
1、ElasticSearch简介
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。 但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 **RESTful API** 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2、同类产品比较solr
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化 。并自带了图形管理界面。
- 数据相对少的请求下Solr的检索效率更高
- 建立索引时,Solr会产生阻塞IO,查询性能较差,ElasticSearch有优势
- 数据量大时,Solr的搜索效率变低,而ElasticSearch没有明显变化
- 安装使用方面ElasticSearch更为简单
总结:
- solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用,比如商品搜索 。
- ES建立索引快(即查询慢),即实时性查询快,适用用于数据频繁更新的应用,比如facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
- ES没有Solr成熟,学习成本相对较高。
二、ElasticSearch安装和可视化界面Elasticsearch-Head
1、ElasticSearch安装
下载Es安装包:
ElasticSearch的官方地址:https://www.elastic.co/guide/en/elasticsearch/reference/master/index.html
安装(如Mac OS):
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.3-darwin-x86_64.tar.gz wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.3-darwin-x86_64.tar.gz.sha512 shasum -a 512 -c elasticsearch-7.9.3-darwin-x86_64.tar.gz.sha512 tar -xzf elasticsearch-7.9.3-darwin-x86_64.tar.gz cd elasticsearch-7.9.3/
启动命令如下(-d以进程的形式启动elasticsearch,-p表示进程号记录到pid文件中):
./bin/elasticsearch -d -p pid
2、ES图形化管理界面安装
2.1、安装elasticsearch-head和Node.js
- 下载head:https://github.com/mobz/elasticsearch-head
- 下载Node.js:https://nodejs.org/en/download
注意elasticsearch和elasticsearch-head版本是对应的,否则会出现head无法支持elasticsearch的显示。
安装完成 在cmd窗口执行node -v查看node.js的版本号 检查是否安装成功。
2.2、安装grunt
