
块存储和文件存储是我们比较熟悉的两种主流的存储类型,而对象存储(Object-based Storage)是一种新的网络存储架构,基于对象存储技术的设备就是对象存储设备(Object-based Storage Device)简称OSD。
首先,我们介绍这两种传统的存储类型。通常来讲,所有磁盘阵列都是基于Block块的模式,而所有的NAS产品都是文件级存储。
【块级、文件级概念】
1.块级概念:
块级是指以扇区为基础,一个或我连续的扇区组成一个块,也叫物理块。它是在文件系统与块设备(例如:磁盘驱动器)之间。
2.文件级概念:
文件级是指文件系统,单个文件可能由于一个或多个逻辑块组成,且逻辑块之间是不连续分布。逻辑块大于或等于物理块整数倍,
3.物理块与文件系统之间的关系图:
映射关系:扇区→物理块→逻辑块→文件系统
【块级、文件级备份】
【文件级备份】
文件级备份是指在指定某些文件进行备份时,首先会查找每个文件逻辑块,其次物理块,由于逻辑块是分散在物理块上,而物理块也是分散在不同扇区上。需要一层一 层往下查找,最后才完成整个文件复制。文件级备份时比较费时间,效率不高,实时性不强,备份时间长,且增量备份时,单文件某一小部份修改,不会只备份修改 部份,而整个文件都备份。
【块级备份】
块级备份是指物理块复制,效率高,实时性强,备份时间短,且增量备份时,只备份修改过的物理块。
【目前文件级备份工具】
Symantec NBU/BE 备份软件、Commvault、CA、Networker
【目前块级备份工具】
飞康CDP、Recoverpoint、杭州信核CDP、Novell CDP
备份【时间点保留周期】
传统备份软件(文件级备份),可以保留备份时间点多,恢复颗粒度大
CDP备份(块级备份),可以保留备份时间点少,恢复颗粒度小
【块、文件、对象存储设备】
【块存储】
典型设备:磁盘阵列,硬盘,虚拟硬盘
【文件存储】
典型设备:FTP、NFS服务器,SamBa
【对象存储】
典型设备:内置大容量硬盘的分布式服务器
分布式存储的应用场景相对于其存储接口,现在流行分为三种:
对象存储:也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL和其他扩展,如七牛、又拍、Swift、S3
块存储:这种接口通常以QEMU Driver或者Kernel Module的方式存在,这种接口需要实现Linux的Block Device的接口或者QEMU提供的Block Driver接口,如Sheepdog,AWS的EBS,青云的云硬盘和阿里云的盘古系统,还有Ceph的RBD(RBD是Ceph面向块存储的接口)
文件存储:通常意义是支持POSIX接口,它跟传统的文件系统如Ext4是一个类型的,但区别在于分布式存储提供了并行化的能力,如Ceph的CephFS(CephFS是Ceph面向文件存储的接口),但是有时候又会把GFS,HDFS这种非POSIX接口的类文件存储接口归入此类。
1、块存储
以下列出的两种存储方式都是块存储类型:
1) DAS(Direct AttachSTorage):是直接连接于主机服务器的一种储存方式,每一台主机服务器有独立的储存设备,每台主机服务器的储存设备无法互通,需要跨主机存取资料时,必须经过相对复杂的设定,若主机服务器分属不同的操作系统,要存取彼此的资料,更是复杂,有些系统甚至不能存取。通常用在单一网络环境下且数据交换量不大,性能要求不高的环境下,可以说是一种应用较为早的技术实现。
