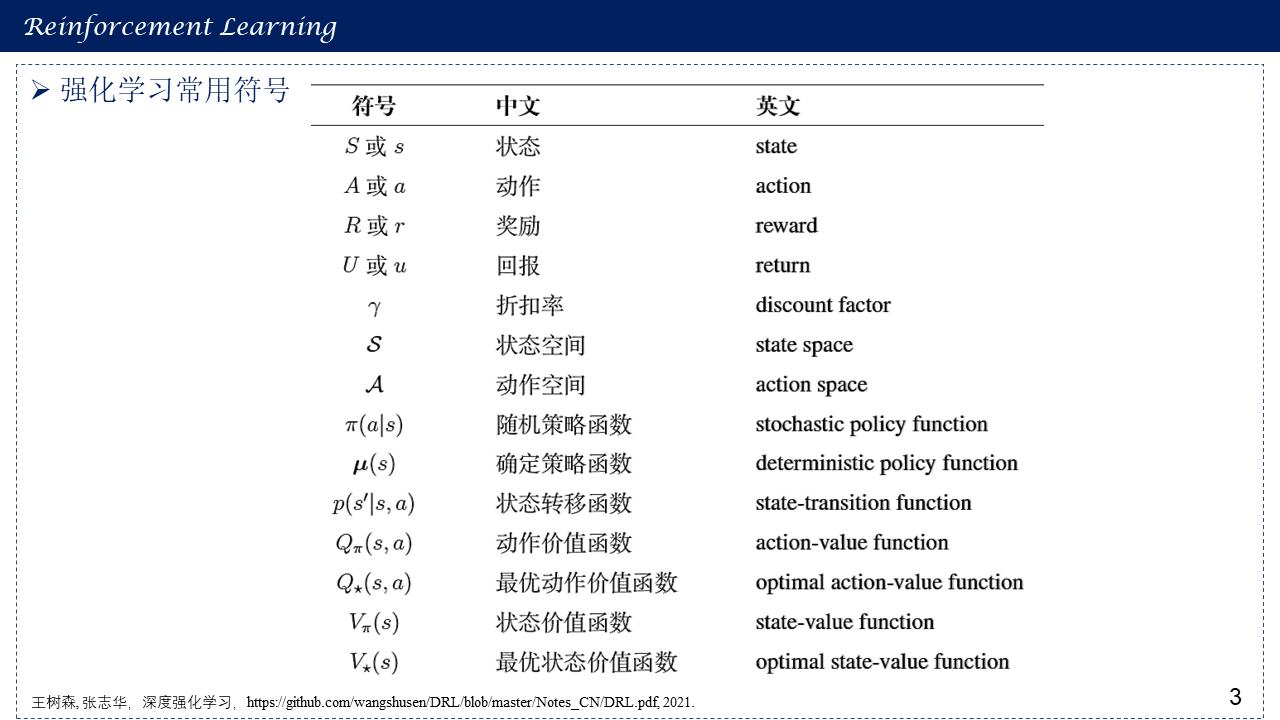
1.3 强化学习常用符号
1.4 强化学习定义与概念

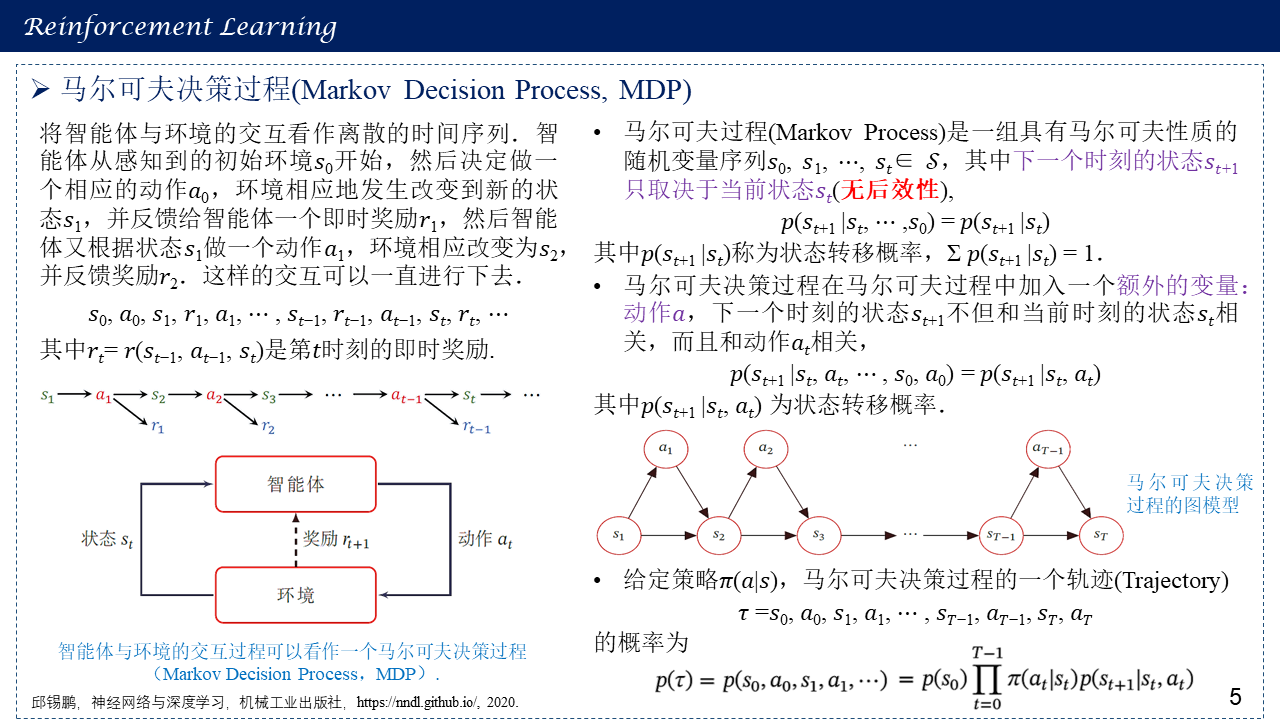
1.5 马尔可夫决策过程(Markov Decision Process, MDP)
|
|
不考虑动作 |
考虑动作 |
|
状态完全可见 |
马尔科夫链(MC) |
马尔可夫决策过程(MDP) |
|
状态不完全可见 |
隐马尔可夫模型(HMM) |
部分可观察马尔可夫决策过程(POMDP) |
1.6 强化学习的目标函数

