
(1),关于 LinkedHashMap TreeMap HashMap 之间的区别:
HashMap 是无序的,LinkedHashMap 由于内部维护了一个记录的链表,数据操作的前后顺序都会在链表上下节点保存着;
而TreeMap 内部的数据是有序的
分析如下:
1.LinkedHashMap 我们看类结构上是实现了HashMap ,在添加元素的时候,在实现添加put 方法时候,重写了其newNode 方法,如下:
我们看HashMap newNode 方法: 就是普通的创建了一个节点对象 // Create a regular (non-tree) node Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) { return new Node<>(hash, key, value, next); } 我们再看LinkedHashMap 重写的newNode 方法: Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } //链表操作 // link at the end of list private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; tail = p; if (last == null) head = p; else { p.before = last; last.after = p; } }
我们看一看TreeMap 结构: 对于数据都要进行比较,然后再判断放到数的左边还是右边,然后进行红黑树自旋
public V put(K key, V value) { Entry<K,V> t = root; if (t == null) { compare(key, key); // type (and possibly null) check root = new Entry<>(key, value, null); size = 1; modCount++; return null; } int cmp; Entry<K,V> parent; // split comparator and comparable paths Comparator<? super K> cpr = comparator; if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } else { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { parent = t; cmp = k.compareTo(t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else return t.setValue(value); } while (t != null); } Entry<K,V> e = new Entry<>(key, value, parent); if (cmp < 0) parent.left = e; else parent.right = e; fixAfterInsertion(e); size++; modCount++; return null; }
