redis是什么?为什么使用?
基于内存的,k,v形式非关系型数据库,单机可支持十万tps。为什么使用?解决并发、性能问题,弥补关系型数据库的不足。
redis的特点?
1.高可用架构
2.高性能
3.支持持久化
4.支持多种数据结构
5.支持pub/sub消息模式
6.支持多种语言
7.原子操作,所有操作都是原子操作,支持事务
redis为什么那么快?
1.redis基于内存操作
2.单线程模型避免上下文切换
3.IO多路复用网络模型提升网络请求处理能力
4.优秀的底层数据结构设计,SDS动态数组、跳表等
redis的线程模型
redis是单线程模型操作的,在6.0之后网络IO层面曾家了工作线程,但是对于指令的执行过程仍是mian线程在处理,因为不会出现线程安全问题和上下文切换的开销。另外redis有一些后台线程单独处理一些操作,例如bgsave等。
如何正确使用redis?场景数据结构的选择,高可用架构,异常问题处理。还会造成双写不一致问题。
如何正确使用:结合业务场景、选择合适的架构和数据结构。注意避免异常问题和数据库双写一致问题。
在redis的实际使用中,我们要注意根据不同应用场景选择合适的数据类型,根据缓存的数据量、并发情况以及业务场景选择合适架构,在对可用性较高要求的场景要使用集群架构比如cluster,还有通过多级缓存、布隆过滤器、过期时间等方式防止缓存雪崩、击穿、穿透等问题,另外高一致性要求的场景注意缓存数据库双写一致性问题。
根据应用场景选择数据类型的例子:
1.在保存拥有多个属性的对象时,我们可以选择hash架构来保存。这样既不用保存一个string时进行json序列化和反序列化浪费时间,也不用分开多个属性保存浪费空间。
2.保存员工打卡bitmap、统计pvhyperloglog、排序或者延时队列用sortset、共同好友用set等。
最终目的就是节省内存空间、易操作节省时间。
基本的数据类型底层可能对应着多种数据结构。这也是redis快的原因之一。
redis的数据类型
redis的基本数据类型有5种:
string、hash、list、set、sort set
每种数据类型底层设计不同的数据结构
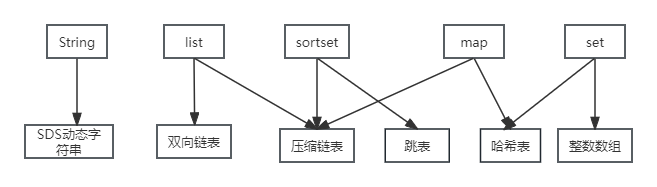
这种设计会让redis的操作能快,更节约内存
quicklist 3.2引入,取代linklist和ziplist,由这两者结合组成。
rehash
字典结构内部都有两个hashtable组成,其中一个有数据,扩容时 ,渐进式地将hashtable0上的数据rehash到另一个hashtable1,全部迁移完成后hashtable1取代hashtable0
3大并发问题:
主要取决于数据库的情况,雪崩最严重,会导致db崩溃;击穿是击穿的缓存,但数据库能查到;穿透是数据不存在,数据库也查不到,就是穿透了。
缓存雪崩
-大量key同时过期/缓存服务不能提供服务导致大量请求直接打到数据库,最终使得数据库崩溃整个应用崩溃
缓存雪崩是最严重的情况,解决方案:
原因可能有3个方面,1.缓存服务可用性方面、2.数据层面(过期时间)、3.请求没有经过缓存直接到数据库,导致数据库层面避免过多请求 最终导致数据库崩溃
提高的缓存服务的可用性:使用redis高可用架构,eg.redis cluster,使用多级缓存,降低对redis的依赖,例如使用guava本地缓存
过期时间解决:避免大量key同时过期或者热点key过期造成的db压力过大,可以为key设置均匀的过期时间,或者热点key不过期
1.使用高可用架构防止缓存服务不可用(redis cluster)。
2.增加本地缓存(guava):
由此引发问题?如何保证本地缓存(guava)和分布式缓存(redis)一致?