1.7 值函数


动态规划方程/贝尔曼方程见:动态规划(Dynamic Programming, DP)
1.8 强化学习方法总体概括
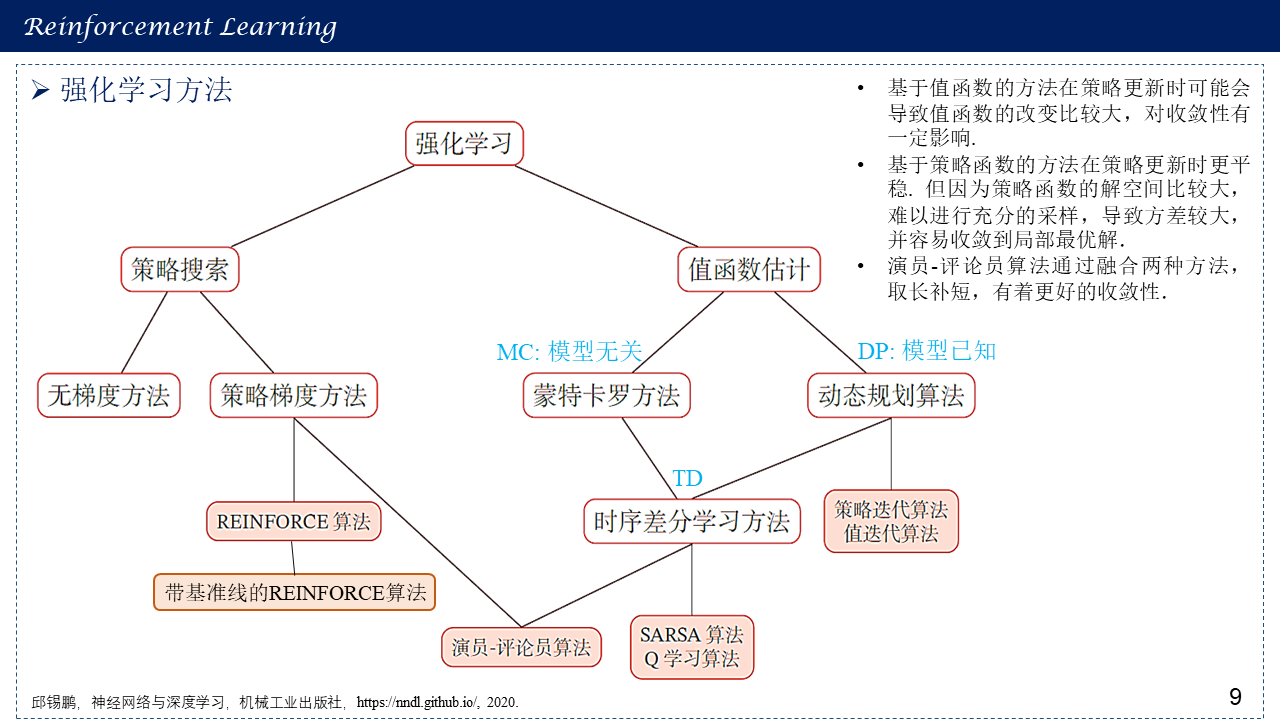
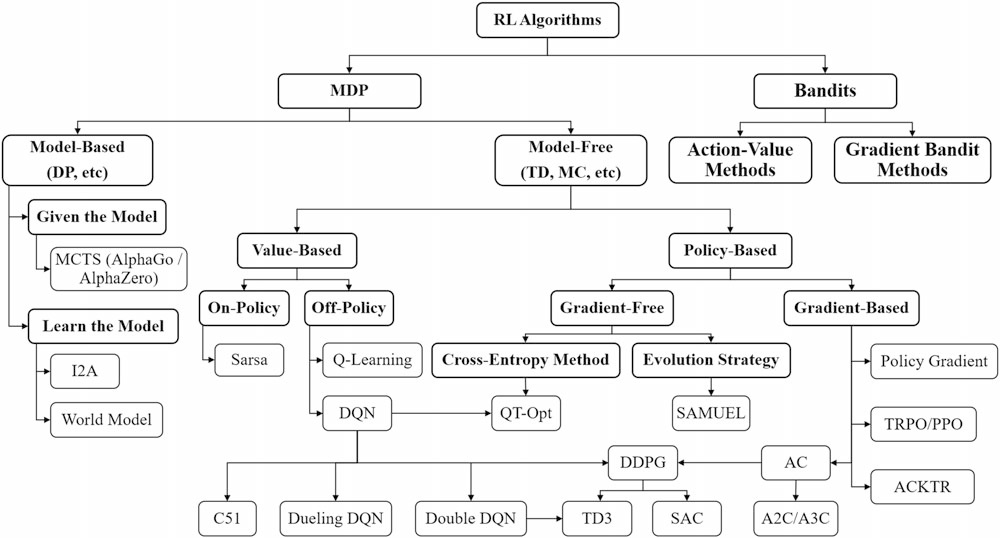