(2).java 类加载器,以及委托机制
java 类加载器分为引导,扩展,系统 三类类加载器 引导类加载器主要负责加载java 类库下的包,扩展类加载器主要负责加载扩展包(e x t),系统类加载器主要负责加载我们的Java 文件 以及第三方j a r包
双亲委托机制原理:
1.当系统加载器加载一个class 的时候,他自己不会自己器加载这个类,而是把这个类加载的请求交给他的父加载器(扩展加载器)ExtClassLoader 去完成;
2.到了扩展加载器加载时候,他首先也不会自己去尝试加载这个类,而是又把这个类加载请求交给你它的父加载器(引导加载器)去完成
3.然后到了引导加载器加载的时候,如果加载未找到,则会让它下级ExtClassLoader 加载;
4.如果ExtClassLoader也加载失败,则就使用系统加载器进行加载,系统记载器如果没有发现,就会抛出ClassNotFound 异常
为什么会设计这种双亲委托机制进行类的加载:
为了安全,为了防止外部恶意进行自定义java 类库的类,达到安全的作用以及优先级作用
(3).线程池:
创建线程池又如下参数需要进行配置:
corePoolSize:核心线程数
maximumPoolSize:最大线程数
keepAliveTime:线程存活的时间
workQueue:任务队列
threadFactory:线程工厂
handler:在队列满了以及线程数已经到达了最大线程数的时候,触发此handler
线程池要与数据库连接池要区别开,线程池这里的实现是如果我的Runnable 任务能够被队列一直容纳的话,线程的数量始终是核心线程的数量,只有在队列满了
之后,才会进行创建新的线程<最大线程数;这个是要注意的;
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {....}
举个例子:如下代码,只会创建两个核心线程,剩余的4个任务是放到了LinkedBlockingQueue 中;
public static void main(String[] args) { /** * 核心线程为2 * 最大线程为6 * LinkedBlockingQueue 容纳 Integer.MAX_VALUE个任务 */ ThreadPoolExecutor pool = new ThreadPoolExecutor(2, 6, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); pool.submit(()-> fs()); pool.submit(()-> fs()); pool.submit(()-> fs()); pool.submit(()->fs()); pool.submit(()->fs()); pool.submit(()->fs()); pool.submit(()->fs()); pool.submit(()->fs()); } public static void fs(){ try { Thread.sleep(1000); System.out.println(Thread.currentThread().getName()); }catch (Exception E){ } }
(4).maven 重要的使用:
1.查看项目完整的依赖数:mvn dependency:tree -Dverbose 2.查看依赖树中包含某个groupId和artifactId的依赖链 mvn dependency:tree -Dverbose -Dincludes=com.alibaba:ee-article
3.本地包打包 mvn install:install-file -Dfile=sql_parser-1.0.0.jar -DgroupId=com.cys -DartifactId=sql-parser -Dversion=4.0 -Dpackaging=jar
(5).git常用命令:
场景:在切换分支,想要保存原有分支修改未提交的文件;在切换回来的时候还原
git stash save "name": 将未提交的文件保存到仓库里并命名; git stash list :查看仓库保存的文件; git stash pop stash@{0} :仓库的文件被弹出恢复根据stash list 索引
git 版本会退:
//查看日志
git reflog --pretty=oneline
git reset --hard 目标版本号
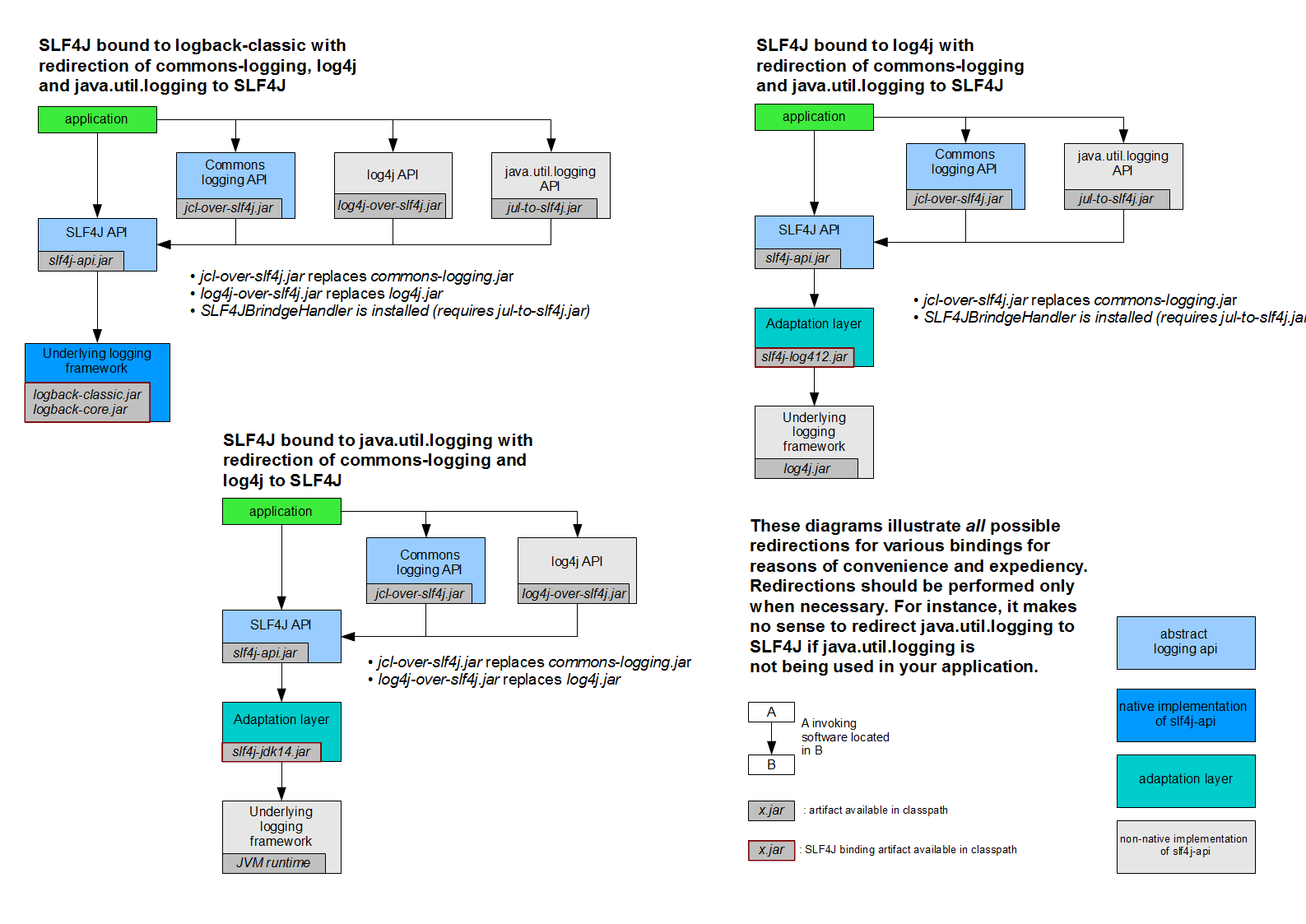
(6).SL4J 日志框架体系(使用slf4j 进行统一日志管理):
1. SLF4J 是Java 日志的门面,用于统一管理java 混乱的日志框架与项目日志框架不统一的问题,并不提供日志系统的统一实现;
2.SLF4J 的具体实现有slf4j-simple、logback,要使用log4j 需要使用slf4j-log4j12来实现slf4j;
3.jcl-over-slf4j ,log4j-over-slf4j, jul-to-slf4j 用于替换commons-logging, log4j, java util logging 原有实现;
(7) .java 默认的环境变量:
(8).Cookie 与Session 的区别见解:
http协议是无状态的,当我们开发一些有状态的接口时候,cookie 与session 弥补了这一块的能力
对于http 协议中,cookie 只是请求头当中的一个字段,与其他请求头没有多大的区别
浏览器对cookie 做了默认的支持,同时也限制了cookie ,比如同源策略,同源策略是浏览器的一种安全机制,限制的同域(相同的域名与端口)才能访问cookie 的内容,在做sso单点登录的时候,会把cookie 放到一级域名下面
session 是服务器为每一个web 用户分配的独立的状态存储空间,(后端集群中,session信息存放到redis 或者db 中)
(9).高并发大流量思路:
系统的瓶颈取决于你系统中性能最差的模块,最容易出现系统瓶颈的是io 即磁盘io 和网络io ,磁盘io 就是我们一般的调用非内存型数据库,mysql oracle 等,网络io 就是我们系统之间的rpc 调用,如何优化于架构,大致3个思路:
1.性能不够,机器来凑。
2.移花接木。 将数据的冷热进行分离,热数据放在缓存系统如redis 中,冷数据则落盘在mysql 中,对于团队秒杀等系统,常见做法就是锁以及串行无锁化(mq)
3.火影鸣人影分身。数据量很大,可以通过分库分表分实例,读写分离。