通过node.js的包管理器npm安装grunt为全局,grunt是基于Node.js的项目构建工具
npm install -g grunt-cli
2.3、执行 npm install
注:不执行该命宁 使用grunt server命令会报错。
npm install
2.4、启动elasticsearch-head
打开命宁窗口在elasticsearch-head解压目录下执行 grunt server 启动服务:
HoudeMacBook-Pro:elasticsearch-head houjing$ grunt server Running "connect:server" (connect) task Waiting forever... Started connect web server on http://localhost:9100
然后访问 http://localhost:9100 (elasticsearch-head服务端口)。
2.5、配置ElasticSearch跨域访问
修改 config/elasticsearch.yml 文件
http.cors.enabled: true http.cors.allow-origin: "*"
注:需要重启ES服务。
2.6、head访问
在head页面输入链接的ElasticSearch地址,点击连接按钮。

三、 ElasticSearch的相关概念
1、概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(ducoment)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之能搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据 )进行索引、排序、过滤。Elasticsearch比传统关系型数据库如下。
关系型数据库 -> Databases -> Tables -> Rows -> Colums
ElasticSearch -> Indices -> Types(7版本已经没有此概念,相当于一个Database只有一张table) ->Documents -> Fields
2、ElasticSearch的核心概念
2.1、索引 index
一个索引就是有相似特征的文档集合,比如用户数据索引、订单数据索引、商品数据索引。
一个索引由一个全为小写字母的名字标识,我们在对应这个索引文档中进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个群集中可以定义任意多个索引。
2.2、类型type
在一个索引中,你可以定义一个或多个类型,一个类型是你的索引的一个逻辑上的分类,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型,比如说,我们订单数据索引中我们把订单信息作为一个类型,订单相关的物流信息做为一个类型。但在6.0开始建议index只包含一个type,在7.0之后开始去除(也并不是完全去除,而是默认为了_doc)。
2.3、字段field
相当于是数据表的字段,对文档根据不同的属性进行的分类标识。
2.4、映射 mapping (表结构)