消息队列+较短的过期时间兜底
消息队列:redis,缺点redispub/sub不是很可靠不一定能删除。消息中间件,增加系统复杂度。
我们之前的做法,删除本地,根据查询条件hash,取模到固定节点。但是也有很多缺点。
如果让我选,会选择订阅redis删除队列消息,加上较短过期时间
3.避免key同时大量过期
可以为key设置均匀的过期时间,或者热点key不过期
4.熔断降级:
可以使用熔断器做熔断处理,当db压力过大时,切断对db的继续请求,也可以使用降级方案,fallback做一些退让操作
缓存击穿
-高并发请求无缓存的热点key(热点key不存在,请求直接击穿缓存打到数据库,数据预热,热点key不过期,监控热点锁并续期,加锁更新缓存)
缓存穿透
-数据库也查不到(代码bug/黑客攻击,设置null值,布隆过滤器)
双写一致性问题解决方案:
一致性并发不是很高的情况下处理方式:
读:读缓存->无->读数据库->更新缓存->返回
写:删除缓存->成功-->写数据库-->返回 (为啥是删除而不是更新,因为更新的话需要查询计算,复杂,影响更新效率,增加复杂度,lazy思想)
高并发情况下上述方案存在双写不一致问题
eg. 写操作删除缓存成功正要写数据库,数据库目前还是旧数据,此时,读请求处理,读到数据库的旧数据,并更新到缓存,然后写数据成功。此时,数据库缓存数据不一致。
解决方案:
将对同一条数据的操作路由到同一个服务。
写操作进入jvm队列,此时如果收到读请求也加入队列(优化点,相连的读请求有一条就可以了),由一个工作线程串行执行写读操作。
注意请求超时处理,可以通过增加服务。 另外热点数据问题,都路由到同一服务器,负载过大。
本人想到的解决方案:
写操作:加分布式锁
读操作:读缓存->无->获取读缓存分布式锁->读数据库->有->获取写分布式锁->成功->更新缓存/失败->不更新缓存。只尝试一次,不等待。
redis内存不足怎么解决?
1.单节点扩容,修改conf maxmemory/set maxmemory命令增大内存。不过可能服务器本身所剩内存不够申请。
2.清除部分数据,内存淘汰策略。
3.集群横向扩容,增加节点。
redis集群的扩容缩容问题
redis事务
redis事务:redis基于单线程模型,通过multi,exce,watch,discard等命令和队列链表的支持来实现redis事务。只有在同一个服务上的一组命令才能支持事务,因此redis cluster服务端是不支持事物的,除非想办法把一组命令路由到同一个redis master.
事务的实现:
redis服务端收到muti命令。
如果此刻有事务正在执行,将事务加入队列等待。否则直接执行。
在队列等待过程中watch机制把通过cas对事务中的key进行监控,如果有key发生变化,标记为redis_dirty_cas,服务端拒绝执行,事务返回失败。
redis事务的ACID
有原子性,
无一致性,某一个命令失败,其他操作不会回滚,redis无视这一点,因为要实现一致性太复杂了,会影响效率,redis的宗旨是高速。mysql的一致性方案复杂的让人爆炸。
隔离性,单线程天然的隔离性,
持久性取决于redis自身有没有做持久化。
redis单线程多线程指的是网络IO线程,6.0变为多线程。读写操作一直都是单线程操作。
redis使用优化
1.redis自身优化
目的:减少内存占用,提升操作效率
减少内存占用:
编码方面:选择合适的数据结构,,hash,bitmap例如:存用户信息:key:id value hash(k属性,v属性值)
进行适当的数据压缩:例如key里面重复的前缀可以去掉,value也一样
避免大value存入,删除保存都很慢
设置key过期时间:避免冷数据长期占用内存
配置方面:设置hash类型压缩的的阈值(1000性能较好)
选择合适的内存淘汰策略
操作系统层面:fork子进程的内存分配策略
架构层面:通过集群架构,扩容增大内存
提升操作效率:
编码方面:禁止使用bigkey,可进行拆分,String最大限制512M,6.0增大到1G,1M以内翻倍扩容,大于1M每次扩容1M很慢
禁止使用keys*,可用scan代替,删除使用UNLINK非阻塞
用高效的命令替换低效命令
连续的操作使用pipline批量提交请求,减少网络I/O
配置方面:持久化的必要性和选型,要不要持久化,aof的刷盘策略,如无必要 不要always
redis4.0redis网络模块使用多线程,可升级redis版本
2.热点key的处理?
