redis 架构的演进
单机、主从、集群
| 特性/配置 | Redis 主从复制 | Redis 哨兵 | Redis 集群 |
|---|---|---|---|
| 主要目的 | 数据备份与读写分离 | 高可用性和故障自动切换 | 高并发和数据分散处理 |
| 架构 | 一个主节点和多个从节点 | 监控主从结构并自动切换 | 多个主节点,数据分片 |
| 数据复制 | 主节点到从节点 | 监控并管理主从复制 | 每个主节点管理自己的数据集 |
| 故障转移机制 | 手动或哨兵自动切换 | 自动故障转移 | 自动处理节点故障 |
| 可伸缩性 | 有限,依赖主节点 | 为主从结构增加高可用性 | 高,因为数据分布式处理 |
| 使用场景 | 数据备份和读扩展 | 关键应用的高可用性 | 大规模应用的高性能需求 |
| 设置复杂度 | 相对简单 | 中等,需配置哨兵 | 复杂,需规划数据分区 |
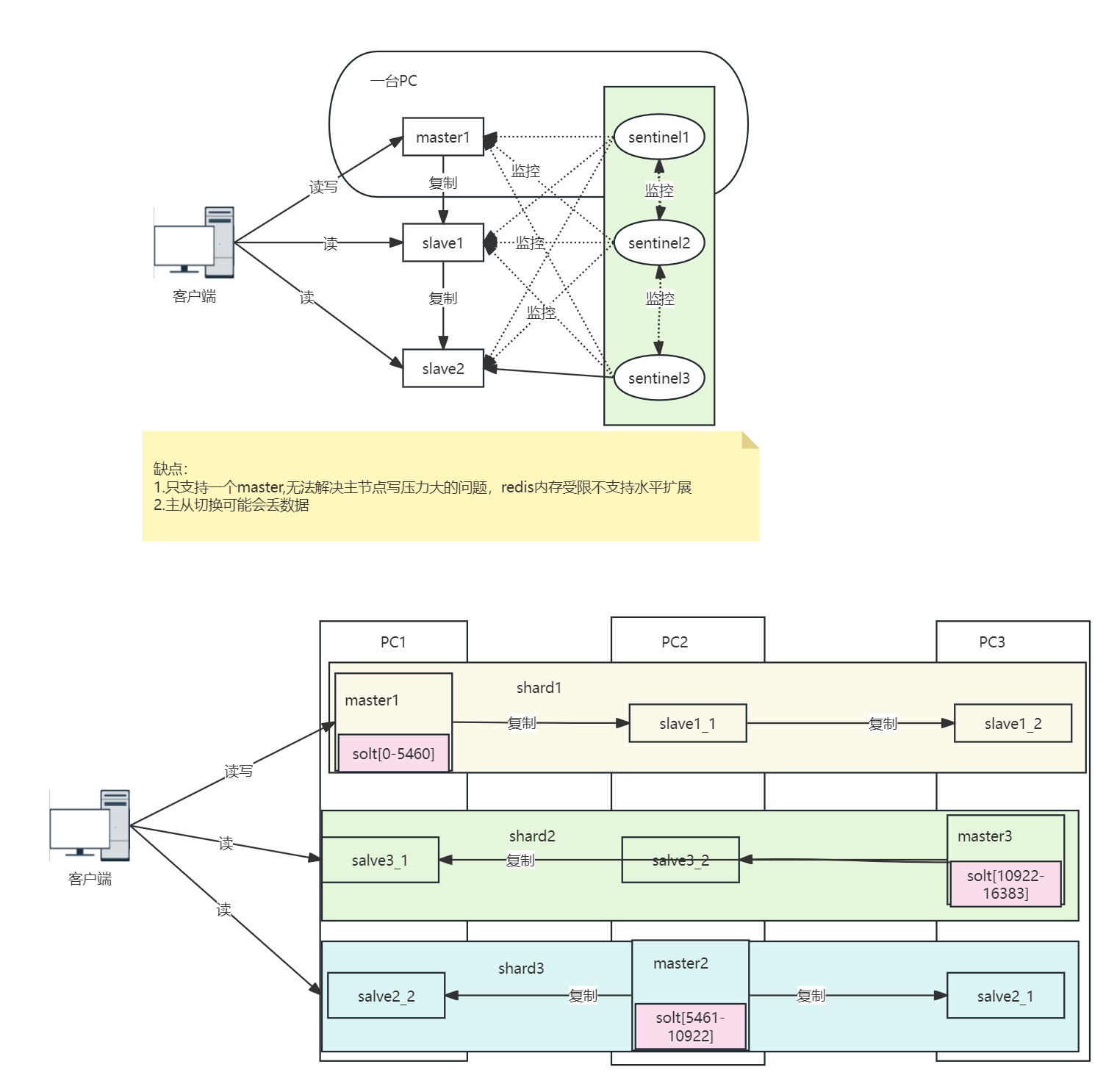
为了解决单机故障问题,redis引入了高可用架构,由多个redis结点组成redis集群,主节点挂了可以自动切换主节点。主流的高可用架构有以下几种
高可用架构
哨兵(高可用、只支持一个master)、cluster集群(高可用,高扩展)、proxy(第三方代理)
架构图
sentinel架构
sentinel是如何切换主库的?
sentinel实现主库切换主要有3大步骤:
监控——>决策——>通知
1、监控
每个sentinel会定时向各个结点发送ping命令。当sentinel1发现master在down_after_milillonseconds时间内没有回复,则认为mater主观下线了。
2、决策
master是否下线:当sentinel1发现master主观下线了就会询问其他sentinel,当超过一半的sentinel认为master主管下线了,master就会被认为是客观下线了。
选择新的master: 当master进入主观下线后,sentinel leader会在slave中选出新的mater。

