
一种数据选择偏差下的去相关聚类方法
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
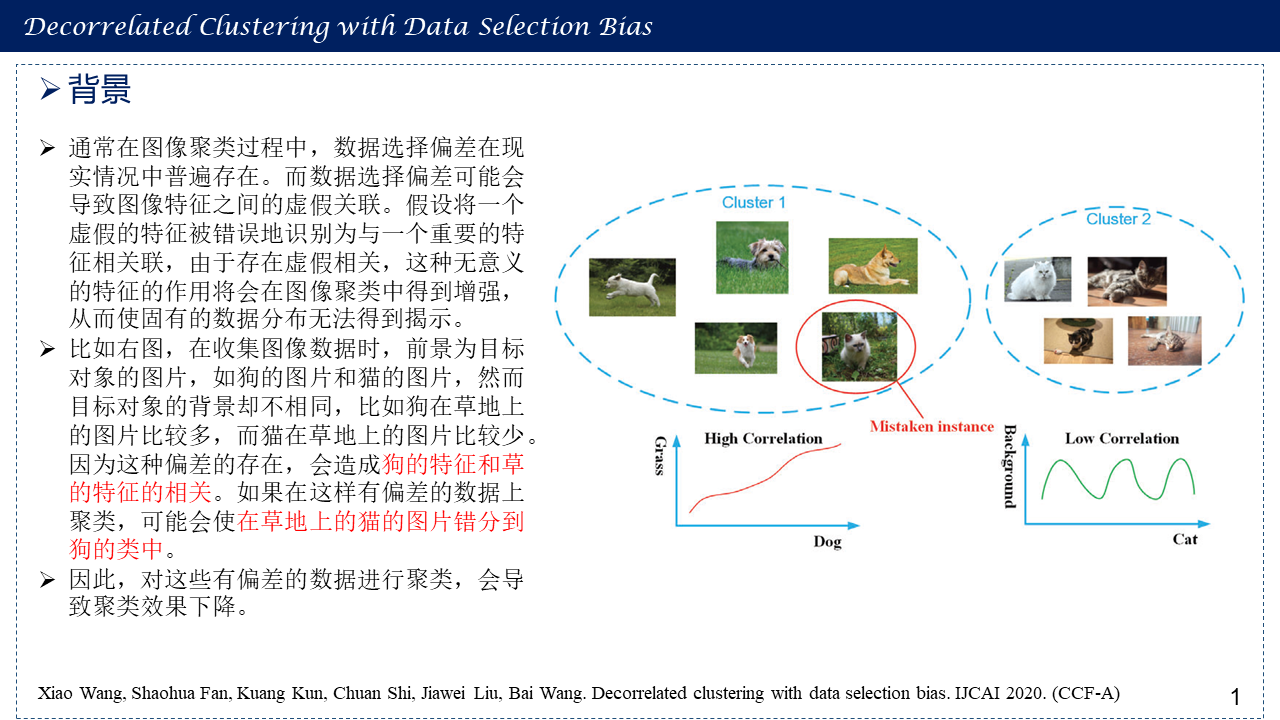
本博文是对Decorrelated clustering with data selection bias这篇文章的展开与叙述。现有的聚类算法大多没有考虑数据的选择偏差。然而,在许多实际应用中,人们不能保证数据是无偏的。选择偏差可能会导致特征之间产生意想不到的相关性,忽略这些意想不到的相关性会影响聚类算法的性能。因此,如何消除这些由选择偏差引起的非预期相关性是非常重要的,但在聚类过程中还没有被深入探讨。在本文中,提出了一种新的去相关正则化k -均值算法(DCKM),用于有数据选择偏差的聚类。具体来说,去相关正则化器的目的是学习能够平衡样本分布的全局样本权值,从而消除特征之间的非预期相关性。同时,将学习到的权值与k-means相结合,使重新加权后的k-means聚类对数据的固有分布没有非预期的相关性影响。此外,本文还推导出了更新规则,以有效地推断DCKM中的参数。在真实数据集上的大量实验结果很好地证明了DCKM算法获得了显著的性能提升,表明在聚类时需要去除由选择偏差引起的非预期特征关联。




参考文献:
[1] Xiao Wang, Shaohua Fan, Kuang Kun, Chuan Shi, Jiawei Liu, Bai Wang. Decorrelated clustering with data selection bias. IJCAI 2020. (CCF-A)
[2] 王啸, 石川, 范少华. 一种数据选择偏差下的去相关聚类方法及装置[发明专利], 申请号: 2020105917421.
王啸老师个人主页:https://wangxiaocs.github.io/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号