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其他的就是处理es里面的数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立隐射才能对性能更好。
3.2.5、文档 document
一个文档是一个可被索引的基础单元。文档以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。
2.6、ElasticSearch版本问题说明
Elasticsearch 官网提出的近期版本对 type 概念的演变情况如下:
- 在 5.X 版本中,一个 index 下可以创建多个 type;
- 在 6.X 版本中,一个 index 下只能存在一个 type;
- 在 7.X 版本中,直接去除了 type的概念,就是说 index 不再会有 type。
去除type的原因 :
因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。但是,其搜索引擎是基于 Lucene的,这种 “基因”决定了 type 是多余的。Lucene 的全文检索功能之所以快,是因为倒序索引的存在。而这种倒序索引的生成是基于 index 的,而并非 type。
四、 ElasticSearch基本操作
基本操作在学习过程中可以使用单测工具进行,可以使用postman、jmeter,因为是使用http请求操作Es, 必须对RESTful 风格有所了解,所以在学习基本操作前,对RESTful 知识进行补充:
RESTful 在两方面做了相应规范:
- 服务数据交互格式使用json、xml。
- 采用HTTP协议规定的GET、POST、PUT、DELETE动作处理资源的增删该查操作。
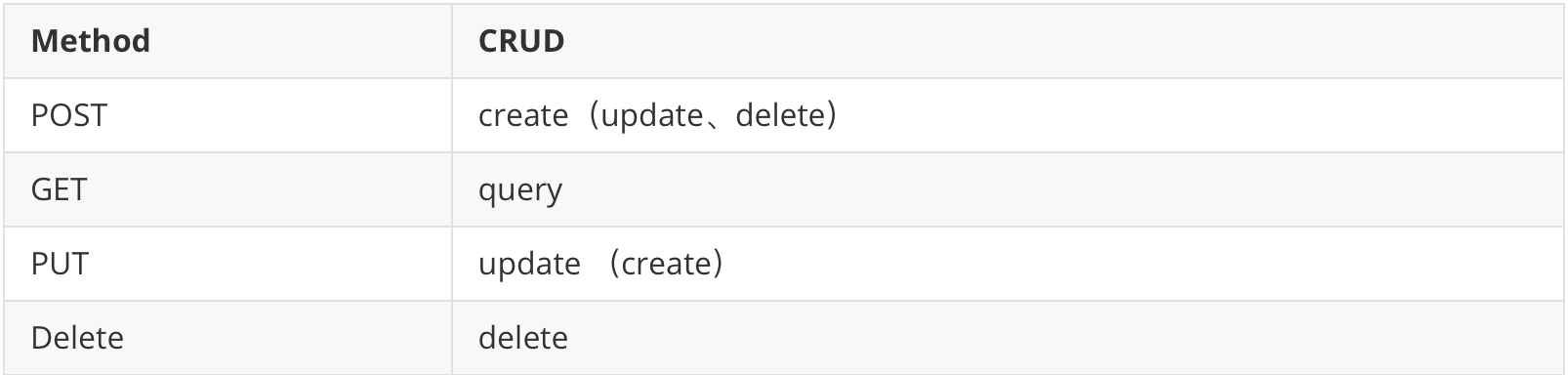
1、ElasticSearch语法
mapping字段详解:
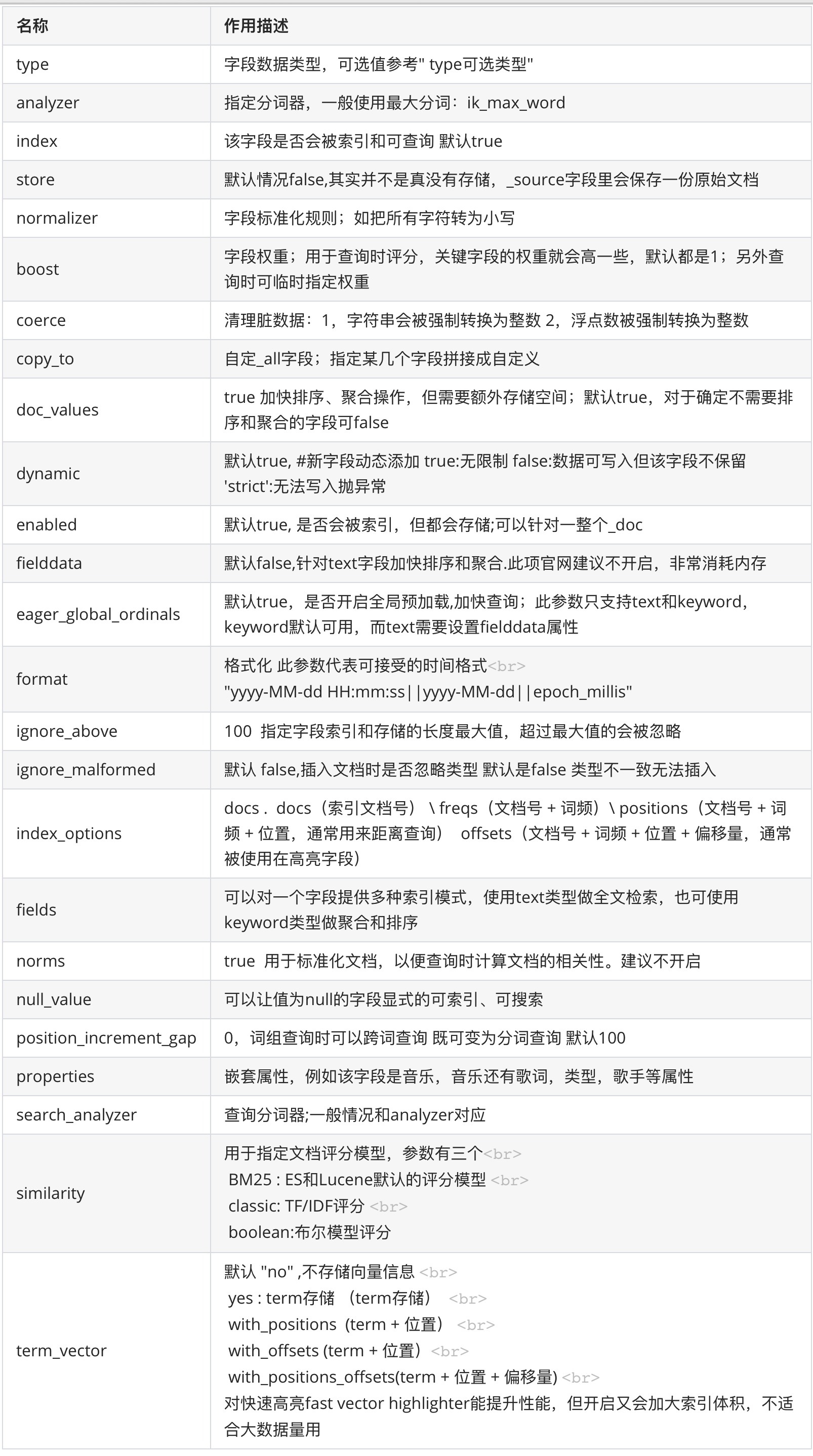
type 可选类型:
2、通过HTTP请求创建
2.1、仅创建索引
请求方式选择Put;请求链接如:http://127.0.0.1:9200/news 。结果:
{ "acknowledged": true, "shards_acknowledged": true, "index": "news" }
2.2、创建索引的同时创建mapping 以及分片复制参数
{ "settings": { "number_of_shards": 5, "number_of_replicas": 1, "refresh_interval": "30s", "index.analysis.analyzer.default.type": "ik_max_word" //分词器,未指定默认elastic自带的分词器,对中文支持差。 }, "mappings": { "properties": { "newsid": { "type": "text", "store": false, "index": true, "analyzer": "standard" }, "newsname": { "type": "text", "store": false, "index": true }, "newsdesc": { "type": "text", "store": false, "index": true } } } }