(10). Redis:
为什么速度快 : 1. redis 是纯内存的操作 2.单线程,避免了cpu 频繁切换上下文 3.IO 多路复用机制。
缓存移除策略:1.volatile-lru 设置了expire 的key ,优先删除最少使用的key。
2.allkeys-lru 所有的key 优先删除最少使用的key。
3.volatile-random 随机删除设置了expire 的key。
4. allkeys-random 所有的key 随机删除。
5. volatile-ttl expire key 的剩余时间删除。
6. noeviction 从来不删除。
7.volatile-lfu :expire key 频繁使用删除。
8.allkeys-lfu :所有key 频繁使用删除
(11). zookeeper:
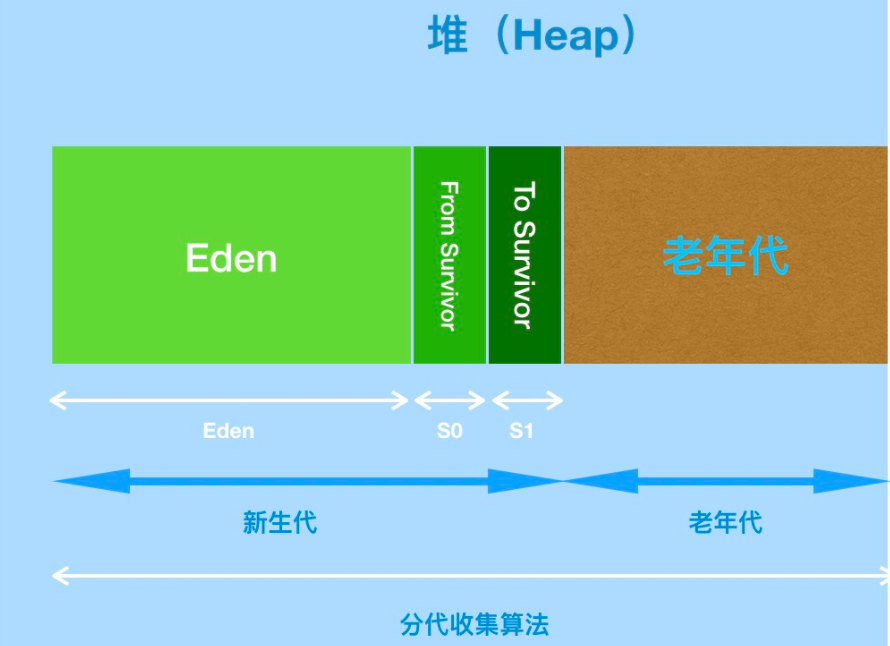
(12). 1.8 HotSpot jvm:
1.jvm 从内存整体分为堆内存,元数据区和栈 三大块内容,堆内存是JVM 最大的一块有新生代和老年代组成,新生代又被分为Eden ,From Survivor ,TO Survivor 组成。
2. java 8 版本后移除了永久带,被元数据空间所替代,字符串常量池,静态变量等信息放入了堆中,元数据空间在本地内存中,,大小不受 jvm 的影响,而是受本地内存大小的影响。
(13).jvm 常用的诊断命令:
1.jstat :查看jvm当前的一些内存以及gc 情况。
2.jstack : 查看程序线程运行的信息。
(14). AQS (队列 state CAS ) :
1. 抽象队列同步器,是JUC 并发工具类都是基于AQS 实现的,比如CountDownLatch lock 等实现。
2. AQS 通过内置的FIFO双向队列来完成线程的排队工作的,每一个任务都是一个Node 节点,节点中用waitStatus 表示线程的状态, 节点中标示了head 节点以及tail 节点,通过cas的操作来比较替换head 以及tail 节点来完成工作。
3. AQS维护了一个state 状态值,通过cas 的操作进行获取以及修改这个值的状态,比如CountDownLatch 就是操作这个state 进行计数的,重入锁通过这个状态值进行锁的重入操作。
4. 采用 LockSupport.park 以及unpark 的操作进行线程的阻塞与放行操作。
(15).CAS 含义与意义:
CAS : compareAndSwap ,比较并交换,基于冲突检测的乐观并发策略,要求操作与冲突检测两个步骤需要有原子性,不可分割,靠硬件来实现这种原子操作,依赖的是硬件指令级的发展。不管风险,先进行操作,如果没有其他线程争用共享数据,那操作就成功了,如果共享数据的确被争用,产生了冲突,进行补偿的措施,最常用的补偿措施是不断的重试。
CAS 指令需要三个操作数,内存位置(变量地址),旧的预期值,准备设置的新值;不断尝试将一个新的值赋给自己,如果失败了,说明执行CAS 操作的时候,旧值已经发生改变,于是在此循环进行下一次操作,直到成功;
(16).分布式事物:
(17).数据库主键索引与普通索引的区别:
(18).索引失效的场景:
(19).诊断sql:
(20)linux :
(21) 分布式锁:
分布式锁具备的条件: 1.高可用的获取锁与释放锁 2.高性能的获取锁与释放锁 3.分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行到 4.具备可重入性 5.具备锁的失效机制,防止死锁 6.具备非阻塞的特性.没有获取锁直接返回获取锁失败
实现方案:
1. 数据库锁的方式:
通过建立唯一索引的方式,在多个请求同事提交到数据库,数据库保证只会有一个操作可以成功。
但是失效时间需要自己去编码,否则会导致其他线程无法获取到次锁 ,强依赖数据库,一旦数据库挂掉,整个业务不可用。
2.redis 锁方式(目前常用redisson):
通过设置key 以及失效时间的方式进行实现redis 锁,且redis 设置key 以及失效时间是同步原子方式一起执行的。
3.zookeeper 锁的方式:
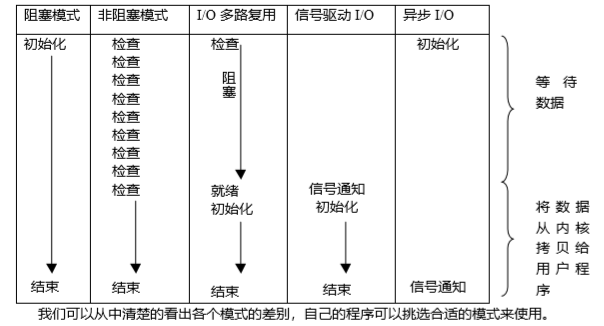
(22).IO 多路复用:
多路指的是多个网络连接,复用指的是复用一个或更少的线程,可以让单个线程高效的处理多个连接请求,使用 系统 select poll epoll 进行管理多个网络请求,高级之处在于可以同时等待多个文件描述符,这些文件描述符其中的人一个进入读就绪状态,select() 函数就返回了。
select poll epoll 区别(https://www.cnblogs.com/zhaodahai/p/6831456.html):
select 默认支持的文件描述符有限制,poll 没有最大文件描述符的限制 ,select 与poll(链表) 需要不断的轮询文件描述符,线性扫描,且需要将文件描述符信息从用户态往内核态拷贝一次。
epoll 则使用的是事件通知型的机制,通过callback 机制来激活文件描述符,非轮询的方式,只有活跃可用的文件描述符才会进行回调,只管活跃连接,跟连接总数无关。
(23). Spring 的 理解:
1 .Spring 运行首先先创建一个ApplicationContext 容器
2. 容器里维护了一个BeanFactory,这个BeanFactory 维护了Spring 运行中所有的bean实例对象,每一个bean 都有一个BeanDefinition 来描述类的信息,进行后续初始化。
3. bean 的注册主要是通过实现 BeanFactoryPostProcessor 以及 BeanDefinitionRegistryPostProcessor 工厂钩子函数来实现自定义bean 的注册和修改,比如 ConfigurationClassPostProcessor spring 重要的注册bean 处理器,实现了包扫描,@bean @import 等bean 注册操作 完成了基本 90%的bean 的定义,我们定义的工厂处理器都是基于此进行扩展的。
4. bean 属性注入以及AOP 实现主要是通过实现 BeanPostProcessor 以及扩展接口来实现的,我们可以通过这个工厂钩子来进行bean 的修改,属性注入等操作,比如AutowiredAnnotationBeanPostProcessor , CommonAnnotationBeanPostProcessor 后置处理器,来完成@Autowrized,@Value 注入 ,@PostConstruct 等操作。