监控+处理
监控:客户端统计字典、代理端codis、服务端monitor命令监控统计
处理:热点key打散+本地二级缓存
3.减少整体RTT
redis客户端批量操作多条命令打包发送的方式,节省rtt,减少上下文切换
1.pipeline 命令快、结果集
2.transaction
3.lua script
4.缓存预热:
手动:刷新缓存页面/接口
自动:1.少量缓存可在项目启动时进行加载。2.定时任务刷新缓存。
Redis常见客户端
Jedis: 以Redis命令作为方法名称简单实用但Jedis实例是线程不安全的, 多线程环境下需要基于连接池来使用
Lettuce: 也提供了Redis命令对应的API并且是线程安全的,且基于Netty实现支持同步/异步和响应式编程方式, 支持Redis的哨兵模式、集群模式和管道模式
Redisson: 在Redis基础上实现了分布式的可伸缩的java数据结构(如Map等), 支持跨进程的同步机制(Lock、Semaphore等待),适合用来实现特殊功能需求
SpringDataRedis: 对Jedis和Lettuce做了抽象和封装,在Spring Boot项目中还提供了对应的Starterspring-boot-starter-data-redis
redis的内存管理
redis内存包括自身内存还有内存碎片缓冲内存等等组成,在redis的内存设置时,可以通过maxmamory设置最大缓存,一般要留服务器很大一部分用于其他进程的操作。
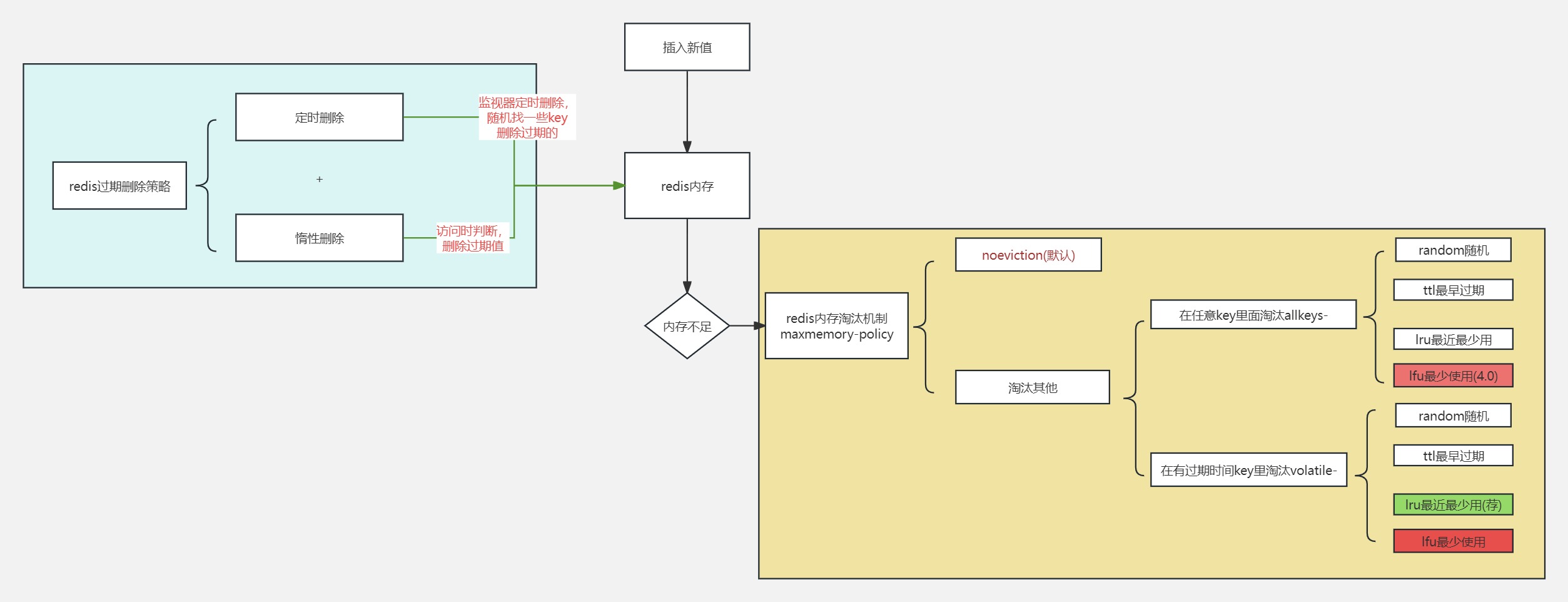
redis的内存管理包括过期删除和内存不足淘汰。
redis过期删除机制
定时删除+惰性删除
定时删除:redis有一个线程每隔100ms会随机获取一些设置了过期时间的key,并删除其中已经过期的key。这并不能删除所有过期的key,因此还需要惰性删除。
惰性删除:当访问一个key时,发现这个key已经过期,会删除key.