2.3、删除索引库
请求方式选择Delete,请求链接如:http://127.0.0.1:9200/news 删除news索引:
{ "acknowledged": true }
2.4、向索引库中添加文档
请求方式选 POST,单条插入请求url:
- http://127.0.0.1:9200/news/_doc/1 (索引/"**_doc**"/文档id)
- http://127.0.0.1:9200/news/_doc
文档id为Es中的文档主键id,不指定的情况下Es会给我们生成一个唯一的随机字符串,如 BU7pG24Bm2YrPBUaN0wD
{ "newsid":"1234", "newsname":"你猜不到的名字", "newsdesc":"这是一条新闻描述" }
如结果:
{ "_index": "news", "_type": "_doc", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
批量添加,请求url: http://127.0.0.1:9200/news/_bulk
{ "index":{} }
{ "newsid":"1234656","newsname":"miumiu" ,"newsdesc":"亲承5为自己生下5个孩子 此前12个" }
{ "index":{} }
{ "newsid":"1234657","newsname":"乒联" ,"newsdesc":"国际乒联奥地利公开赛正赛展开" }
{ "index":{"_id":"iikdjsd"} }
{ "newsid":"1234658","newsname":"纷纷两连败" ,"newsdesc":"两连败+二当家伤停再遭困境 考验欧文.." }
{ "index":{"_id":"iik3325"} }
{ "newsid":"1234659","newsname":"纷纷返回" ,"newsdesc":"33+9+4+5误!这是最乔治!黑贝最.." }
index可以指定参数,比如指定id,不指定则默认生成id。
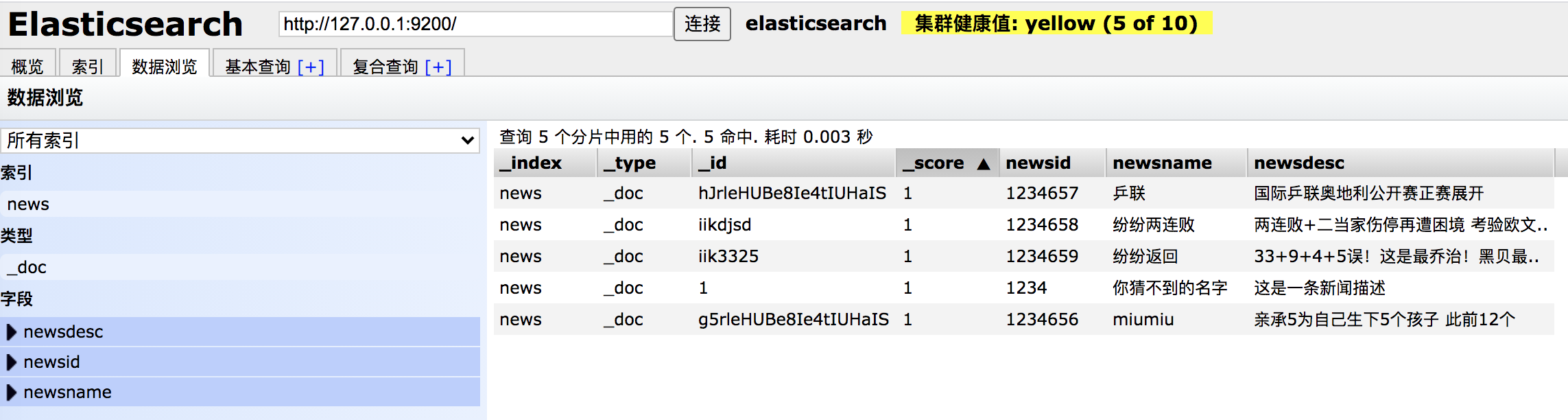
2.5、删除文档
请求方式选择Delete,请求url : http://127.0.0.1:9200/news/_doc/1 (索引/"**_doc**"/文档id)
2.6、查询文档
请求方式选择Get,请求url : http://127.0.0.1:9200/news/_doc/1 (索引/"**_doc**"/文档id)
2.7、修改文档
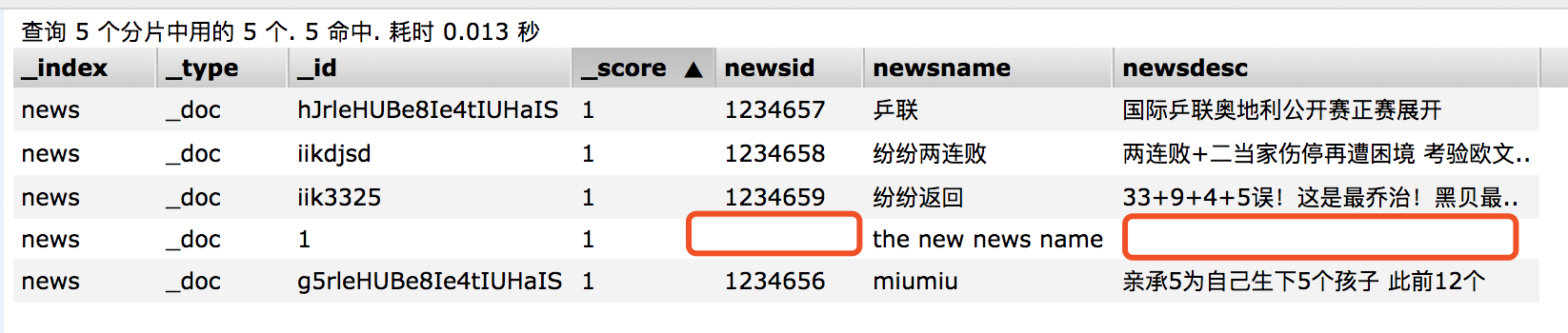
请求方式选择POST,请求url : http://127.0.0.1:9200/news/_doc/1 (索引/"**_doc**"/文档id)
{ "newsname":"the new news name" }
注意修改跟Mysql修改不一样,如上值提供了newsname时,修改后其余字段均为空:
2.8、根据关键词查询
请求方式选择Get:请求url http://127.0.0.1:9200/shop/_doc/_search (索引/"_doc"/"_search")