算法小结:
1. 值函数算法:通过迭代更新值函数来间接得到智能体的策略,当值函数迭代达到最优时,智能体的最优策略通过最优值函数得到。在算法应用的场景上,值函数算法需要对动作进行采样,因此只能处理离散动作的情况。
2. 策略梯度算法:直接采用函数近似的方法建立策略网络,通过策略网络选取动作得到奖励值,并沿梯度方向对策略网络参数进行优化,得到优化的策略最大化奖励值。在算法应用的场景上,策略梯度算法直接利用策略网络对动作进行搜索,可以被用来处理连续动作的情况。
3. 演员-评论员算法:将值函数算法和策略梯度算法结合得到的演员-评论员(Actor-Critic, AC)结构也受到了广泛的关注。在AC结构中,演员使用策略梯度法选取动作,通过值函数对演员采取的动作进行评价,并且在训练时,演员和评论员的参数交替更新。
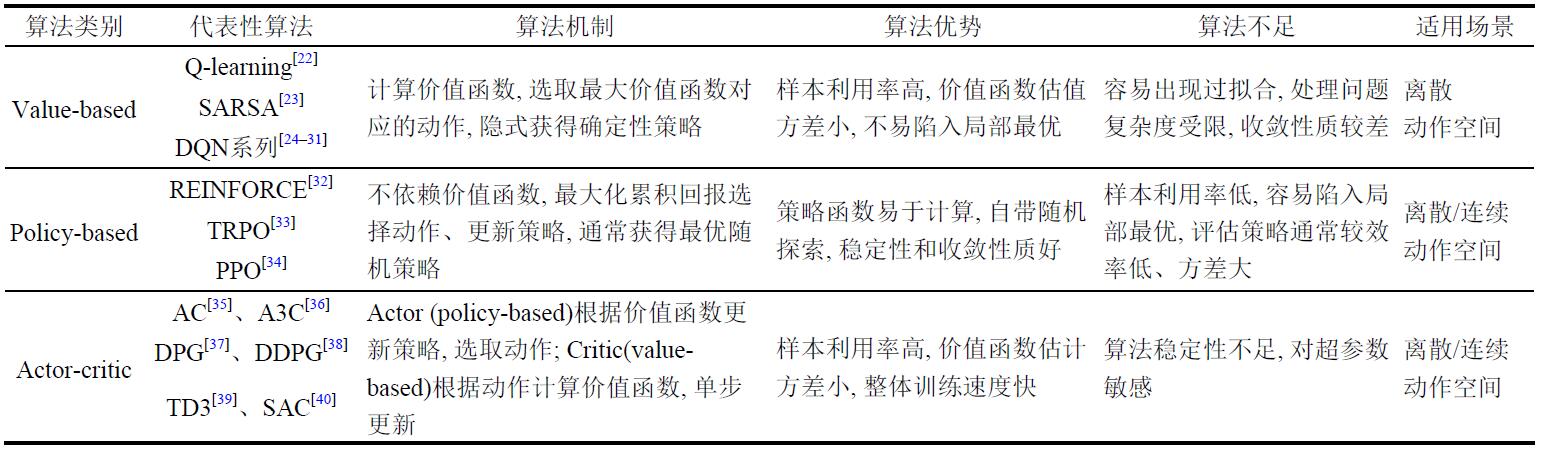
图源:李茹杨,彭慧民,李仁刚,赵坤.强化学习算法与应用综述.计算机系统应用,2020,29(12):13-25.

图源:深度强化学习:基础、研究与应用/ 董豪等著.—北京:电子工业出版社,2020.7
2. 基于值函数的方法
2.1 值函数估计——优化思路

2.2 动态规划算法(基于模型的强化学习)


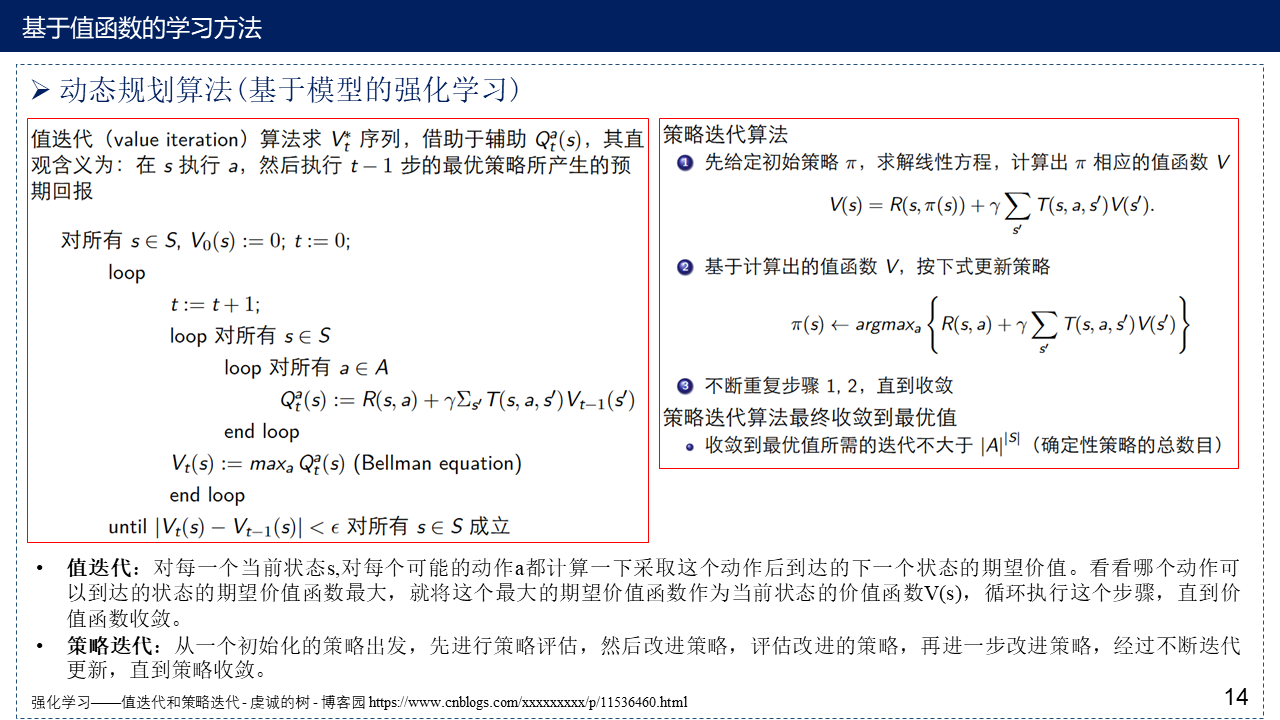
Python实现值迭代算法:Deep Reinforcement Learning Hands-On——Tabular Learning and the Bellman Equation
2.3 蒙特卡罗方法(模型无关的强化学习)