3、通知
当哨兵做好决策后,需要通知其他slave和客户端新的主节点
sentinel架构下各个结点是如何建立连接的的?
sentinel redis集群架构主要包括3个角色:sentinels、master、slaves(一组sentinel可以监控多个redis集群)

每个sentinel启动会配置要监控的主节点:sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel可以是一个或者多个,但是为了高可用一般都设置为多个且为奇数个。多个sentinel节点通过向主节点pub自己的信息sub _sentinel_:hello信息感知到彼此并建立连接。每个sentinel获取到master信息对其进行监控。
主节点切换后如何通知客户端
sentinel leader发送sub消息switch-master,客户端jedis通过sbuscribe订阅此消息重新设置客户端主节点。
主观下线如何升级为客观下线
当某个哨兵链接master超时时,自己会主观认为该master下线了,但是由于网络波动等其他因素也不能过于武断。就会去问其他同僚的意见:is_master_down_by_addr?其他的sentinel会根据自身的链接情况回复Y/N,当quorum个sentinel主观认为master下线并同步信息后就会认为master已经失去连接了,客观下线了。这个时候就要选举sentinel leader,进行master切换了。
如何选举sentinel leader
如果只有一个snetinel不存在这个问题,当然可用性也不行,一般都是sentinel集群,至少3个sentinel节点,我们讨论集群情况下。
当sentinel集群认为master已经客观下线后,就要进行master切换等处理,可是谁来处理?总不能群龙无首18个儿子乱当家。这时候就需要选择一个sentinel作为leader,让他去负责后续工作。
怎么选?