请求参数query、term为固定命名,newsdesc为指定在哪个字段查询什么关键字(支持什么样的关键字查询取决于mapping里指定的分析器,比如单个字为索引、分词索引,之前测试的语句都是标准分词,以单个字为索引,所以查询的时候只支持一个汉字,如果输入多个则查询不到数据)
基本查询:
{ "query": { "term": { "newsdesc": "国际" } } }
可以看出并未命中:
{ "took": 1, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 0, "relation": "eq" }, "max_score": null, "hits": [] } }
queryString是讲输入参数进行分词然后去索引库中检索:
{ "query": { "query_string": { "default_field": "newsdesc", "query": "国际" } } }
可以看到查询命中了:
{ "took": 20, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 0.5753642, "hits": [ { "_index": "news", "_type": "_doc", "_id": "EZrseHUBe8Ie4tIUuaQ_", "_score": 0.5753642, "_source": { "newsid": "1234657", "newsname": "乒联", "newsdesc": "国际乒联奥地利公开赛正赛展开" } } ] } }
因为默认的分词器,针对中文是按字分词的,terms查询是精确查询,所以查不出来。
五、ElasticSearch IK中文分词器
1、什么是分词器?为什么要分词器?
在上面的学习例子中我们使用的是Es默认的分词器,在中文的分词上并不友好,会将语句每个字进行分词作为索引,所以在使用Term关键字查询的时候多个汉字无法命中文档。这个时候就需要一个合理的分词规则,将一个完整的语句划分为多个比较复合表达逻辑的独立的词条。
分词器包含三个部分:
- character filter:分词之前的预处理,过滤掉HTML标签、特殊符号转换(例如,将&符号转换成and、将|符号转换成or)等。
- tokenizer:分词
- token filter:标准化
2、ElasticSeach内置分词器
- standard分词器:(默认的)它将词汇单元转换成小写形式,并去掉停用词(a、an、the等没有实际意义的词)和标点符号,支持中文采用的方法为单字切分(例如,‘你好’切分为‘你’和‘好’)。
- simple分词器:首先通过非字母字符来分割文本信息,然后将词汇单元同一为小写形式。该分析器会去掉数字类型的字符。
- Whitespace分词器:仅仅是去除空格,对字符没有lowcase(大小写转换)化,不支持中文;并且不对生成的词汇单元进行其他的标准化处理。
- language分词器:特定语言的分词器,不支持中文。
3、IK分词器
3.1、IK分词器简介
IK分词器在是一款 基于词典和规则 的中文分词器,提供了两种分词模式:ik_smart (智能模式)和ik_max_word (细粒度模式)
输入数据:
IK Analyzer是一个结合词典分词和文法分词的中文分词开源工具包。它使用了全新的正向迭代最细粒度切分算法。
智能模式效果:
ik analyzer 是 一个 结合 词典 分词 和 文法 分词 的 中文 分词 开源 工具包 它 使 用了 全新 的 正向 迭代 最 细粒度 切分 算法
细粒度模式:
ik analyzer 是 一个 一 个 结合 词典 分词 和文 文法 分词 的 中文 分词 开源 工具包 工具 包 它 使用 用了 全新 的 正向 迭代 最 细粒度 细粒 粒度 切分 切 分 算法
3.2、ElasticSearch集成Ik分词器
Ik分词器下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
不同版本的集成会有所区别,请下载ES版本对应的ik分词器版本。
下载解压后到你的 elasticsearch 插件目录并重启elasticsearch, 如: plugins/ik。
3.3、使用ElasticSearch中的 analyze 测试Ik分词效果
请求方式post;请求url http://127.0.0.1:9200/_analyze
请求参数:
{ "analyzer": "ik_smart",//ik_max_word "text": "IK Analyzer是一个结合词典分词和文法分词的中文分词开源工具包。它使用了全新的正向迭代最细粒度切分算法。" }
3.4、Ik分词器停用词和扩展词
在实际使用过程中Ik分词算法的过程中,还有一些场景的分词规则是Ik无法设计的,很多时候一个网络用语没有被解析成一个词条,以及其中的“的”这样的助词往往在建立索引的时候是没有必要的。所以IK支持停用词和扩展词的配置。
需要修改配置文件config/IKAnalyzer.cfg.xml:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict"></entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords"></entry> <!--用户可以在这里配置远程扩展字典 --> <!-- <entry key="remote_ext_dict">words_location</entry> --> <!--用户可以在这里配置远程扩展停止词字典--> <!-- <entry key="remote_ext_stopwords">words_location</entry> --> </properties>
- ext_dict填入扩展词文件。
- ext_stopwords填入停用词文件。
- 文件以dic后缀结尾,需要和IKAnalyzer.cfg在同级目录。
- dic文件每个词需要占一行。
六、ElasticSearch集群
在我们常见的项目中,很多时候都是分布式/集群部署的:对于不用的微服务通过Nginx负载或者注册到APIGateway、Zuul网关,然后每个服务进行主从/集群部署,然后用到的数据存储你产品也是基于分片+主从,保证可用性,如下图所示:
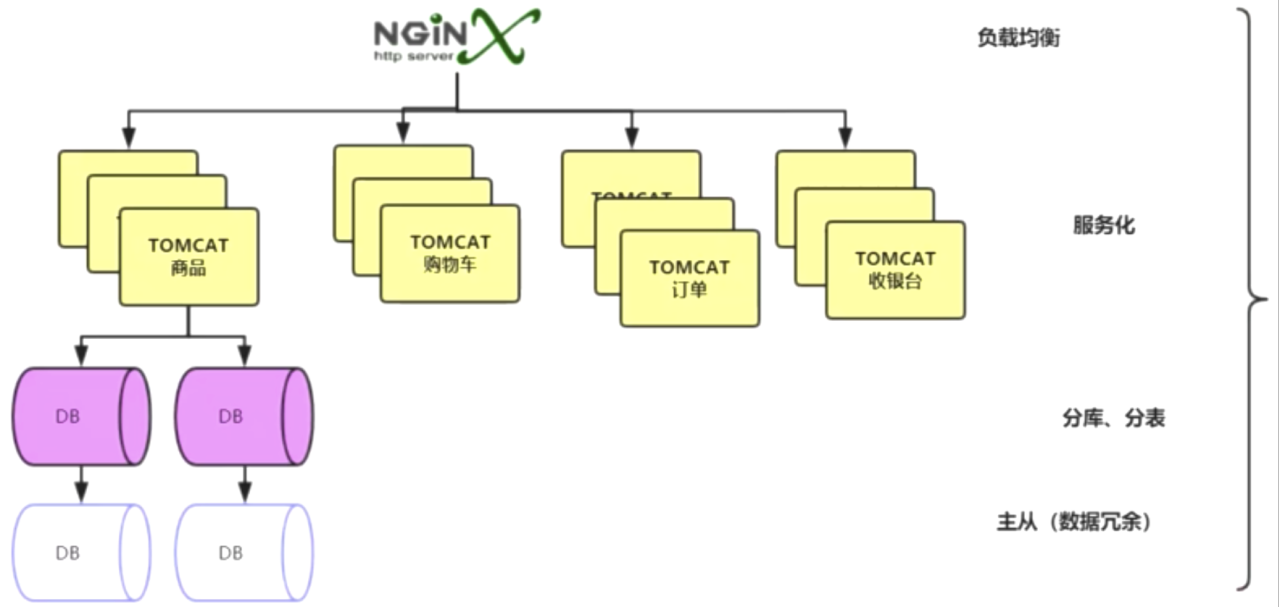
而我们的ElasticSearch也是一样的集群部署。
1、集群 cluster
一个集群就是一个或多个节点组织在一起,他们共同持有整个库的数据,并在一起提供索引和搜索功能,一个集群由一个唯一的名字表示。所有节点通过这个集群名字,来进入这个集群。
2、节点node
