

机器能做的事就别让人来做!
目标: 抓取特定微信公众号文章
思路:利用selenium模拟浏览器行为,进行抓取(理由:搜狗已将文章链接进行处理,且页面为动态生成)
框架:

步骤:
1、登录搜狗
a、找到登录按钮并点击
self.browser.find_element_by_id("loginbtn").click()
此时产生一个登录的iframe,其中还嵌套一个iframe,都是动态生成的,内嵌于该页面的另一个新的html页面,我们需要
定位到第二个iframe才能进行真正的登录操作
b、定位到登录界面的实际iframe
self.browser.switch_to.frame(0)
time.sleep(10)
self.browser.switch_to.frame("ptlogin_iframe") // ptlogin_iframe为实际登录界面的iframe
c、 实现qq快捷登录
利用qq实现快速登录,前提是你已登录自己的qq账号,然后在页面直接点击你的qq头像即可实现登录操作。当然,你也可以通过账号/密码实现登录。
self.browser.find_element_by_id("qlogin_list").find_element_by_xpath("a").click() // 找到你的qq头像对应的元素位置并点击
2、抓取文章
搜狗页面呈现方式:
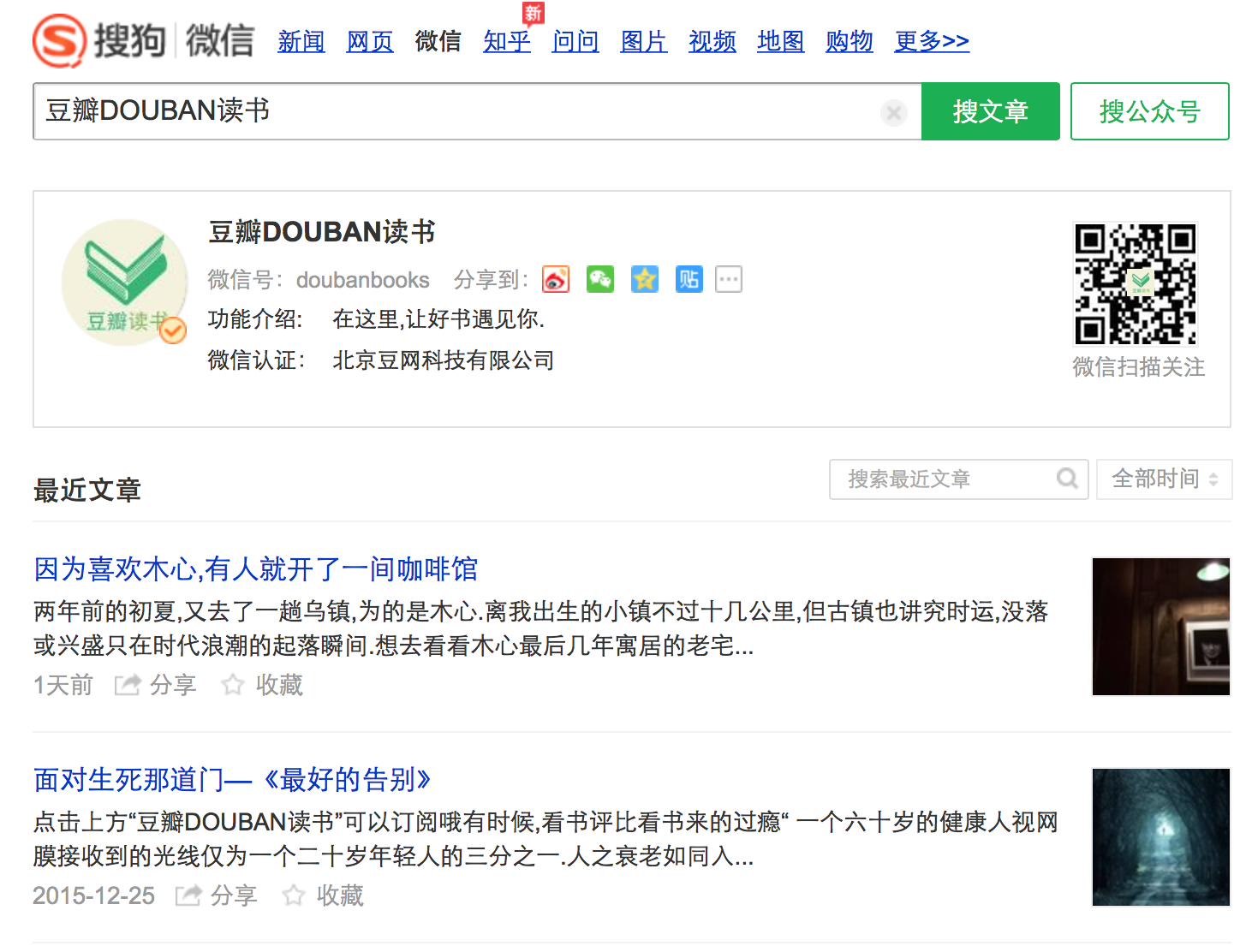
抓取数据格式:
标题, 概要信息, 发布时间, 图片url, 文章实际url
通过审查元素,我们看一下每个文章在页面源码中的表现形式,如下图:

href链接到的是文章正文页,但是该链接并非文章的实际链接地址,因此我们需要点击该链接到文章正文页面获取其真实链接。
其他元数据信息则可由页面直接获取。具体获取方法,即通过find_element定位到相应元素,获取元素text信息,此处不再
赘述。
说明一下获取文章实际url,可通过点击文章标题或图片跳转到文章页面,此时会新产生一个窗口,我们需要切换到该窗
口,才能获取到当前的窗口URL,然后再切换回原来的窗口,继续下一个文章元数据的抓取过程,具体操作如下:
1 def get_target_url(self, no): 2 """ 3 get real url(without encryption) of target page 4 :param no: NO. 5 :return target_url: 6 :Usage: 7 """ 8 box_a = self.get_box(no).find_element_by_xpath("div[@class='txt-box']//h4//a") # 找到标题元素并点击 9 current_handle = self.browser.current_window_handle # 保留当前窗口句柄 10 box_a.click() 11 for handle in self.browser.window_handles: 12 if handle == current_handle: 13 continue 14 else: 15 # 切换到文章正文窗口,获取url后关闭,并回到主窗口 16 self.browser.switch_to_window(handle) 17 target_url = self.browser.current_url 18 self.browser.close() 19 self.browser.switch_to_window(current_handle) 20 return target_url
3、抓取更多文章
初始页面默认呈现10篇文章,点击页面底部“查看更多”可获得更多文章,每次10篇,若到达最后,则不再出现“查看更多”。具体做法:
审查元素获取“查看更多”并点击,每个文章对应一个div,其ID形式如“sogou_vr_11002601_box_0”,末尾的0是编号,顺序递增,查看
更多后,可通过该ID值获取最新出现的文章。


1 def get_more(self): 2 try: 3 more = self.browser.find_element_by_class_name("p-more") 4 if more.get_attribute("style") == "visibility: hidden;": 5 return False 6 else: 7 more.find_element_by_xpath("a").click() 8 return True 9 except Exception, e: 10 print e.message
############################OVER################################
转载请注明出处!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号