5.通过实现 FactoryBean 可以让我们自定义 bean 的创建,真实的bean 对象通过getObject() 方法返回,通过这一特性可以实现接口的动态代理功能,比如mybatis 接口的动态代理以及dubbo reference 接口代理实现都是依赖这一特性来实现的。
(24) .Mybatis 的理解:
1. Mybatis 通过 xml 解析技术进行解析我们的mapper 文件,解析后的对应关系全部放在Mybatis 维护的Configuration 容器中,并构造出 SqlsessionfFactoryBean。
2.基于spring 包扫描的扩展进行自定义自己的包扫描策略,通过实现FactoryBean 的 MapperFactoryBean 来实现接口的动态代理与Congiguration 容器配合使用。
3.Mybatis 一二级缓存机制,一级缓存默认是开启的,是基于 sqlSession (线程级别) 级别的缓存,随着sqlSession 销毁而不存在,二级缓存是基于Mapper(一个接口对应一个mapper) 级别的缓存;
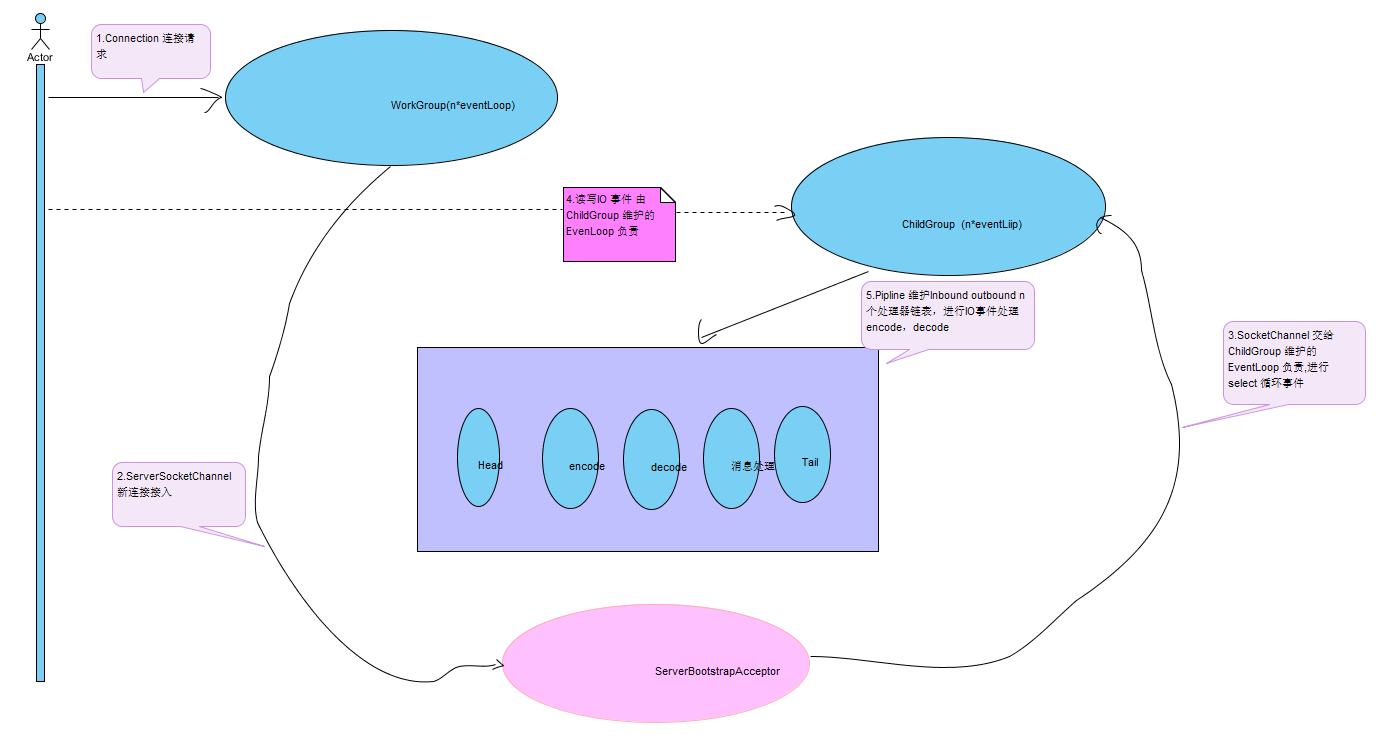
(25). Netty 的理解:
1. 理解 Netty 需要理解Reactor 模式,Netty 服务端的执行是 bossGroup 以及 childGroup 协调完成的,每个线程都是一个EventLoop 都维护着自己的Selector 进行循环 select 处理事件。
2. NioEventLoop select 事件循环基本每一个操作系统都会支持,EpollEventLoop 是基于Linux 平台独有的,基于文件描述符(fd)进行事件的循环驱动,可以通过os.name 来编码判断选择使用的EventLoop 。 EpollEventLoop 的性能会更优一些,在连接数量多的场景。
3. bossGroup 工作主要就是监听连接事件,一旦有新的连接接入(ServerBootstrapAcceptor),则会递交给childgroup 来进行后续的io 事件处理。
4.事件的处理器都会放入pipeline 中,分为 inbound 处理器,outbound 处理器,分别处理读操作以及写的操作。pipeline 是一个链表结构,头节点以及末尾节点的handle Netty 已经帮我们实现,handle 的执行严格按照链表的顺序进行执行。
5.Netty 的编解码器,所谓的编码就是在服务端我们需要传递的数据进行编码成 byteBuf,来进行底层传输,解码就是在客户接受端将 byteBuf 转换成为我们需要的数据格式,具体的数据结构有自己来定义,只需要解决的是网络传输的拆包与粘包(一般通过自定义头头方式进行解决)。
(26). 数据库分库分表:
垂直分表;拆分表的字段,冷热数据进行拆分到不同的表中。
垂直分库:根据业务类型,把不同业务的表分配到不同的数据库中。
水平分表:将表的数据拆分成若干个小表。
水平分库:将表的数据拆分成若干个小表放到不同的数据库中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号