
一、Redis使用有哪些常见问题
在我们已经有了Jedis客户端、集群模式支持后,Redis基本使用已经没有大的问题了。关于Jedis以及集群模式请参考博文:
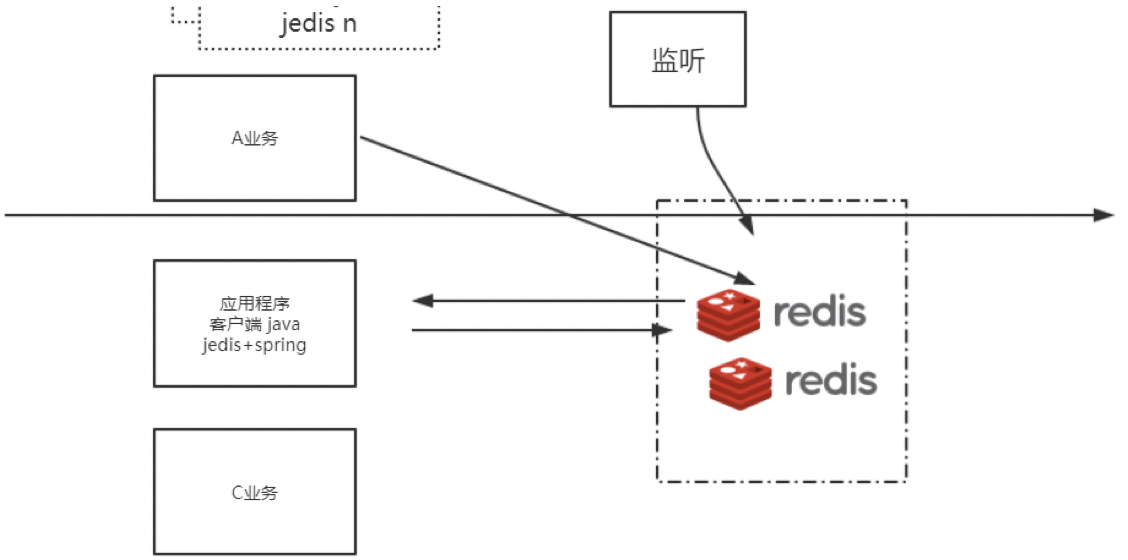
但是这样依旧有很多缺陷,比如:
- 动态扩容不方便,扩容需要重启才能生效
- 对于集群配置,有客户端代码侵入
- 集群中没有业务进行隔离,单业务冲高可能影响其余业务运行
- 没有监控,无法提前预估风险
- 不能解决缓存穿透以及缓存雪崩问题
二、Redis解决方案项目简述
在上面的问题中,有一个开源项目有很好的参考作用,项目地址:https://gitee.com/ym-monkey/flasher
1、这个主要解决了什么
- 1、基于Jedis Cluster开发的客户端支持Redis Cluster集群。
- 2、对被调用方(客户端)侵入极少,上手极快。
- 3、支持动态增加节点,客户端自动感知。(zookeeper)
- 4、支持客户端验证与拦截。 (token)
- 5、异步监控调用数据,支持异步上报。
- 6、方便管理有效的区分业务系统。会员(memmber) 商品(goods)
- 7、支持Falcon协议. 监控系统。(Open-Falcon小米开源项目:监控展示)
- 8、国内一线互联网公司上线项目
2、项目结构是怎样的
结构图如下:
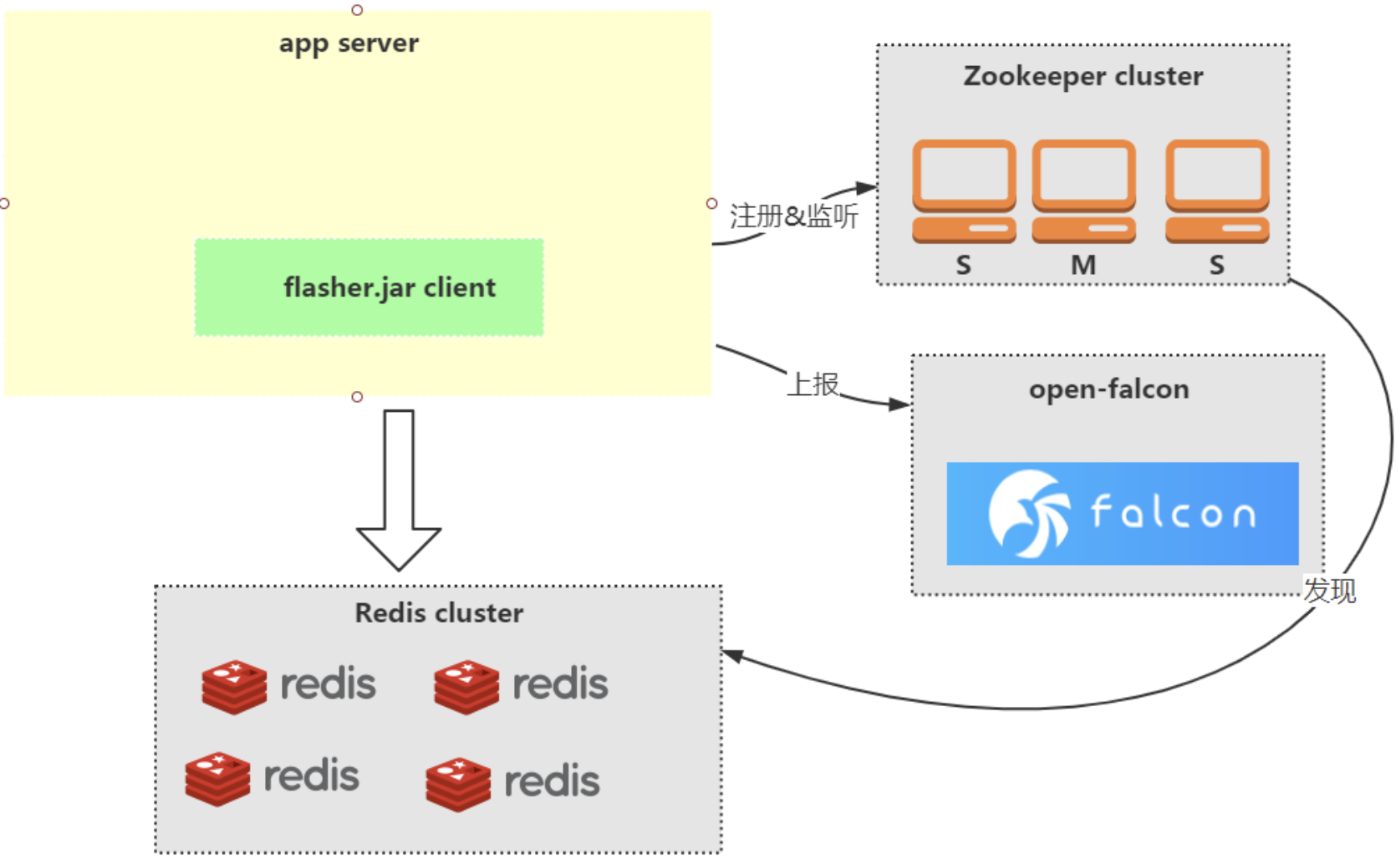
3、项目目录结构及入口
包结构如下:
- Enums:枚举类型
- Impl:实现功能,具体实现了rediscluster和redis的命令
- Jedis:封装jedis操作
- Monitor:方法拦截、数据存储、数据上传
- Spring:对redis集群实列管理
- Utils:工具类
- Zookeeper:动态感应集群变动
关键入口如下:
- 使用调用:IRedis>RedisImpl>RedisClusterImpl(业务隔离)
- 收集数据:bat.ke.qq.com.flasher.monitor.interceptor.MonitorInterceptor(监控数据整理)、bat.ke.qq.com.flasher.monitor.job.MonitorJob(监控数据上报)
- 定时任务(上报内容):MonitorQuartzJob>ScheduledExecutor>ScheduledQuartz(监控定时上报管理)
- 高可用集群管理:bat.ke.qq.com.flasher.spring.RedisClusterConnectionVHFactory
三、部分代码思想详解
1、业务隔离
在这个项目里是实现了业务隔离的,其隔离方式就是对Key进行格式化,如 com.tl.flasher.impl.RedisClusterImpl 以及 com.tl.flasher.impl.RedisImpl 这两个基于集群、非集群的二次包装的Jedis API:
@Override public String hget(String business, String key, String field) { return getJedisCluster().hget(RedisUtil.buildKey(getBusiness(business), key), field); } @Override public Map<String, String> hgetAll(String business, String key) { return getJedisCluster().hgetAll(RedisUtil.buildKey(getBusiness(business), key)); }
其ID都进行了二次build,其二次build实现如下:
public static String buildKey(String business,String key){ return new StringBuilder(business).append(Constants.DEFAULT_SEPARATOR).append(key).toString(); } public static String buildKeys(String business,String ... keys){ StringBuilder sb = new StringBuilder(business).append(Constants.DEFAULT_SEPARATOR); for(String key : keys){ sb.append(key); } return sb.toString(); } public static byte[] buildKey(String business,byte[] key){ byte[] busi = (business + Constants.DEFAULT_SEPARATOR).getBytes(); byte[] bytes = new byte[busi.length + key.length]; System.arraycopy(busi, 0, bytes, 0, busi.length); System.arraycopy(key, 0, bytes, busi.length, key.length); return bytes; }