首先肯定要那个节点认同master已经下线才行。所以只有发起master下线投票的节点能成为候选人,
sentinel会先给自己投一票,
再去找别人给他投,最终得到票数超过quorum的sentinel为leader,
当然也有可能进行一轮没有选举出来,(比如不同节点设置的超时时间不同,这边已经发起选举了,有的节点还认为原先的master没有失联),
就会进行第二轮选举。需要等上2倍的down_after_milillonseconds才可以。因此合理设置down_after_milillonseconds显得尤为重要。(一般30s左右?根据子自己的实际情况,能接受的响应时间,误判的概率等进行调整。)
sentinel的优缺点
sentinel解决了redis故障自动转移的问题,提升了redis的可用性。
但是sentinel集群模式下,只能有一个master,redis的水平扩容变得困难,由于只能再master写操作,写性能难以提升。
redis cluster也就应运而生。
redis cluster
redis cluster的特点
去中心化,redis cluster通过多master数据分片技术,方便集群的水平扩展和高并发读写的支持,自身通过gossip协议进行相互监控和选主切换,不再需要额外部署sentinel集群。
redis cluster数据分片引入了人分片规则,数据迁移等诸多问题。但是redis cluster已经一一解决。
master节点和slave节点的分工------->master:读写,salve:读
分布式寻址算法
hash、一致性hash、hash solt(Redis Cluster:范围+hash,16384个槽,
CRC16(key)%16383——>(redis server)solt(自己/转发给负责该solt的node)——>node)
| 算法名称 | 原理 | 优缺点 |
| hash取模 | hash(key)% 节点数 |
简单,不均匀, 可用性低,有服务宕机,落在这个node的请求失败 伸缩性差,不好扩容缩容 |
| 一致性hash |
hash(node ip)->hash环->增加虚拟节点->更均匀 hash(key)%node ip ->沿着圆环顺时针寻找第一个真实node |
分布可能不够均匀,可以通过增加虚拟节点解决, 有服务宕机她上面的请求会顺时针往后走落在下一个node, 增加节点也是落在下一个节点的一部分落在新增节点上 |
| hash solt |
slot = CRC16(key)& 16384 key 与solt绑定 solt与node映射关系 |
伸缩性好,可以自动平均分配solt也可以手动指定 |
主从之间的solt怎么保持一致?
solt只在主节点分配,从节点不分配solt,从节点升位master后会继承原master的solt
选举过程不用slave参与
redis cluster的选举过程不用salve参与
具体选举过程

rediscluster 扩容缩容
扩容:
增加一个节点,加入集群
分配solt,可以使用balance命令或者手动指定move solt
客户端jedis订阅相关事件更新本地缓存
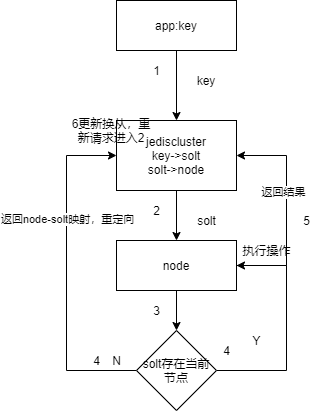
redis cluster请求流程
jedisCluster.set("a","a"); byte[] as = SafeEncoder.encode("a"); //获取key对应的slot int slot = JedisClusterCRC16.getSlot("a"); //使用slot获取key所在的节点 int port = jedisCluster.getConnectionFromSlot(slot).getClient().getPort();
redis脑裂问题
Redis的脑裂问题是什么?怎么造成的?会造成什么后果?
redis是如何解决脑裂问题的?
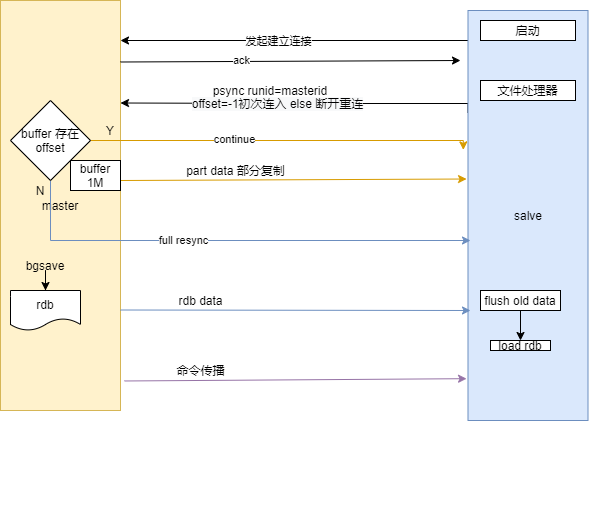
主从复制过程