on-policy(同策略)与off-policy(异策略)的本质区别在于:更新Q值时所使用的方法是沿用既定的策略(on-policy)还是使用新策略(off-policy) 。
2.4 时序差分学习方法(蒙特卡罗+动态规划)

2.4.1 SARSA:一种同策略的时序差分学习算法

2.4.2 Q学习:一种异策略的时序差分学习算法

Q学习通常假设智能体贪婪地选择动作,即只选择Q值最大的动作,其他动作的选择概率为0,从而保证了Q学习的收敛性。与Sarsa相比,异策略Q学习需要更短的训练时间,跳出局部最优解的概率更大。然而,如果智能体根据Q值的概率模型而不是贪婪选择对动作进行采样,则采用异策略技术的Q值估计误差将增大。
Python实现Sarsa与Q学习算法:Hands-On Reinforcement Learning With Python——Temporal Difference Learning,Deep Reinforcement Learning Hands-On——Tabular Learning and the Bellman Equation
2.4.3 深度Q网络(Deep Q-Networks,DQN)


Python实现简易版的DQN(架构不是三卷积两全连接,简化为两全连接):Deep Reinforcement Learning Hands-On——Higher-Level RL Libraries (PTAN),Deep Reinforcement Learning Hands-On——Policy Gradients – an Alternative
Python完整版实现DQN:https://github.com/PacktPublishing/Deep-Reinforcement-Learning-Hands-On-Second-Edition/tree/master/Chapter08
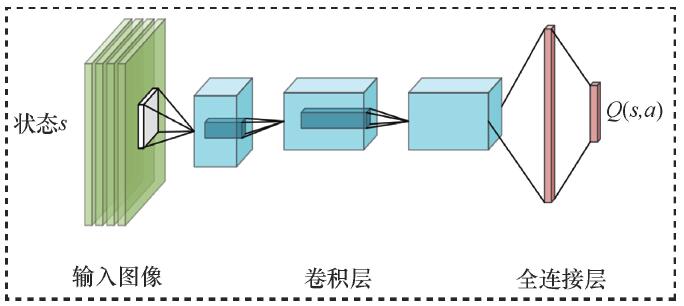
DQN网络结构:
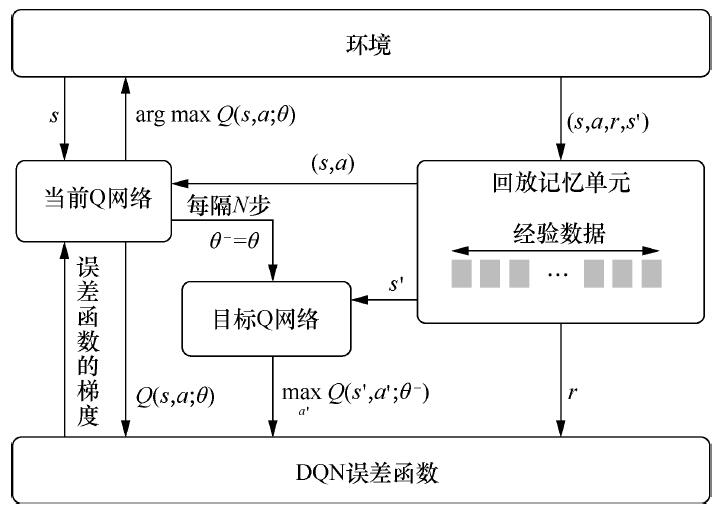
DQN(off-policy)算法流程:
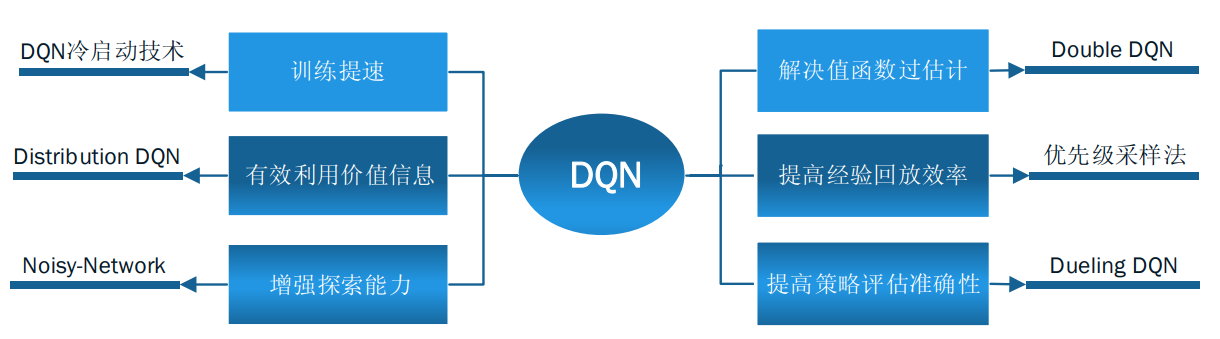
DQN算法改进:
Double DQN算法流程