因此就实现了业务简单隔离。
2、高可用集群动态管理
这一部分就用到了zookeeper,以及InitializingBean。首先看加载bean的InitializingBean,如代码其获取集群或者非集群Redis客户端的时候继承了InitializingBean:
public interface IRedisClusterConnection extends InitializingBean, DisposableBean { JedisCluster getJedisCluster(); String getBusiness(); }
在具体的实现类,提供了三个方法,分别是首次初始化 afterPropertiesSet方法,二次更新的refresh方法以及销毁的destory方法:
@Override public void afterPropertiesSet() throws Exception { //继承自InitializingBean Assert.hasText(hostPort); Assert.hasText(business); hostGroups = new GedisGroups(hostPort,getBusiness()); hostGroups.addChangeListner(new DataChangeListener()); List<String> hostPs = hostGroups.getValues(); Set<HostAndPort> hostAndPorts = Sets.newHashSet(); for(String s : hostPs){ String[] ss = s.split(":"); hostAndPorts.add(new HostAndPort(ss[0], Integer.valueOf(ss[1]))); } if(null == jedisCluster){ if(null == jedisPoolConfig){ jedisPoolConfig = new JedisPoolConfig(); } jedisCluster = new JedisCluster(hostAndPorts,timeout,maxRedirections,jedisPoolConfig); } LOGGER.info("RedisClusterConnectionVHFactory is running!"); } private void refresh(){ //refresh:刷新配置 List<String> hostPs = hostGroups.getValues(); Set<HostAndPort> hostAndPorts = Sets.newHashSet(); for(String s : hostPs){ String[] ss = s.split(":"); hostAndPorts.add(new HostAndPort(ss[0], Integer.valueOf(ss[1]))); } JedisCluster newjedisCluster = new JedisCluster(hostAndPorts,timeout,maxRedirections,jedisPoolConfig); jedisCluster = newjedisCluster; LOGGER.info("RedisClusterConnectionVHFactory.refresh() running!"); } @Override public void destroy() throws Exception { //继承自DisposableBean if(null != jedisCluster){ jedisCluster.close(); } jedisCluster = null; LOGGER.info("RedisClusterConnectionVHFactory.destroy() is running!"); }
那么刷新配置在什么时候用呢?