一个节点是由集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。
3、分片和复制 shard & replicas
3.1、分片
一个索引可以存储超过单个节点硬件限制的大量数据,比如说一个索引具有10亿文档,占据1T的磁盘空间,而任意一个节点都没有这样大的一个磁盘空间;或者单个节点处理搜索请求,响应太慢了,为了解决这个问题,ElasticSearch提供了将索引划分为多份的能力,每一份就叫做一个分片。当建立一个索引的时候,可以指定想要分配的分片数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要体现在两方面:
- 允许你水平分割/扩展你的内容容量。
- 允许你在分片之上进行分布式并行操作,从而提高性能和吞吐量
至于分片怎么分布,查询结果怎么聚合,完全由elasticsearch管理的。开发者不需要关心。
3.2、复制
在网络环境或者说分布式环境中,通讯发生失败是常有的事,所以当某个分片节点出现故障,故障转移机制是非常有必要的。因此Elasticsearch允许你创建分片的一份或者多份拷贝,这些拷贝叫做复制分片,或者就叫复制。
复制的存在提高了节点出现故障时的集群高可用性。因为这个原因,复制分片应注意与主分片不能在同一个节点上。
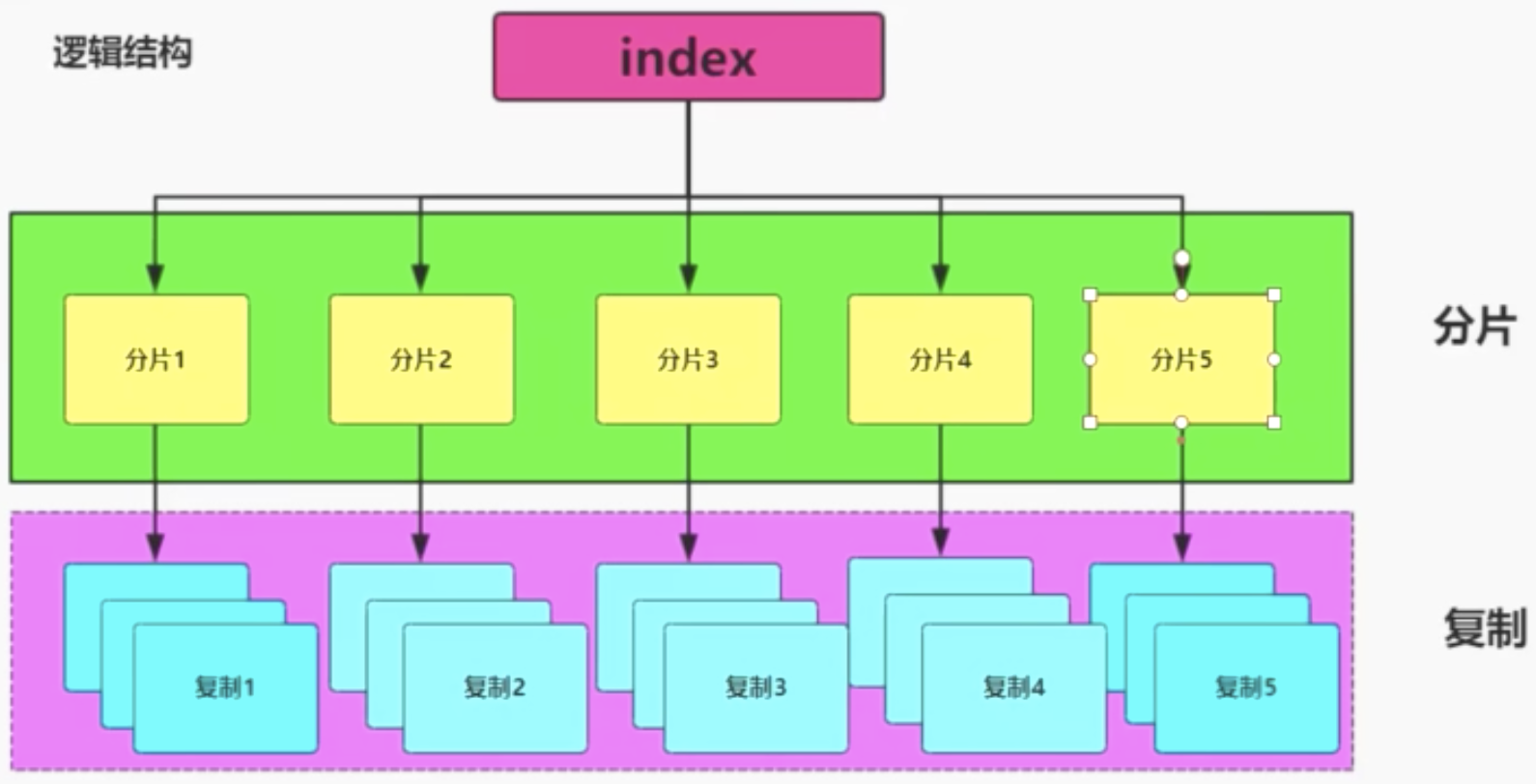
总结的说,一个索引可以被分为多个分片,可以被复制0~N次,一旦复制了就有了主分片和复制分片之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,复制的数量可以改变,但是分片数量不能改变。
分片和复制逻辑结构:
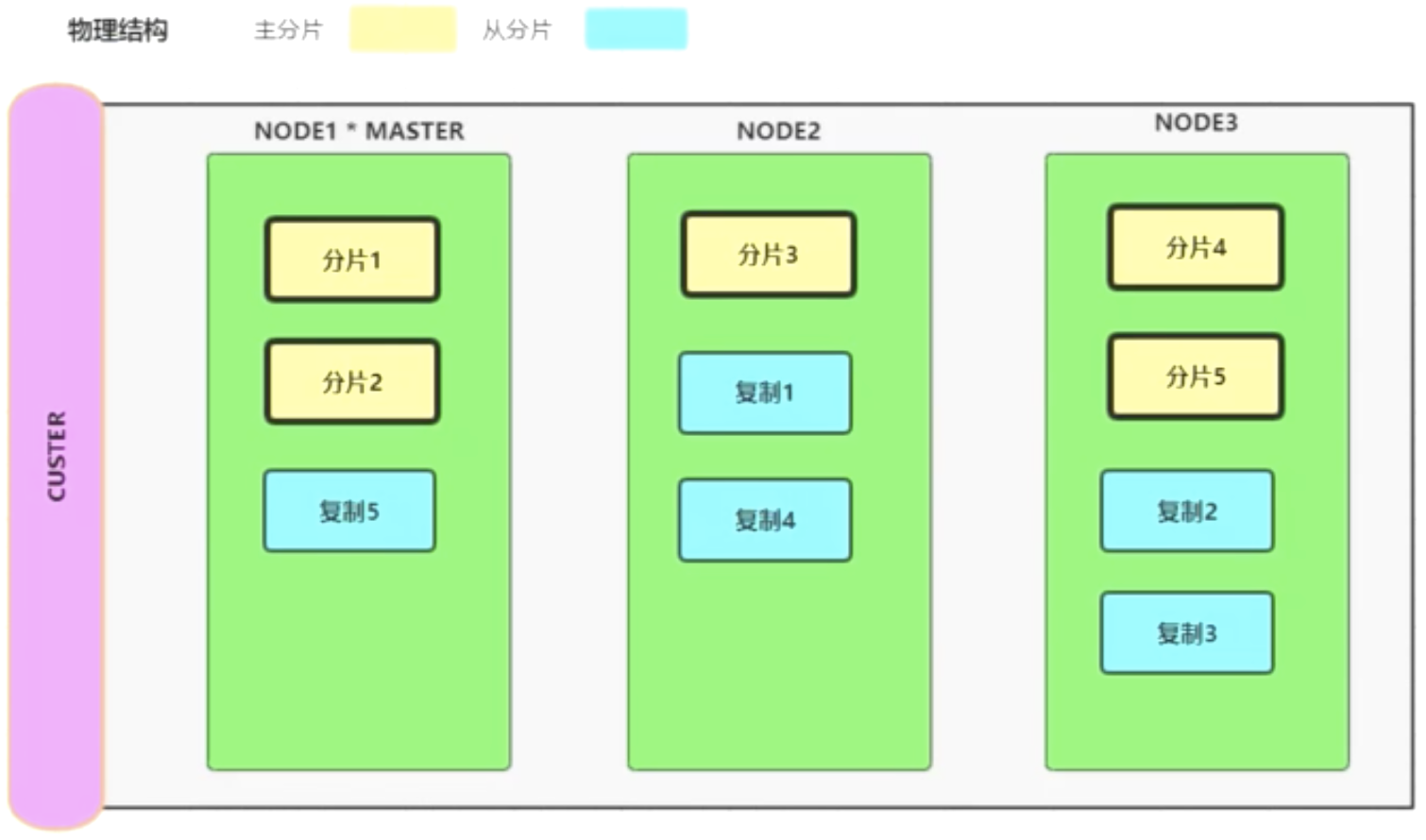
物理结构:
4、集群搭建
对于一个新建的节点需要保证安装目录的data目录为空,修改 elasticsearch.yml 配置文件(注意冒号后面的空格)。
#集群名称 cluster.name: my-elasticsearch #节点名称,不同的节点名称必须不一样 node.name: node-1 # 是否可以成为master节点 node.master: true #必须为本机的ip地址 network.host: 127.0.0.1 #服务端口,在同一机器下必须不一样 http.port: 9201 #集群间通讯端口号,在同一机器必须不一样 transport.tcp.port: 9301 #集群节点 discovery.seed_hosts: - 127.0.0.1:9301 - 127.0.0.1:9302 - 127.0.0.1:9303 #集群中的主节点 cluster.initial_master_nodes: - 127.0.0.1:9301
不同节点注意修改节点名称、服务端口、通讯端口、以及是否可以成为主节点属性,修改完毕后依次启动不同节点服务。
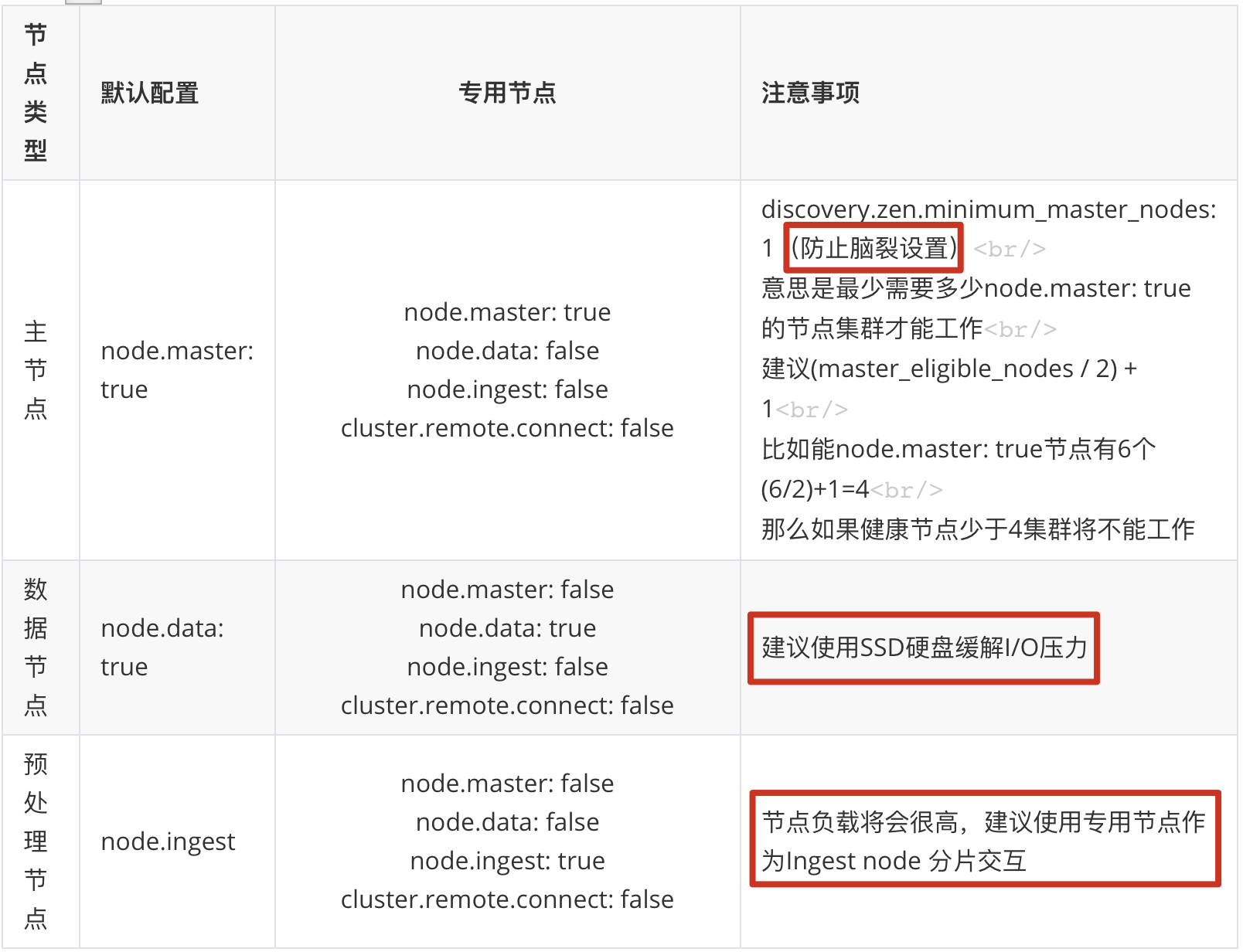
5、节点的3中类型
5.1、主节点
即 Master 节点。主节点的主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。稳定的主节点对集群的健康是非常重要的。默认情况下任何一个集群中的节点都有可能被选为主节点。索引数据和搜索查询等操作会占用大量的cpu,内存,io资源,为了确保一个集群的稳定,分离主节点和数据节点是一个比较好的选择。虽然主节点也可以协调节点,路由搜索和从客户端新增数据到数据节点,但最好不要使用这些专用的主节点。一个重要的原则是,尽可能做尽量少的工作。