2)SAN(Storage Area Network):是一种用高速(光纤)网络联接专业主机服务器的一种储存方式,此系统会位于主机群的后端,它使用高速I/O 联结方式, 如 SCSI, ESCON及 Fibre- Channels。一般而言,SAN应用在对网络速度要求高、对数据的可靠性和安全性要求高、对数据共享的性能要求高的应用环境中,特点是代价高,性能好。例如电信、银行的大数据量关键应用。它采用SCSI 块I/O的命令集,通过在磁盘或FC(Fiber Channel)级的数据访问提供高性能的随机I/O和数据吞吐率,它具有高带宽、低延迟的优势,在高性能计算中占有一席之地,但是由于SAN系统的价格较高,且可扩展性较差,已不能满足成千上万个CPU规模的系统。
2、文件存储
通常,NAS产品都是文件级存储。NAS(Network Attached Storage):是一套网络储存设备,通常是直接连在网络上并提供资料存取服务,一套 NAS 储存设备就如同一个提供数据文件服务的系统,特点是性价比高。例如教育、政府、企业等数据存储应用。
它采用NFS或CIFS命令集访问数据,以文件为传输协议,通过TCP/IP实现网络化存储,可扩展性好、价格便宜、用户易管理,如目前在集群计算中应用较多的NFS文件系统,但由于NAS的协议开销高、带宽低、延迟大,不利于在高性能集群中应用。

下面,我们对DAS、NAS、SAN三种技术进行比较和分析:

针对Linux集群对存储系统高性能和数据共享的需求,国际上已开始研究全新的存储架构和新型文件系统,希望能有效结合SAN和NAS系统的优点,支持直接访问磁盘以提高性能,通过共享的文件和元数据以简化管理,目前对象存储系统已成为Linux集群系统高性能存储系统的研究热点,如Panasas公司的Object Base Storage Cluster System系统和Cluster File Systems公司的Lustre等。下面将详细介绍对象存储系统。
3、对象存储
总体上来讲,对象存储同兼具SAN高速直接访问磁盘特点及NAS的分布式共享特点。
核心是将数据通路(数据读或写)和控制通路(元数据)分离,并且基于对象存储设备(Object-based Storage Device,OSD)构建存储系统,每个对象存储设备具有一定的智能,能够自动管理其上的数据分布。
对象存储结构组成部分(对象、对象存储设备、元数据服务器、对象存储系统的客户端):
3.1、对象
对象是系统中数据存储的基本单位,一个对象实际上就是文件的数据和一组属性信息(Meta Data)的组合,这些属性信息可以定义基于文件的RAID参数、数据分布和服务质量等,而传统的存储系统中用文件或块作为基本的存储单位,在块存储系统中还需要始终追踪系统中每个块的属性,对象通过与存储系统通信维护自己的属性。在存储设备中,所有对象都有一个对象标识,通过对象标识OSD命令访问该对象。通常有多种类型的对象,存储设备上的根对象标识存储设备和该设备的各种属性,组对象是存储设备上共享资源管理策略的对象集合等。
3.2、对象存储设备
对象存储设备具有一定的智能,它有自己的CPU、内存、网络和磁盘系统,OSD同块设备的不同不在于存储介质,而在于两者提供的访问接口。OSD的主要功能包括数据存储和安全访问。目前国际上通常采用刀片式结构实现对象存储设备。OSD提供三个主要功能:
(1) 数据存储。OSD管理对象数据,并将它们放置在标准的磁盘系统上,OSD不提供块接口访问方式,Client请求数据时用对象ID、偏移进行数据读写。
(2) 智能分布。OSD用其自身的CPU和内存优化数据分布,并支持数据的预取。由于OSD可以智能地支持对象的预取,从而可以优化磁盘的性能。
(3) 每个对象元数据的管理。OSD管理存储在其上对象的元数据,该元数据与传统的inode元数据相似,通常包括对象的数据块和对象的长度。而在传统的NAS系统中,这些元数据是由文件服务器维护的,对象存储架构将系统中主要的元数据管理工作由OSD来完成,降低了Client的开销。
3.3、元数据服务器(Metadata Server,MDS)