redis内存淘汰机制
当向redis数据库写入数据发现内存不足时,会进行执行内存淘汰策略。配置maxmemory-policy:默认noevication不淘汰,内存不足时直接报错
Rdis持久化
redis的缓存保存在内存中,为了防止数据丢失提高缓存的可用性,可以通过配置对缓存数据进行持久化。默认开启RDB持久化。
redis的持久化方式主要有两种RDB和AOF,redis4.0增加了混合持久化方式,开启的前提是RDB和AOF开启。aof-use-rdb-preamble yes
| 持久化方式 | 开启方式 | 是否默认 | 持久化文件名 | 文件格式 | 触发时机 | 其他操作 | 优先级 |
| RDB | save 200 10 | 是 | dump.rdb | 二进制 |
自动: save n(s) m(key) 关闭redis进程 手动:save/bgsave |
COW写时复制 | 低 |
| AOF | appendonly yes | 否 | appendonly.aof | resp命令 |
appendfsync配置: appendfsync always appendfsync everysec(默) appendfsync none |
AOF重写(压缩) #auto-aof-rewrite-min-size 64mb |
高 |
|
AOF PLUS混合方式 (4.0以后) |
appendonly yes aof-use-rdb-preamble yes |
-- | -- | rdb+aof格式 | -- | -- | -- |
AOF的持久化策略
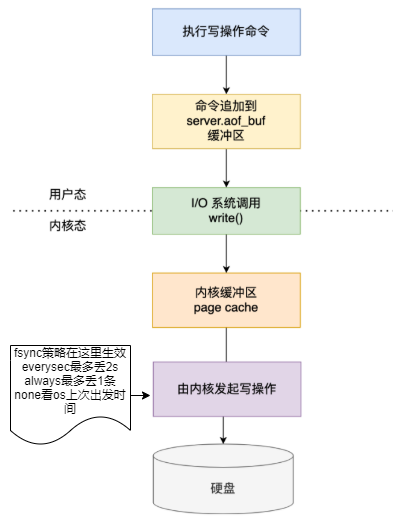
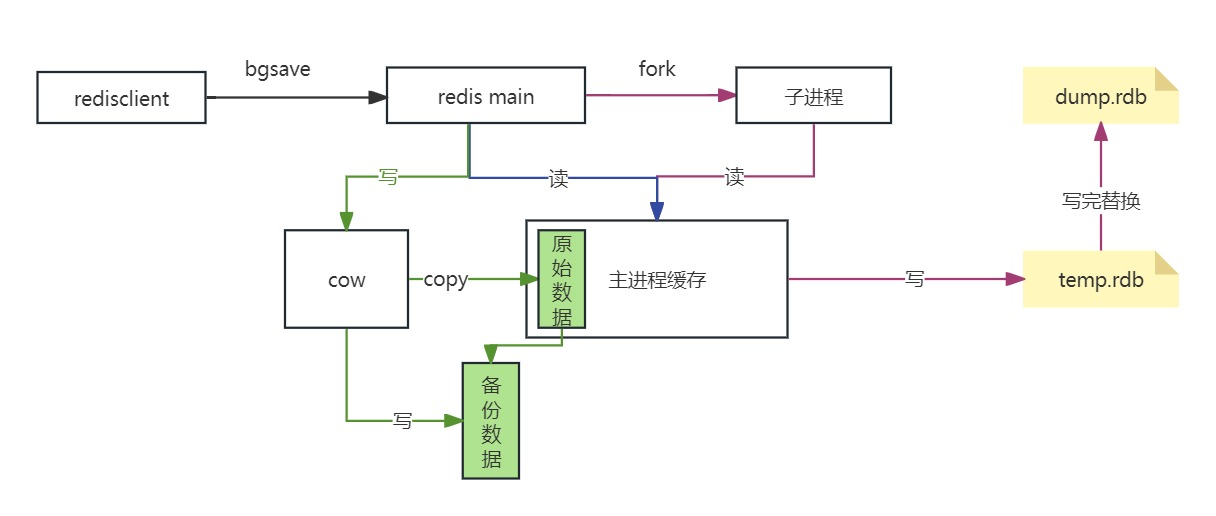
AOF写时复制流程
AOF文件重写
为什么要重写?