图源:https://zhuanlan.zhihu.com/p/79712897
Dueling DQN 的网络结构

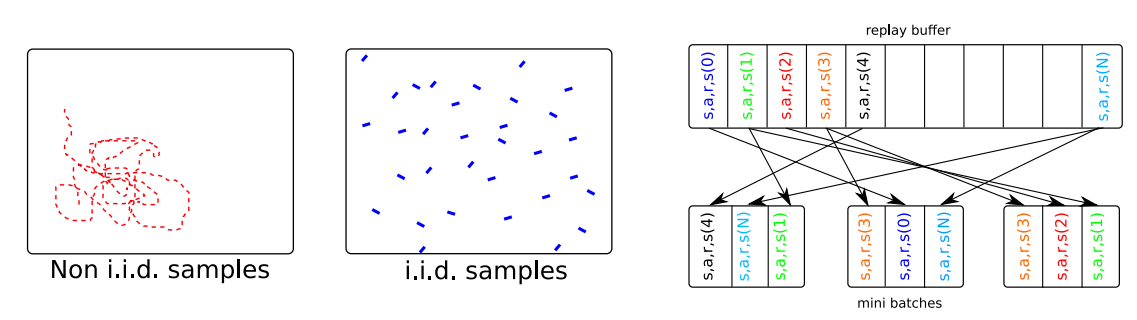
补充:为什么需要经验回放池(Experience Replay Buffer)?
1. 重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。重复利用经验、不重复利用经验的收敛曲线通常如下图所示。图的横轴是样本数量,纵轴是平均回报。

图来自:王树森, 张志华, 深度强化学习,https://github.com/wangshusen/DRL/blob/master/Notes_CN/DRL.pdf, 2021.
2. 采用神经网络训练时,一般需要进行基于梯度的优化,并对数据进行分批次训练,设立batch,但采用这种方式的前提是假设样本之间都是独立同分布的(independent and identically distributed,i.i.d.),这样每个batch内的噪声可以互相抵消。但强化学习中的决策过程是一个时间序列,这意味着前后数据之间具有很强的相关性,这样不利于进行梯度优化。设立经验回放池,将贝尔曼公式中需要的数据保存起来,通过随机的(或者基于优先度的)从经验回放池中进行抽样,当回放池中的数据足够多,随机抽样得到的数据就接近独立同分布,因此设立经验回放池可以打破序列之间的相关性,避免模型陷入局部最优。
图来自:From Policy Gradient to Actor-Critic methods https://rl-vs.github.io/rlvs2021/class-material/pg/6_baseline_AC.pdf
3. 基于策略函数的学习方法
3.1 策略梯度(Policy Gradient)

3.2 REINFORCE算法

3.3 带基准线的REINFORCE算法(REINFORCE with Baseline)


补充:策略梯度法改进思路
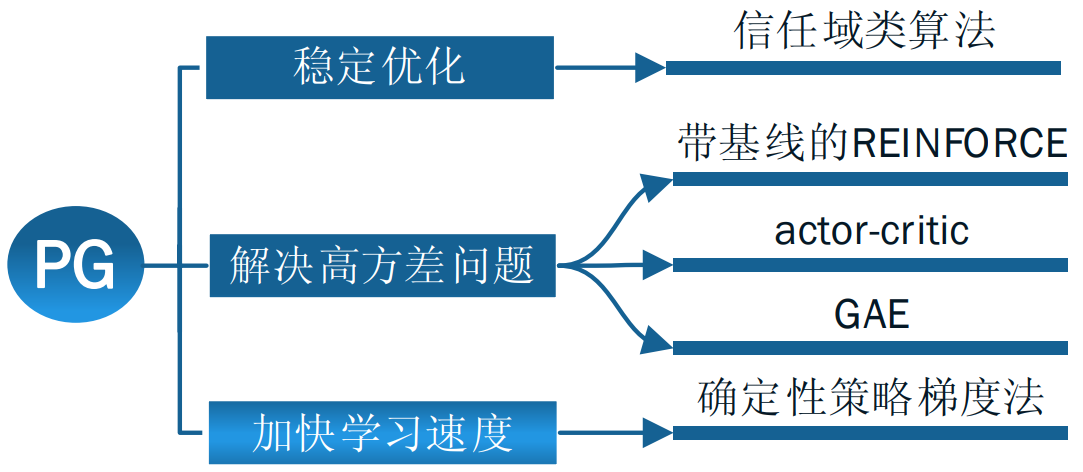
信任域类算法请看:信赖域策略优化(Trust Region Policy Optimization, TRPO),近端策略优化算法(Proximal Policy Optimization Algorithms, PPO),重要性采样(Importance Sampling)——TRPO与PPO的补充
Python实现基于策略函数的强化学习方法:Deep Reinforcement Learning Hands-On——Policy Gradients – an Alternative
4. 演员-评论员算法(Actor-Critic Algorithm)

A2C的基本结构:

A3C(on-policy)异步训练框架图:

Soft Actor-Critic:

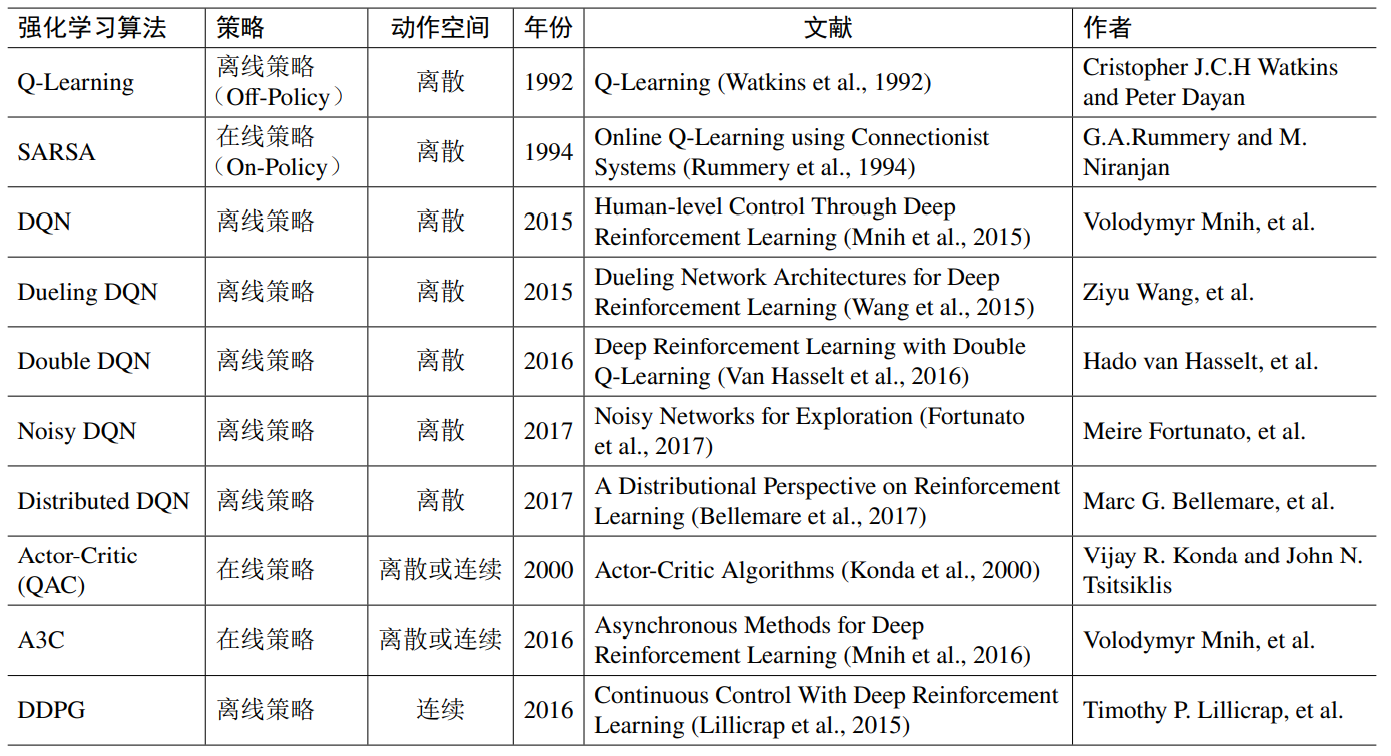
5. 深度强化学习算法分类与应用
5.1 算法分类

5.2 应用与意义

6. 基于模型的方法与定义奖励函数方法概述
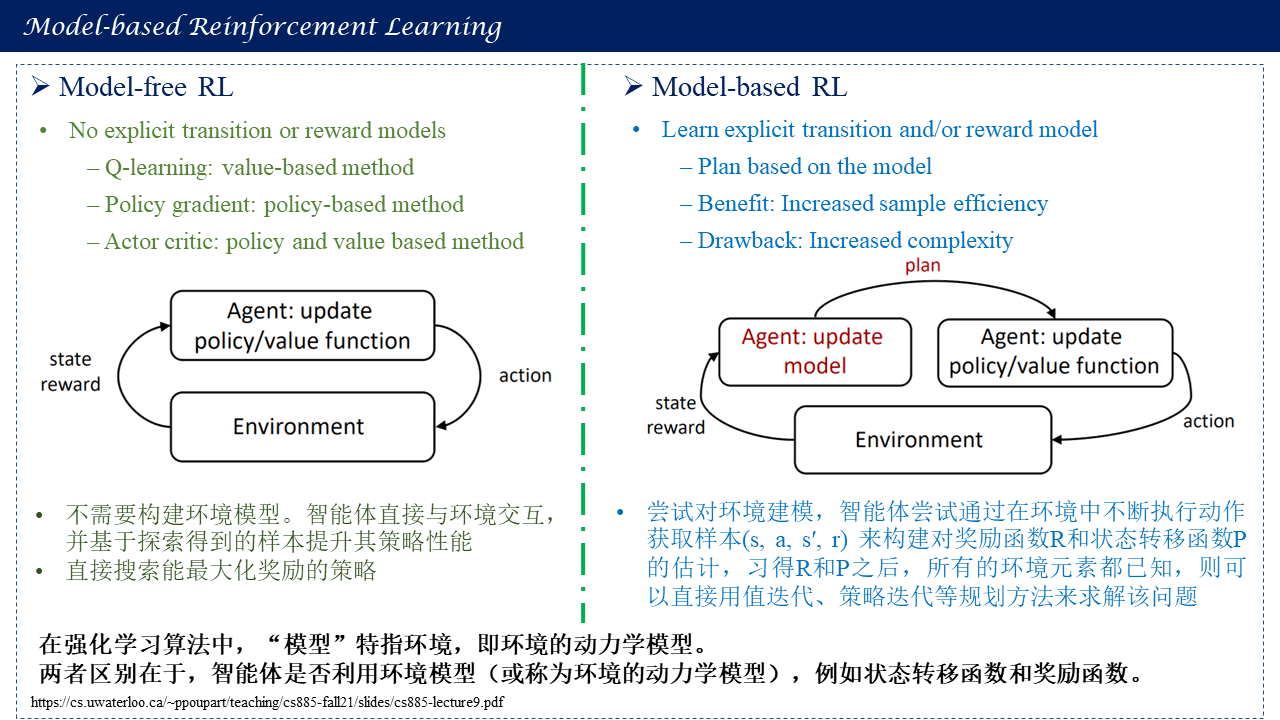
根据智能体是否通过与环境交互获得的,数据来预定义环境动态模型,将强化学习分为模型化强化学习(基于模型的强化学习)和无模型强化学习(与模型无关的强化学习),上述讨论的大多数为无模型强化学习(动态规划属于模型化强化学习)。

