


autovacuum 是 postgresql 里非常重要的一个服务端进程,能够自动地执行,在一定条件下自动地对 dead tuples 进行清理并对表进行分析。
1.1 什么是autovacuum?
autocuum是启动postgresql时自动启动的后台实用程序之一。
在生产环境中不应该将其关闭
autovacuum=on #默认on
track_counts=on #默认on
1.2 为什么需要autovacuum
- 需要vacuum来移除死元组
- 防止死元组膨胀
- 更新表的统计信息进行分析,以便提供优化器使用
- autovacuum launcher使用Stats Collector的后台进程收集的信息来确定autovacuum的候选表列表
1.3 记录autovacuum
log_autovacuum_min_duration=-1 # -1表示不记录,0表示记录所有的,大于0(如250ms,1s,1min,1h,1d)表示真空操作大于此值的操作
1.4 什么时候做autovacuum
Autovacuum实际操作的内容
-
Autovacuum
触发条件(如果由于更新或删除,表中的实际死元组数超过此有效阈值,则该表将成为autovacuum的候选表)
-
Autovacuum ANALYZE
thresold a table = autovacuum_analyze_scale_factor * number of tuples + autovacuum_analyze_threshold
autovacuum_vacuum_threshold = 50 # min number of row updates before vacuum
autovacuum_analyze_threshold = 50 # min number of row updates before analyze
autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
举个例子
test表有1000行记录。
上面的公式作为参考:
当test表成为autovacuum vacuum的候选者,满足的条件如下:
更新/删除的记录:0.2*1000 + 50 = 250
插入/更新/删除的记录:0.1*1000 + 50 = 150
1.5 这是不是一个问题
table1=100行
其触发analyze和vacuum的阈值分别是:60和70。
table2=100w行
其触发analyze和vacuum的阈值分别是:100050和200050.
1.6 如何确定需要调整其autovacuum setting的表
为了单独调整表的autovacuum,必须知道一段时间内表上的插入/删除/更新数。
postgres=# select n_tup_ins,n_tup_upd,n_tup_del,n_live_tup,n_dead_tup from pg_stat_user_tables where schemaname = 'public' and relname = 'test';
n_tup_ins | n_tup_upd | n_tup_del | n_live_tup | n_dead_tup
-----------+-----------+-----------+------------+------------
1000 | 0 | 249 | 751 | 0
(1 row)
表autovacuum setting的设置
可以通过设置单个表的存储参数来重写此行为,这样会忽略全局设置。
postgres=# alter table test set (autovacuum_vacuum_cost_limit=500);
ALTER TABLE
postgres=# alter table test set (autovacuum_vacuum_cost_delay=10);
ALTER TABLE
postgres=# \d+ test