MDS控制Client与OSD对象的交互,主要提供以下几个功能:
(1) 对象存储访问。
MDS构造、管理描述每个文件分布的视图,允许Client直接访问对象。MDS为Client提供访问该文件所含对象的能力,OSD在接收到每个请求时将先验证该能力,然后才可以访问。
(2) 文件和目录访问管理。
MDS在存储系统上构建一个文件结构,包括限额控制、目录和文件的创建和删除、访问控制等。
(3) Client Cache一致性。
为了提高Client性能,在对象存储系统设计时通常支持Client方的Cache。由于引入Client方的Cache,带来了Cache一致性问题,MDS支持基于Client的文件Cache,当Cache的文件发生改变时,将通知Client刷新Cache,从而防止Cache不一致引发的问题。
3.4、对象存储系统的客户端Client
为了有效支持Client支持访问OSD上的对象,需要在计算节点实现对象存储系统的Client,通常提供POSIX文件系统接口,允许应用程序像执行标准的文件系统操作一样。
4、GlusterFS 和对象存储
GlusterFS是目前做得最好的分布式存储系统系统之一,而且已经开始商业化运行。但是,目前GlusterFS3.2.5版本还不支持对象存储。如果要实现海量存储,那么GlusterFS需要用对象存储。值得高兴的是,GlusterFS最近宣布要支持对象存储。它使用openstack的对象存储系统swift的上层PUT、GET等接口,支持对象存储。
【块存储,文件存储,对象存储的层次关系】
再看看这三种存储的一些技术细节,首先看看在系统层级的分布。
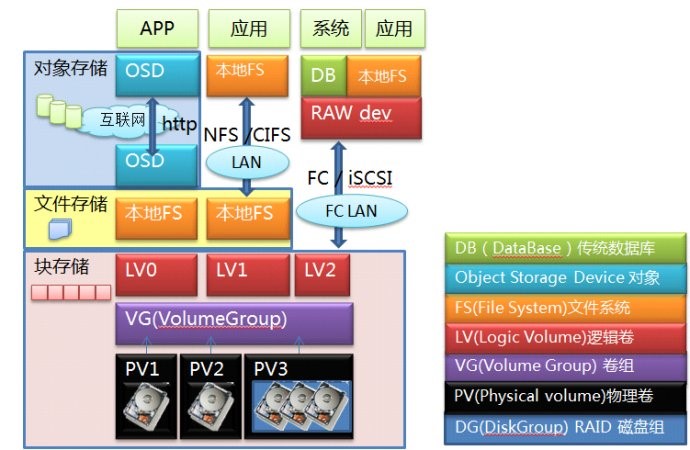
我们从底层往上看,最底层就是硬盘,多个硬盘可以做成RAID组,无论是单个硬盘还是RAID组,都可以做成PV,多个PV物理卷捏在一起构成VG卷组,这就做成一块大蛋糕了。接下来,可以从蛋糕上切下很多块LV逻辑卷,这就到了存储用户最熟悉的卷这层。到这一层为止,数据一直都是以Block块的形式存在的,这时候提供出来的服务就是块存储服务。你可以通过FC协议或者iSCSI协议对卷访问,映射到主机端本地,成为一个裸设备。在主机端可以直接在上面安装数据库,也可以格式化成文件系统后交给应用程序使用,这时候就是一个标准的SAN存储设备的访问模式,网络间传送的是块。
如果不急着访问,也可以在本地做文件系统,之后以NFS/CIFS协议挂载,映射到本地目录,直接以文件形式访问,这就成了NAS访问的模式,在网络间传送的是文件。
如果不走NAS,在本地文件系统上面部署OSD服务端,把整个设备做成一个OSD,这样的节点多来几个,再加上必要的MDS节点,互联网另一端的应用程序再通过HTTP协议直接进行访问,这就变成了对象存储的访问模式。当然对象存储通常不需要专业的存储设备,前面那些LV/VG/PV层也可以统统不要,直接在硬盘上做本地文件系统,之后再做成OSD,这种才是对象存储的标准模式,对象存储的硬件设备通常就用大盘位的服务器。
从系统层级上来说,这三种存储是按照块->文件->对象逐级向上的。文件一定是基于块上面去做,不管是远端还是本地。而对象存储的底层或者说后端存储通常是基于一个本地文件系统(XFS/Ext4..)。这样做是比较合理顺畅的架构。但是大家想法很多,还有各种特异的产品出现,我们逐个来看看:
对象存储除了基于文件,可以直接基于块,但是做这个实现的很少,毕竟你还是得把文件系统的活给干了,自己实现一套元数据管理,也挺麻烦的,目前我只看到Nutanix宣称支持。另外对象存储还能基于对象存储,这就有点尴尬了,就是转一下,何必呢?但是这都不算最奇怪的,最奇怪的是把对象存储放在最底层,那就是这两年大红的Ceph。
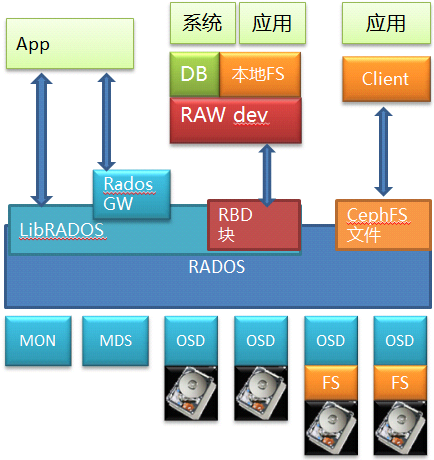