无模型的深度强化学习算法需要大量的采样数据进行训练,而这些数据往往很难通过交互得到,因此可以考虑使用已有的现实环境中的数据建立环境模型,然后利用环境模型对智能体进行训练。
Model-based RL vs Model-free RL
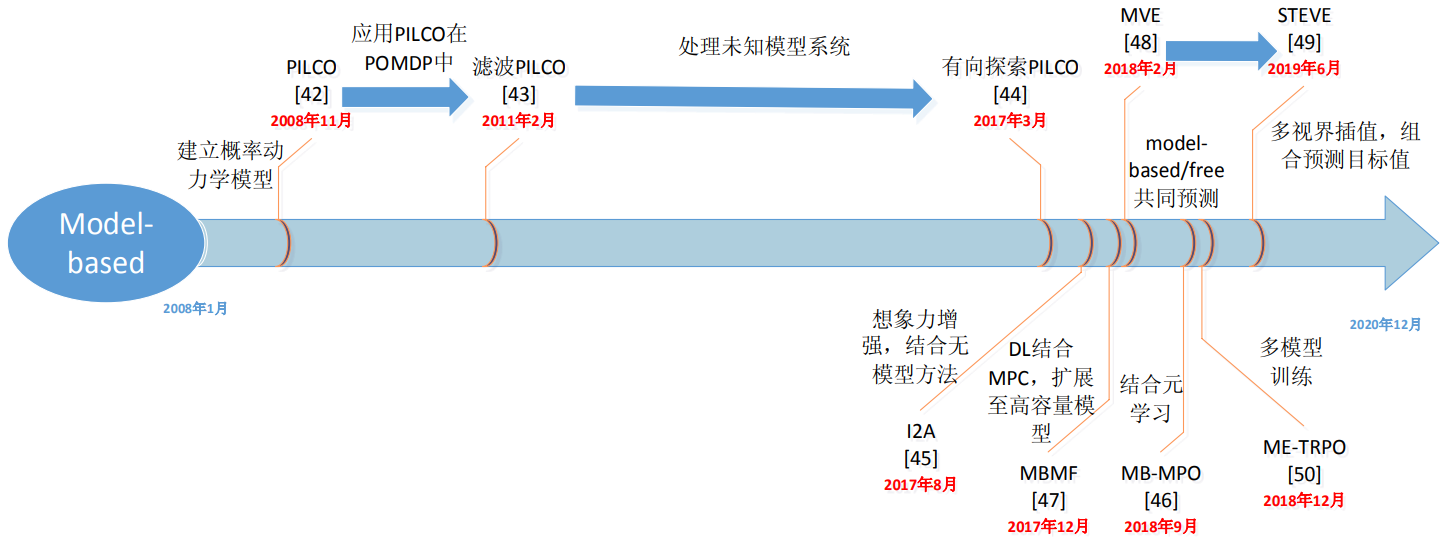
基于模型的强化学习:
定义奖励函数方法概述:
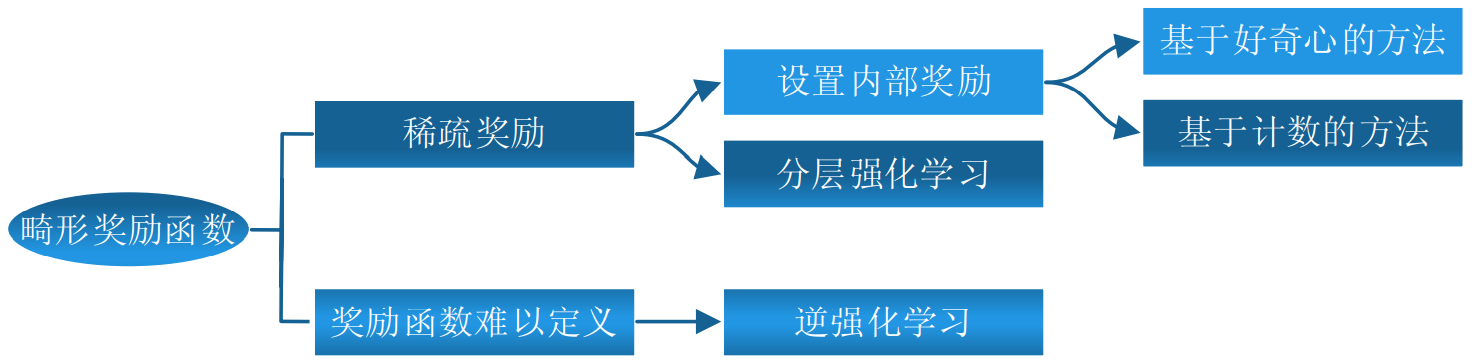
7. 强化学习前沿方向
- 元强化学习(Meta Reinforcement Learning):除改善一个具体任务上的学习效率外,研究人员也在寻求能够提高在不同任务上整体学习表现的方法,这与模型的通用性(Generality)和多面性(Versatility)相关。因此,我们会问,如何让智能体基于它所学习的旧任务来在新任务上更快地学习?因此有了元学习(Meta Learning)这一概念。元学习的最初目的是让智能体解决不同问题或掌握不同技能。然而,我们无法忍受它对每个任务都从头学习,尤其是用深度学习来拟合的时候。元学习,也称学会学习(Learn to Learn),是让智能体根据以往经验在新任务上更快学习的方法,而非将每个任务作为一个单独的任务。通常一个普通的学习者学习一个具体任务的过程被看作是元学习中的内循环(Inner-Loop)学习过程,而元学习者(Meta-Learner)可以通过一个外循环(Outer-Loop)学习过程来更新内循环学习者。这两种学习过程可以同时优化或者以一种迭代的方式进行。三个元学习的主要类别为循环模型(Recurrent Model)、度量学习(Metric Learning)和学习优化器(Optimizer)。结合元学习和强化学习,可以得到元强化学习(Meta Reinforcement Learning)方法。一种有效的元强化学习方法像与模型无关的元学习(Finn et al., 2017) 可以通过小样本学习(Few-Shot Learning)或者几步更新来解决一个简单的新任务。可参见:https://www.cnblogs.com/kailugaji/tag/Meta%20Learning/
- 离线强化学习(Offline Reinforcement Learning):智能体完全从静态的离线数据集中学习,而不进行探索。经验池中的离线数据由未知的行为策略(behaviour policy)产生,而离线强化学习希望利用该经验池中的这些来源未知的数据进行当前策略的学习和更新,并期望学到的策略可以在部署到交互环境中时可以有不错的表现。相关介绍详见:离线强化学习(A Survey on Offline Reinforcement Learning) - 凯鲁嘎吉 - 博客园
- 自监督强化学习(Self-Supervised Reinforcement Learning):学习一个观测的低维空间表示,即输入数据的压缩映射,能够有效解决直接用高维度数据学习控制策略中产生的维度灾难问题,有四种方式:
- 状态表征 (State Representation):对环境中的状态进行表征,提取状态中与学习任务相关的信息以提升例如值函数、策略函数在状态空间中学习效率,或提取与单学习任务无关而对多任务通用的信息使得在多任务的学习中迁移状态表征来泛化和加速。
- 动作表征 (Action Representation):对动作进行表征,压缩大的、高维的动作空间,约减探索和学习的采样开销。提取动作语义,表征动作空间的内在结构,提升函数在动作空间中的近似与泛化表现,提升学习的效果。