因aof保存的是resp命令,文件会随着写操作的增加越来越大。为了压缩文件,需要对appedonly.aof文件进行重写。
原理:
基本思想就是命令合并或者说是把过程变成结果。对于同一条数据在原文件中有反反复复各种操作记录多条,新的文件只记录一条。
重写过程
bgrewirte命令创建一个子进程进行重写操作。
在压缩的过程中,原文件继续写入,会创建一个新的aof进行写入,当新的aof文件写入完成后改名appedonly.aof覆盖原文件。
在服务启动时,如果有aof文件,会优先使用aof进行重放恢复数据。
但是,aof如果全是resp文件一般会比较大,数据恢复会慢。
因此,redis4.0因为混合模式。rdb+aof格式组成aof文件,在重写前的数据全部保存二进制格式占用更小的空间,恢复起来更快,重写完成之后的数据会以aof的格式继续追加,不会太大。
aof重写的触发:
1.手动 bgrewirte
2.自动触发:
满足条件:1.auto-aof-rewrite-min-size 64mb (默认,可配置)
2.auto-aof-rewrite-percentage 100(默认,可配置)
redis实现分布式锁
1.互斥 setnex
2.解决死锁 set expire
3.过期提前释放 看门口机制自动续期(redission支持)
4.错误释放、重入支持:threadlocal线程标识(redission支持)
redlock
5.高可用(down机):redlock -------不推荐,太重,成本大,NPC问题(网络延迟)。
redis追求ap而不是cp,如果很在意,建议用zk分布式锁
官方建议至少5个master,n/2+1获取锁成功才算成功,注意获取锁耗时和锁过期时间的比较,避免获取成功前就有数据过期,这样很难成功。
redis常见性能问题解决方案
redis使用注意事项:
1.不要使用keys,可以用scan代替。
2.redis瓶颈在于网络io非cpu计算。redis6.0以前使用io多路复用机制,6.0改为多线程处理,增加worker thread
3.持久化命令rdsave会同步阻塞,使用rdbsavebankground。
4.阻塞问题,原因:慢查询、大量请求导致单cpu负载过大、持久化引起。
可以分析慢查询进行优化,增加集群结点数量。持久化可以在从节点做,主从复制采用树形复制。
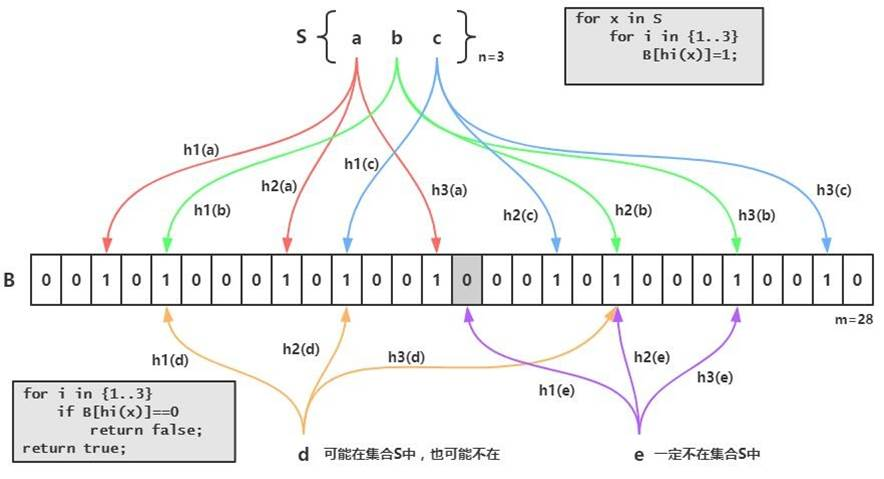
布隆过滤器
实现基本原理:
它实际上是一个很长的二进制向量(可以使用bitmap)和一系列随机映射函数。
优点:节省空间、查询速度快
缺点:hash函数越多,准确率越高,但是计算效率越低。因为是多个hash算法计算结果在bitmap中的散列,因此可能存在hash碰撞,因此,只能增加key,不能移除key,防止影响到别的key.