Table "public.test"
Column | Type | Modifiers | Storage | Stats target | Description
--------+---------+-----------+----------+--------------+-------------
id | integer | | plain | |
info | text | | extended | |
Has OIDs: no
Options: autovacuum_vacuum_cost_limit=500, autovacuum_vacuum_cost_delay=10
1.7 一次可以运行多个autovacuum过程
在可能包含多个数据库的实例/集群上,一次运行的autovacuum进程数不能超过下面参数设置的值:
autovacuum_max_workers = 3 # max number of autovacuum subprocesses
# (change requires restart)
autovacuum_naptime = 1min # time between autovacuum runs
启动下一个autovacuum之前的等待时间:
autovacuum_naptime/N,其中N是实例中数据库的总数。真空是IO密集型操作,设置了一些参数来最小化真空对IO的影响。
# 可达到的总成本限制,结合所有的autovacuum作业
autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
# 当一个清理工作达到autovacuum_vacuum_cost_limit指定的成本限制时,autovacuum将休眠数毫秒
autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
# - Cost-Based Vacuum Delay -
#vacuum_cost_delay = 0 # 0-100 milliseconds
# 读取已在共享缓冲区中且不需要磁盘读取的页的成本
vacuum_cost_page_hit = 1 # 0-10000 credits
# 获取不在共享缓冲区中的页的成本
vacuum_cost_page_miss = 10 # 0-10000 credits
# 在每一页中发现死元组时写入该页的成本
vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 credits
1秒(1000ms)中会发生什么
在读取延迟为0毫秒的最佳情况下,autovacuum可以唤醒并进入睡眠50次(1000毫秒/20毫秒),因为唤醒之间的延迟需要20毫秒。
由于在共享缓冲区中每次读取一个页面的相关成本时1,因此在每个唤醒中可以读取200个页面(因为上面把总成本限制设置为200),在50个唤醒中可以读取50*200个页面。
如果在共享缓冲区中找到了所有具有死元组的页,并且autovacuum代价延迟为20毫秒,则它可以在每一轮中读取:((200/vacuum_cost_page_hit)*8)kb,这需要等待autovacuum代价延迟时间量。
因此,考虑到块大小为8192字节,autovacuum最多可以读取:50 * 200 * 8kb=78.13 MB/s。
如果块不在共享缓冲区中,需要从磁盘读取,则autovacuum最多可以读取:50 * 200 * 8kb=7.81 MB/s。
现在,为了从页/块中删除死元组,写操作的开销是:vacuum_cost_page_dirty,默认20。
一个autovacuum每秒最多可以写/脏:50 * (200/vacuum_cost_page_dirty) * 8kb=3.9 MB/s。
谨慎设置autovacuum_max_workers