- 策略表征 (Policy Representation):对策略进行表征,使得值函数、策略影响的环境动态等在策略空间能够泛化,拓展强化学习算法的研究领域。压缩策略空间,提供策略表征空间策略优化的可能。提供分析策略学习、演进过程的方式。
- 任务/环境表征 (Task/Environment Representation):对强化学习学习任务和环境进行表征,在表征空间建立多任务、多环境的相似与区别,使得多任务、多环境的学习互相泛化和促进。
参考:
自监督强化学习 - 知乎专栏 https://www.zhihu.com/column/c_1424482085201932288
Jianye Hao, Self-supervised Reinforcement Learning, http://tcci.ccf.org.cn/conference/2021/dldoc/tutorial_6.pdf, NLPCC 2021 Tutorial.
【汽车学术沙龙】郝建业:自监督强化学习,https://www.bilibili.com/video/BV1YF411i7K3?spm_id_from=333.337.search-card.all.click
- 无监督强化学习(Unsupervised Reinforcement Learning):现有的强化学习方法都是有监督的,这使得智能体过度拟合特定的外在奖励,因此限制了算法的泛化能力。无监督强化学习与监督强化学习非常相似。两者都假设底层环境由马尔可夫决策过程(MDP)或部分可观测MDP描述,目的都是使奖励最大化。主要区别在于监督强化学习假设监督是由环境通过外部奖励提供的,而无监督强化学习通过自我监督任务定义内部奖励。与自然语言处理和机器视觉中的监督一样,监督奖励要么是由人工操作员设计的,要么作为标签提供,这些操作员很难扩展并将强化学习算法的泛化限制到特定任务。迄今为止已知的大多数无监督强化学习算法可以分为三类——基于知识的、基于数据的和基于能力的。基于知识的方法是最大化预测模型的预测误差或不确定性(例如 Curiosity、Disagreement、RND),基于数据的方法是最大化观察数据的多样性(例如 APT、ProtoRL),基于能力的方法使状态和一些通常被称为"skill"或"task"向量的潜在向量之间的互信息最大化(例如 DIAYN、SMM、APS)。具体参考:The Unsupervised Reinforcement Learning Benchmark, Misha Laskin and Denis Yarats

8. 参考文献
[1] 强化学习相关资料(书籍,课程,网址,笔记等) - 凯鲁嘎吉 博客园
[2] 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
[3] 强化学习——值迭代和策略迭代 - 虔诚的树 - 博客园 https://www.cnblogs.com/xxxxxxxxx/p/11536460.html
[4] 杨思明 , 单征 , 丁煜 , 李刚伟. 深度强化学习研究现状及展望[J]. 计算机工程, 2021, doi: 10.19678/j.issn.1000-3428.0061116.
[5] 刘朝阳, 穆朝絮, 孙长银. 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020, 2(4): 314-326.
[6] 秦智慧, 李宁, 刘晓彤, 刘秀磊, 佟强, 刘旭红. 无模型强化学习研究综述[J]. 计算机科学, 2021, 48(3): 180-187.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号