5.2、数据节点
即 Data 节点。数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对 CPU、内存、IO 要求较高,在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
5.3、预处理节点
也称作 Ingest 节点,在索引数据之前可以先对数据做预处理操作(如:函数运算、类型转换等),所有节点其实默认都是支持 Ingest 操作的,也可以专门将某个节点配置为 Ingest 节点。
以上就是节点几种类型,一个节点其实可以对应不同的类型,如一个节点可以同时成为主节点和数据节点和预处理节点,具体的类型可以通过具体的配置文件来设置。
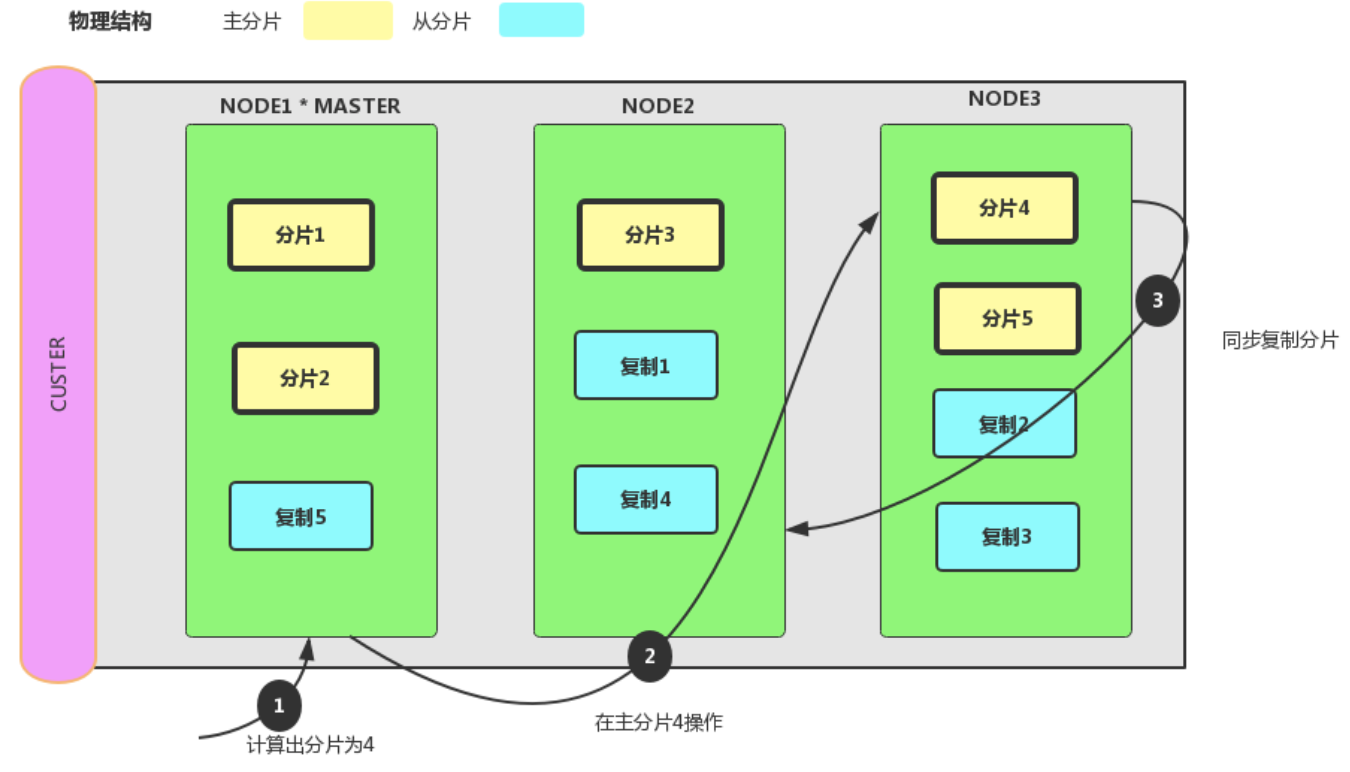
6、分片交互
我们能够发送请求给集群中任意一个节点。每个节点都有能力处理任意请求。每个节点都知道任意文档所在的节点,所以也可以将请求转发到需要的节点。下面的例子中,我们将发送所有请求给`Node 1`,这个节点我们将会称之为请求节点(requesting node)。 当我们发送请求,最好的做法是循环通过所有节点请求,这样可以平衡负载,或者借助nginx、apache等反向代理服务器进行负载。
6.1、新建、删除索引和删除文档时
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。
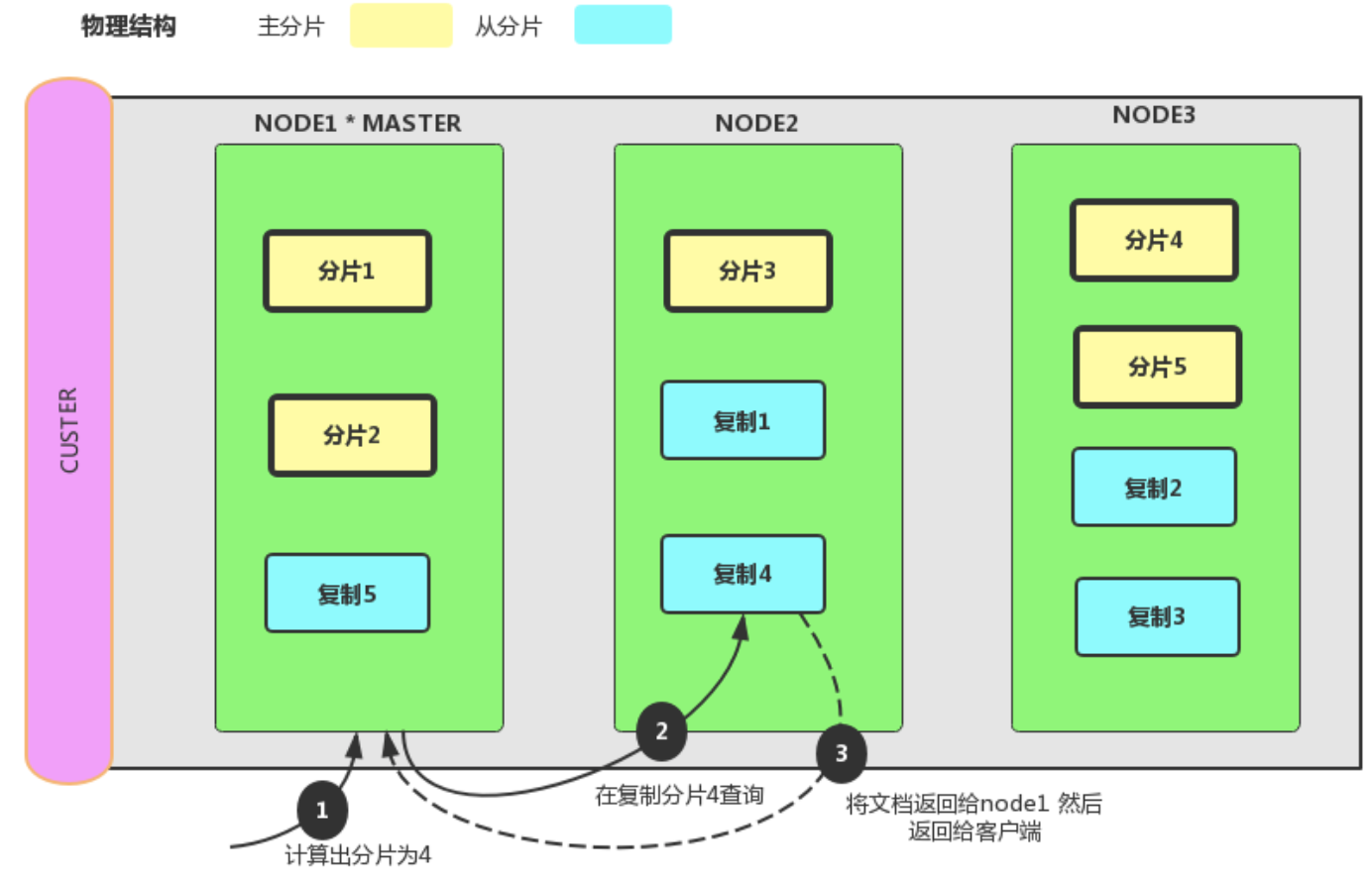
6.2、单条检索文档集群交互流程
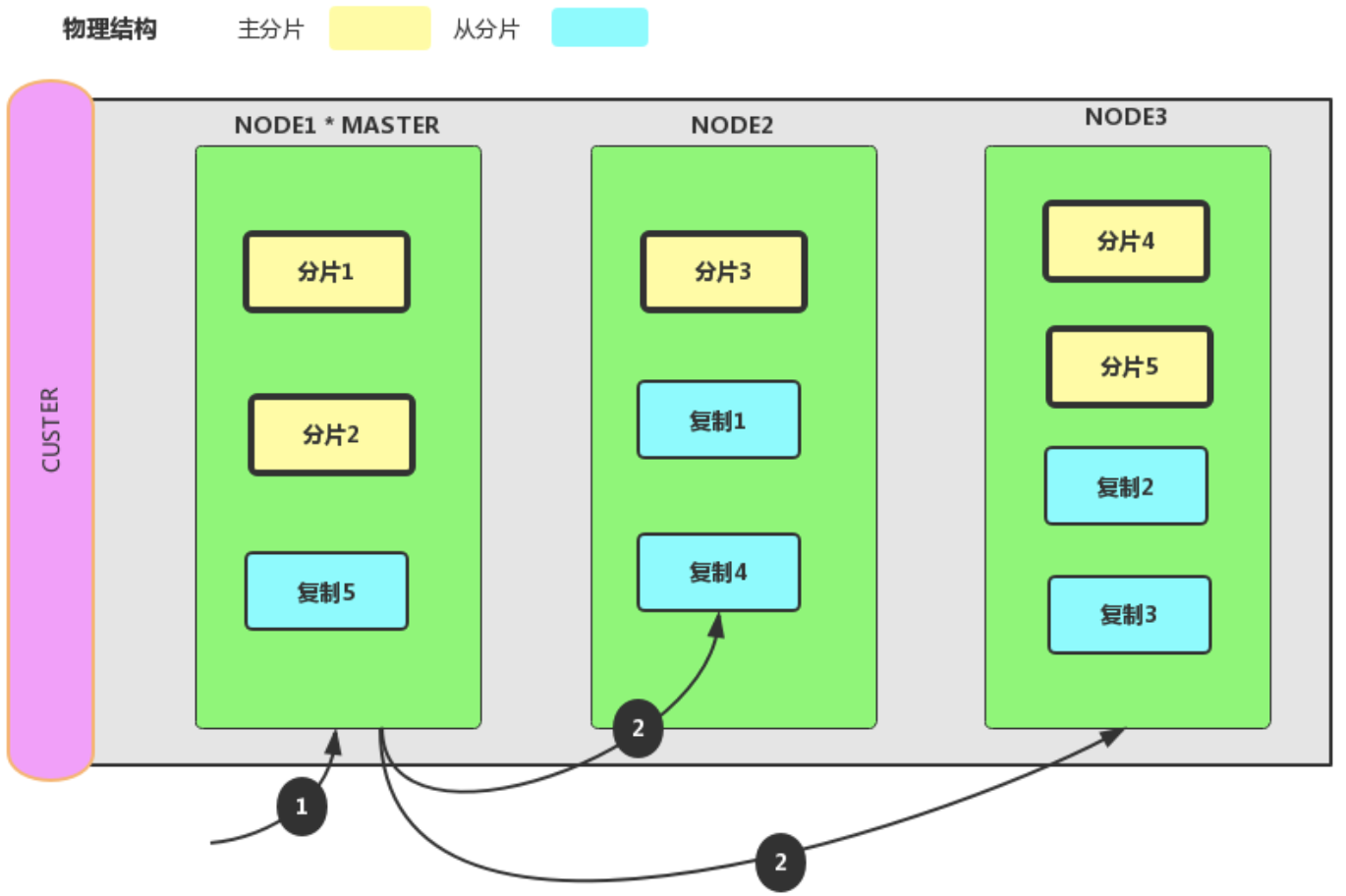
6.3、批量查询文档
请求拆成每个分片的请求,然后转发每个参与的节点。
7、集群节点自动分片及重启
我们先看启动master,然后创建索引,再启动剩余2个node节点,并在此创建一个索引,可以在elasticsearch-head看到索引的分片以及副本情况如下:
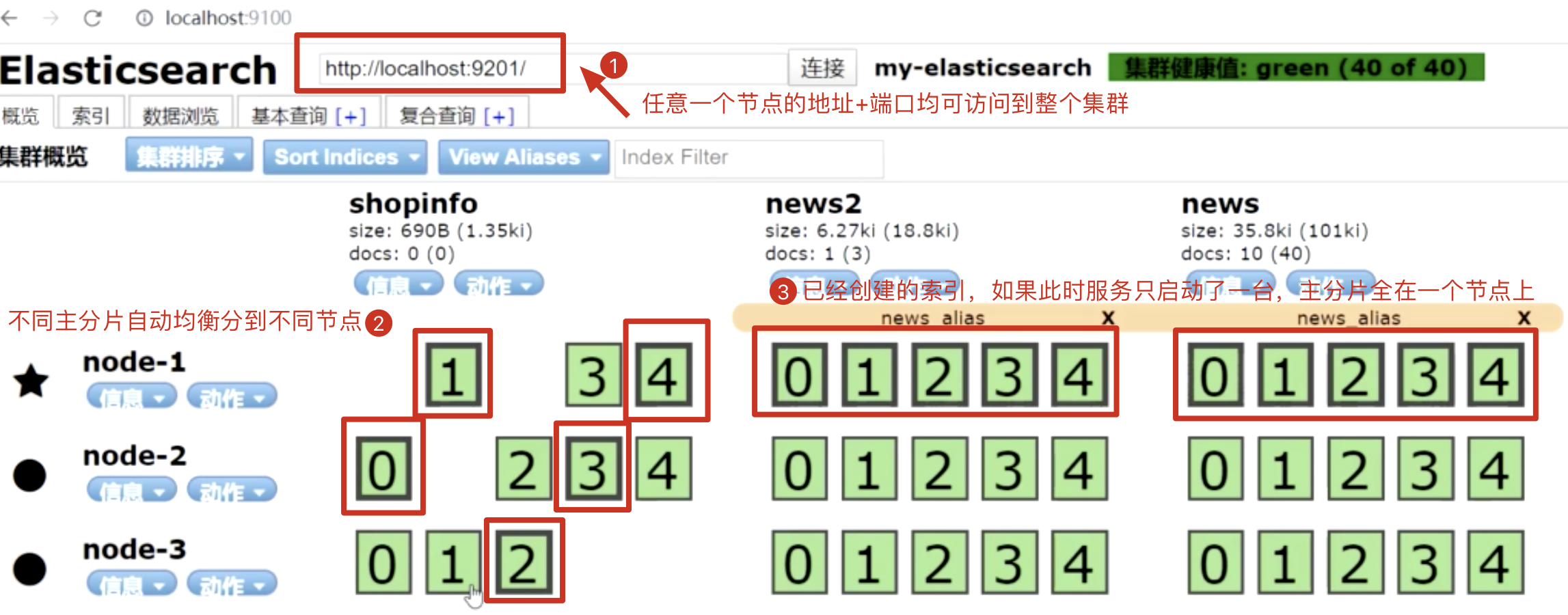
elasticsearch集群的高可用和自动平衡方案会在节点挂掉(重启)后自动在别的节点上复制该节点的分片,这将导致大量的IO和网络开销。
如果离开的节点重新加入集群,elasticsearch为了对数据分片(shard)进行再平衡,会为重新加入的节点再次分配数据分片(shard),当一台ES因为压力过大而挂掉以后,其他的ES服务器会备份本应那台ES保存的数据,造成更大的压力,于是造成整个集群会发生雪崩。因此生产环境下建议关闭自动平衡:
cluster.routing.rebalance.ennable: none
可以设置延迟副本重新分配机制:
index.unassigned.node_left.delayed_timeout: 5m
还可以指定集群节点到达多少数量才开始平衡:
gateway.recover_after_nodes: 8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号