通常,此成本平均分配给实例中运行的所有autovacuum过程的autovacuum_max_workers数。因此增加vacuum_max_workers可能会延迟当前运行的autovacuum workers的autovacuum执行。而增加autovacuum_vacuum_cost_limit可能会导致IO瓶颈。可以通过设置单个表的存储参数来重写此行为,这样会忽略全局设置。
1.8 冻结txids
Transaction ID
-
每当事物开始时,事务管理器就会分配一个唯一的标识符,称为事物id(txid);
-
PostgreSQL的txid是一个32位无符号整数,大约42亿;
-
冻结txid的目的就是为了行可见性;
1、删除指向相应死元组的死元组和索引元组;
2、清除CLOG中不必要的部分。
3、冻结旧txids;
4、更新FSM,VM和统计信息。
-
请注意,BEGIN命令没有指定txid。在PostgreSQL中,当第一个命令在BEGIN命令执行后执行时,事务管理器会分配一个txid,然后分配它的事物开始。
postgres=# begin;
BEGIN
postgres=# select txid_current();
txid_current
--------------
100
(1 row)
- 0表示无效的 txid。
- 1表示Bootstrap txid,仅在数据库集群初始化时使用。
- 2表示Frozen txid。
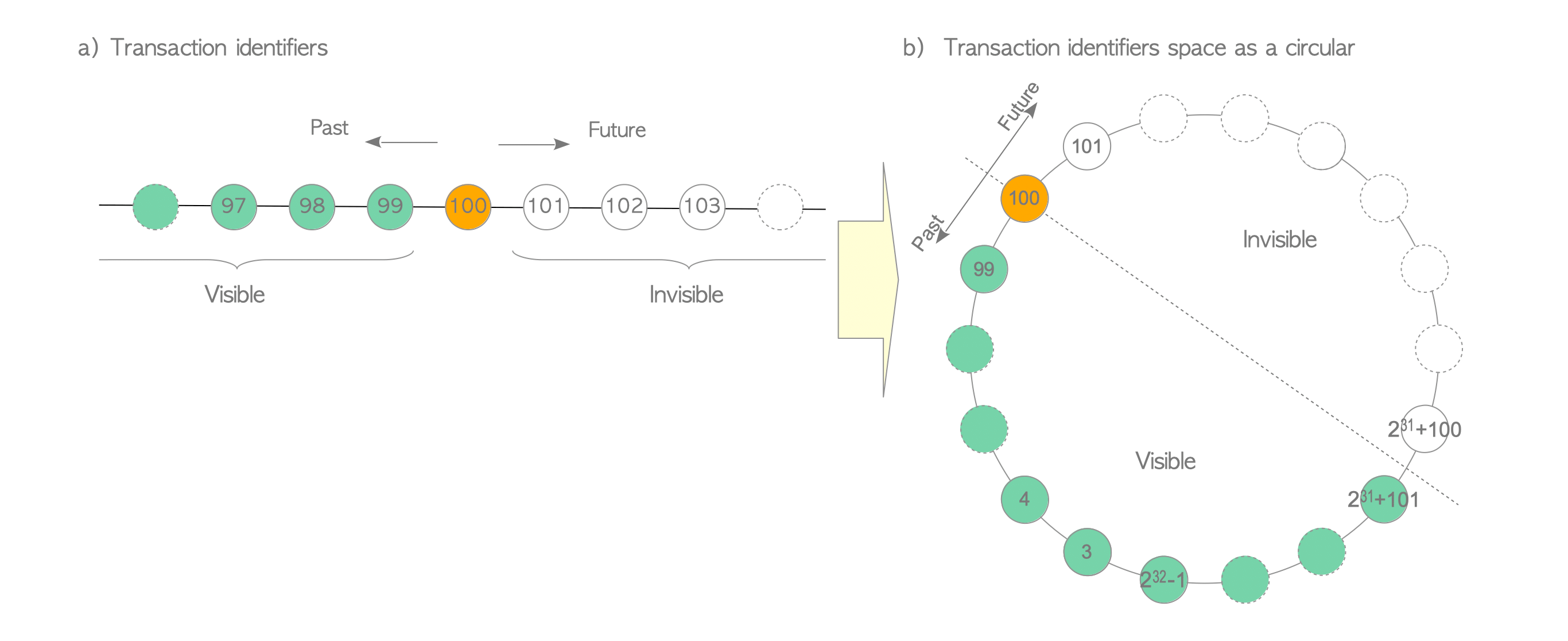
- Txid 可以相互比较。例如,在 txid 100 的观点上,大于 100 的 txid 是“未来”,从 txid 100 看是不可见的;小于 100 的 txid 是“过去的”并且可见(图 5.1 a))。
PostgreSQL 中的事务 ID
元组结构

HeapTupleHeaderData 结构在src/include/access/htup_details.h中定义。
- t_xmin保存插入此元组的事务的 txid。
- t_xmax保存删除或更新此元组的事务的 txid。如果此元组尚未删除或更新,则 t_xmax 设置为0,表示无效。
- t_cid保存的是命令id(cid),表示从0开始在当前事务中执行该命令之前执行了多少条SQL命令。例如,假设我们在单个事务中执行了三个INSERT命令:’BEGIN; INSERT; INSERT; INSERT; END;’。如果第一个命令插入此元组,则 t_cid 设置为 0。如果第二个命令插入此元组,则 t_cid 设置为 1,依此类推。
- t_ctid保存指向自身或新元组的元组标识符(tid)。tid用于标识表中的元组。当这个元组更新时,这个元组的t_ctid指向新的元组;否则, t_ctid 指向它自己。
插入、删除和更新元组
为了专注于元组,下面没有表示页眉和行指针。
元组的表示

插入
通过插入操作,一个新的元组被直接插入到目标表的一页中。
元组插入

假设一个 tuple 被一个 txid 为 99 的事务插入到一个页面中。在这种情况下,插入的 tuple 的 header 字段设置如下。
- 元组_1:
- t_xmin设置为 99,因为这个元组是由 txid 99 插入的。
- t_xmax设置为 0,因为该元组尚未被删除或更新。
- t_cid设置为 0,因为这个元组是 txid 99 插入的第一个元组。
- t_ctid设置为 (0,1),指向自身,因为这是最新的元组。
删除
在删除操作中,目标元组被逻辑删除。执行 DELETE 命令的 txid 的值设置为元组的 t_xmax。
元组删除

假设 Tuple_1 被 txid 111 删除,此时 Tuple_1 的头部字段设置如下。
- 元组_1:
- t_xmax设置为 111。
如果提交 txid 111,则不再需要 Tuple_1。通常,不需要的元组在 PostgreSQL 中被称为死元组。
死元组最终应该从页面中删除。清理死元组被称为VACUUM处理。
更新
在更新操作中,PostgreSQL 在逻辑上删除最新的元组并插入一个新元组。