【Ceph简介】
Ceph是个开源的分布式存储,相信类似的架构图大家都见过,我把底层细节也画出来,方便分析。
底层是RADOS,这是个标准的对象存储。以RADOS为基础,Ceph
能够提供文件,块和对象三种存储服务。其中通过RBD提供出来的块存储是比较有价值的地方,毕竟因为市面上开源的分布式块存储少见嘛(以前倒是有个sheepdog,但是现在不当红了)。当然它也通过CephFS模块和相应的私有Client提供了文件服务,这也是很多人认为Ceph是个文件系统的原因。另外它自己原生的对象存储可以通过RadosGW存储网关模块向外提供对象存储服务,并且和对象存储的事实标准Amazon
S3以及Swift兼容。所以能看出来这其实是个大一统解决方案,啥都齐全。
上面讲的大家或多或少都有所了解,但底层的RADOS的细节可能会忽略,RADOS也是个标准对象存储,里面也有MDS的元数据管理和OSD的数据存储,而OSD本身是可以基于一个本地文件系统的,比如XFS/EXT4/Brtfs。在早期版本,你在部署Ceph的时候,是不是要给OSD创建数据目录啊?这一步其实就已经在本地文件系统上做操作了(现在的版本Ceph可以直接使用硬盘)。
现在我们来看数据访问路径,如果看Ceph的文件接口,自底层向上,经过了硬盘(块)->文件->对象->文件的路径;如果看RBD的块存储服务,则经过了硬盘(块)->文件->对象->块,也可能是硬盘(块)->对象->块的路径;再看看对象接口(虽然用的不多),则是经过了硬盘(块)->文件->对象或者硬盘(块)->对象的路径。
是不是各种组合差不多齐全了?如果你觉得只有Ceph一个这么玩,再给你介绍另一个狠角色,老牌的开源分布式文件系统GlusterFS最近也宣布要支持对象存储。它打算使用swift的上层PUT、GET等接口,支持对象存储。这是文件存储去兼容对象存储。对象存储Swift也没闲着,有人在研究Swift和hadoop的兼容性,要知道MapReduce标准是用原生的HDFS做存储的,这相当是对象存储去兼容文件存储,看来混搭真是潮流啊。
虽说现在大家都这么随便结合,但是这三种存储本质上还是有不同的,我们回到计算机的基础课程,从数据结构来看,这三种存储有着根本不同。块存储的数据结构是数组,而文件存储是二叉树(B,B-,B+,B*各种树),对象存储基本上都是哈希表。
数组和二叉树都是老生常谈,没有太多值得说的,而对象存储使用的哈希表也就是常听说的键值(KeyVaule型)存储的核心数据结构,每个对象找一个UID(所谓的“键”KEY),算哈希值(所谓的“值Vaule”)以后和目标对应。找了一个哈希表例子如下:
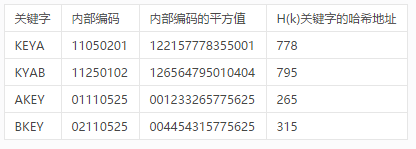
键值对应关系简单粗暴,毕竟算个hash值是很快的,这种扁平化组织形式可以做得非常大,避免了二叉树的深度,对于真.海量的数据存储和大规模访问都能给力支持。所以不仅是对象存储,很多NoSQL的分布式数据库都会使用它,比如Redis,MongoDB,Cassandra 还有Dynamo等等。顺便说一句,这类NoSQL的出现有点打破了数据库和文件存储的天然屏障,原本关系数据库里面是不会存放太大的数据的,但是现在像MongoDB这种NoSQL都支持直接往里扔大个的“文档”数据,所以从应用角度上,有时候会把对象存储,分布式文件系统,分布式数据库放到一个台面上来比较,这才是混搭。
当然实际上几个开源对象存储比如swift和ceph都是用的一致性哈希,进阶版,最后变成了一个环,首首尾相接,避免了节点故障时大量数据迁移的尴尬,这个几年前写Swift的时候就提过。这里不再深入细节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号