private class DataChangeListener implements ZkListener{ @Override public void dataEvent(WatchedEvent event) { // TODO Auto-generated method stub if(event.getType() == EventType.NodeChildrenChanged || event.getType() == EventType.NodeDataChanged){ refresh(); } } }
这个监听是在初始化的时候就添加了的,当zookeeper检测到节点变动时,就会自动更新集群信息,实现高可用。然后zookeeper的管理就在目录zookeeper下,需要自行查看。
3、监控数据整理与上报
ScheduledService接口定义了两个方法:startJob和shutdown。
public interface ScheduledService { void startJob(Map<String,Object> context,int intervalInSeconds); void shutdown(); }
然后具体实现如下:
public class ScheduledExecutor implements ScheduledService { private ScheduledExecutorService service = Executors.newScheduledThreadPool(2); @Override public void startJob(Map<String,Object> context,int intervalInSeconds) { MonitorExecutorJob job = new MonitorExecutorJob(context); service.scheduleAtFixedRate(job,0,intervalInSeconds,TimeUnit.SECONDS);//start run task } @Override public void shutdown() { if(null != service){ service.shutdown(); } service = null; } }
然后会调用这个定时的执行的线程池就会调用方法执行:
public class MonitorJob { private static final Logger LOGGER = LoggerFactory.getLogger(MonitorJob.class); public static void doJob(Map<String,Object> map){ MonitorPushTypeEnum mPushType = (MonitorPushTypeEnum) map.get(Constants.MONITOR_PUSH_TYPE_NAME); AbstractProtocol protocol = (AbstractProtocol) map.get(Constants.MONITOR_PROTOCOL_NAME); String host = (String) map.get(Constants.MONITOR_HOST_NAME); Integer port = (Integer) map.get(Constants.MONITOR_PORT_NAME); List<Serializable> datas = null; if(null != protocol && null != (datas = AbstractProtocol.buildLocalData(protocol)) && !datas.isEmpty()){ String result = null; try { Gson gson = new Gson(); switch (mPushType){ case HTTP_ASYN: result = HttpUtil.doPostAsyn(host,gson.toJson(datas)); //HTTP异步 break; case HTTP_SYNC: result = HttpUtil.doPostSync(host, gson.toJson(datas)); //HTTP同步 break; default: } } catch (Exception e){ e.printStackTrace(); LOGGER.error(e.getMessage()); } LOGGER.info("post "+ host + port +",result is " +result); } // 清除本地内存数据 AbstractProtocol.clearLocalData(); } }
那么触发数据记录的地方是哪儿呢:
<bean id="monitorInterceptor" class="bat.ke.qq.com.flasher.monitor.interceptor.MonitorInterceptor" /> <bean id="autoProxyCreator" class="org.springframework.aop.framework.autoproxy.BeanNameAutoProxyCreator"> <!-- 设置目标对象 --> <property name="beanNames"> <list> <value>redisCluster</value> </list> </property> <!-- 代理对象所使用的拦截器 --> <property name="interceptorNames"> <list> <value>monitorInterceptor</value> </list> </property> </bean>
这个拦截器就进行了监控数据的准备:
public class MonitorInterceptor implements MethodInterceptor { @Override public Object invoke(MethodInvocation methodInvocation) throws Throwable { //调用目标方法之前执行的动作 // System.out.println("调用方法之前: invocation对象:[" + methodInvocation + "]"); long beginTime = System.currentTimeMillis(); //调用目标方法 Object rval = methodInvocation.proceed(); long endTime = System.currentTimeMillis(); StringBuilder methodFullName = new StringBuilder("["); methodFullName.append(methodInvocation.getMethod()); methodFullName.append("]"); String usedNumName = methodFullName + Constants.DEFAULT_SEPARATOR + Constants.MONITOR_GEDIS_USED_NUM_NAME; String usedTimeName = methodFullName + Constants.DEFAULT_SEPARATOR + Constants.MONITOR_GEDIS_USED_TIME_NAME; Integer usedNum = Constants.MONITOR_MAP.get(usedNumName); if(usedNum == null){ usedNum = 0; } usedNum +=1; //调用计数 Integer usedTime = Constants.MONITOR_MAP.get(usedTimeName); if(usedTime == null){ usedTime = 0; } usedTime += Long.bitCount(endTime - beginTime); //调用计时 Constants.MONITOR_MAP.put(usedNumName, usedNum); Constants.MONITOR_MAP.put(usedTimeName, usedTime); // System.out.println("调用方法: invocation对象:[" + methodInvocation.getMethod() + "]" // + " Run time is " + usedTime +" ms"); // System.out.println(Constants.MONITOR_MAP); //调用目标方法之后执行的动作 // System.out.println("调用结束..."); return rval; } }
以上就是监控流程,如果对接Open-Falcon开源项目工具,就可以实现图形化动态展示监控。
四、缓存雪崩与缓存穿透
关于缓存雪崩和缓存穿透,是这样两种情况:
- 缓存击穿:请求一些故意系统没有缓存的数据,于是只能走数据库查询,数据库承受不了挂了。
- 缓存雪崩:缓存都是有超时时间的,如果大量缓存同时失效,那么会在访问时大量数据只能走数据库查询再次缓存,数据库承受不了挂了。
关于解决方案:
- 事先:保证redis高可用,进行redis cluster部署,防止redis挂掉。
- 发生:本地cache+hystrix限流保证防止大量恶意访问,避免数据库mysql挂掉。
- 事后:Redis持久化,缓存挂掉可以快速恢复。
同时缓存还可以采用布隆过滤器,这样能提高缓存访问性能,提高未缓存数据的访问性能。
关于第四部分内容后续会进行项目实战补充,到时再进行详细说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号