更新该行两次
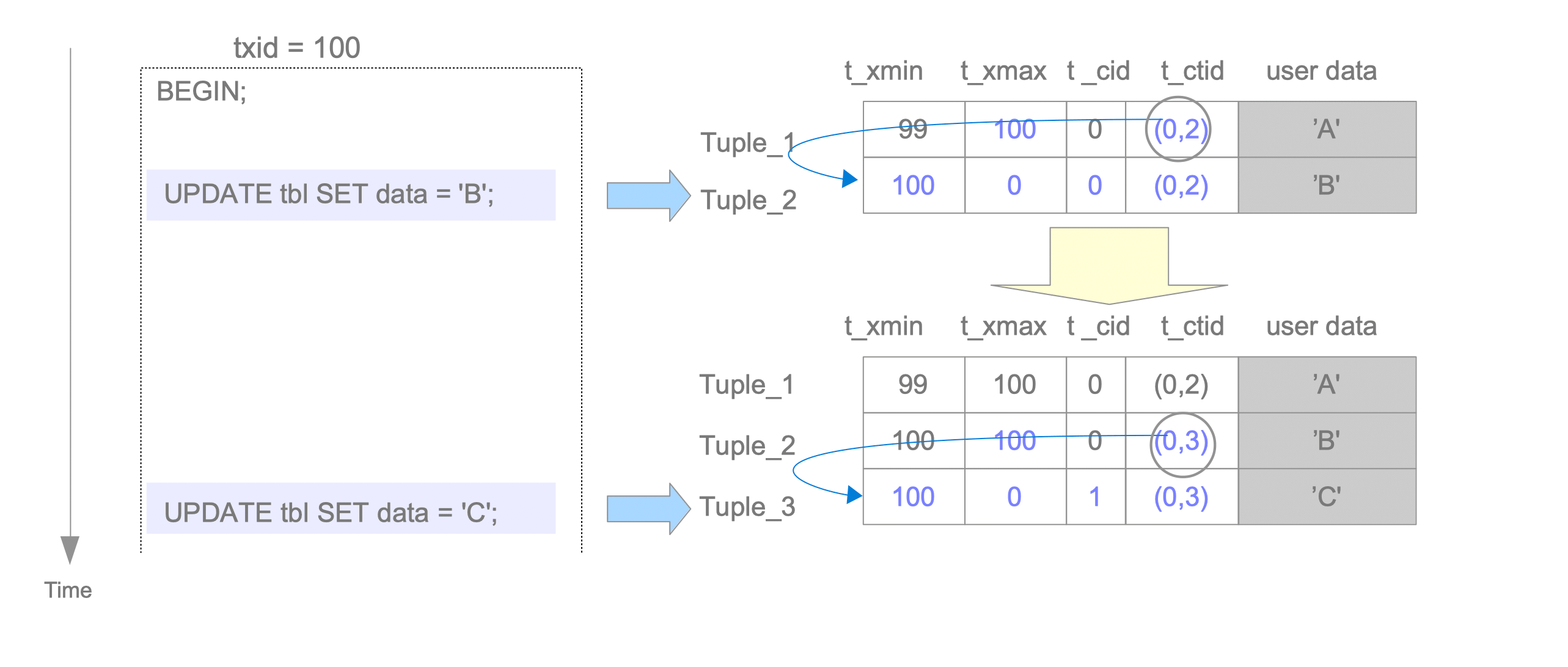
假设已经被 txid 99 插入的行被 txid 100 更新了两次。
当执行第一个 UPDATE 命令时,通过将 txid 100 设置为 t_xmax 逻辑删除Tuple_1,然后插入 Tuple_2。然后,将Tuple_1的 t_ctid 重写为指向 Tuple_2。Tuple_1 和 Tuple_2 的头字段如下。
- 元组_1:
- t_xmax设置为 100。
- t_ctid从 (0, 1) 重写为 (0, 2)。
- 元组_2:
- t_xmin设置为 100。
- t_xmax设置为 0。
- t_cid设置为 0。
- t_ctid设置为 (0,2)。
当执行第二个 UPDATE 命令时,与第一个 UPDATE 命令一样,逻辑上删除 Tuple_2 并插入 Tuple_3。Tuple_2 和 Tuple_3 的头字段如下。
- 元组_2:
- t_xmax设置为 100。
- t_ctid从 (0, 2) 重写为 (0, 3)。
- 元组_3:
- t_xmin设置为 100。
- t_xmax设置为 0。
- t_cid设置为 1。
- t_ctid设置为 (0,3)。
与删除操作一样,如果提交 txid 100,则 Tuple_1 和 Tuple_2 将是死元组,如果中止 txid 100,则 Tuple_2 和 Tuple_3 将是死元组。
页面检查
PostgreSQL 提供了一个扩展pageinspect,它是一个贡献模块,用于显示数据库页面的内容。
testdb=# CREATE EXTENSION pageinspect;
CREATE EXTENSION
testdb=# CREATE TABLE tbl (data text);
CREATE TABLE
testdb=# INSERT INTO tbl VALUES('A');
INSERT 0 1
testdb=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 99 | 0 | 0 | (0,1)
(1 row)
postgres=# delete from tbl;
DELETE 1
postgres=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 4965 | 4966 | 0 | (0,1)
(1 row)
postgres=# truncate table tbl;
TRUNCATE TABLE
postgres=# INSERT INTO tbl VALUES('A');
INSERT 0 1
postgres=# begin;
BEGIN
postgres=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 4979 | 0 | 0 | (0,1)
(1 row)
postgres=# update tbl set data = 'B';
UPDATE 1
postgres=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 4979 | 4980 | 0 | (0,2)
2 | 4980 | 0 | 0 | (0,2)
(2 rows)
postgres=# update tbl set data = 'C';
UPDATE 1
postgres=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 4979 | 4980 | 0 | (0,2)
2 | 4980 | 4980 | 0 | (0,3)
3 | 4980 | 0 | 1 | (0,3)
(3 rows)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异