

xml 解析方式有两种: dom 解析和 sax 解析;
针对着两种解析方式,有三种解析器:
sun公司的 jaxp
dom4j 组织的 dom4j
jdom 组织的 jdom
dom 解析XML :
缺点:文件全部加载进内存,容易造成内存溢出
优点:很容易进行增删改操作
----------------------------------jaxp 解析xml---------------------------------
jaxp 解析器在 jdk的 javax.xml.parsers 包中;
针对dom 解析提供的类 :
1.DocumentBuilder :解析器类
是一个抽象类 :通过 DocumentBuilderFactory.newDocumentBuilder() 方法获取
2.DocumentBuilderFactory: 解析器工厂
是一个抽象类 :通过newInstance() 获取实例
获取上下文Document 对象:
//obtain 工厂对象 DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); //obtain DocumentBuilder via DocumentBuilderFactory DocumentBuilder docBuilder = factory.newDocumentBuilder(); File file = ResourceUtils.getFile("springTest/beandefiniition.xml");
//可以是一个XML文件,也可以是一个输入流 Document parse = docBuilder.parse(file);
查找元素:(与js 差不多,不进行举例)
NodeList elementsByTagName = parse.getElementsByTagName("bean");
----------------xpath 的使用--
Xpath 是用来方便我们快速找到我们需要节点的超便捷工具,如何定义呢创建一个Xpath 对象呢?
XPathFactory factory = XPathFactory.newInstance();
XPath xpath = factory.newXPath();
XPath返回的数据类型:
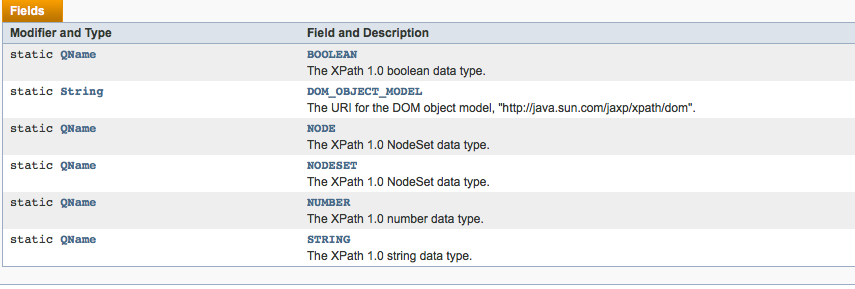
那么怎么利用Xpath 去定位我们的元素呢?
方法: Object evaluate(String expression, Object item, QName returnType);
expression:表达式;
item:开始的上下文,可以说document ,也可以说一个Node
returnType:返回的数据类型;参考上面的图片
/元素 -> 绝对路径去查找元素 (是以层级关系去找)
Node evaluate = (Node)xpath.evaluate("/mapper", document,XPathConstants.NODE);
//元素 -> 满足//之后的规则的元素,无论层级关系
NodeList nodeList = (NodeList) xpath.evaluate("//select",document, XPathConstants.NODESET);
元素|元素|元素 -> 查找匹配的元素
NodeList nodeList= (NodeList) xpath.evaluate("select|insert|update|delete",document, XPathConstants.NODESET);
原创打造,多多指教

 浙公网安备 33010602011771号
浙公网安备 33010602011771号