


背景:
在近两年发现更多的NVMe控制芯片把Prp算法集成到NVMe IP中,Prp越来越对Firmware不可见了,这样对新的Firmware 工程师了解Prp很不友好。
(之前有站在OS driver的角度去写Prp,今天换到device角度再次梳理Prp)
如图在NVMe Command的DW6~DW9表示Prp1和Prp2

Prp有三种算法:
a: only Prp1,data address.
b: prp1 + prp2, both data address.
c: prp1 + prp2, prp1 data address, prp2 is list.
PRP算法根据Data address start和Data length来分区使用那种算法。

下面详解三种算法:
Only prp1:当(PageSize - Prp1)<= data length, 仅使用Prp1,且Prp1 address指向data。
{eg:如图Prp1=0xBBF80218,length = 512B,===> (1000h - 218h) < 512B, 所以只是要Prp1。
由于payload = 256, 所以dev数据分三笔传输:
0xBBF80218 ~ 0xBBF80300 ----->PCIe trans 58DW data from local to 0xBBF80218
0xBBF80300 ~ 0xBBF80400 -----> PCIe trans 64DW data from local to 0xBBF80300
0xBBF80400 ~ 0xBBF80418 -----> PCIe trans 6DW data from local to 0xBBF80400
}

prp1 + prp2 both data:当(PageSize - Prp1)< data length <=(PageSize - Prp1 + PageSize), 使用Prp1和Prp2,且Prp address都指向data。

{eg:如图Prp1=0x25BA3B000,length = 8K,===> 4K < (8K) <= 8K, 所以Prp1 + Prp2都指向data。
所以数据分2笔传输:
0x25BA3B000 ----->NVMe trans 1024DW data from local to 0x25BA3B000
0x262878000 -----> NVMe trans 1024DW data from local to 0x262878000
}
prp1 data + prp2 list:当data length >(PageSize - Prp1 + PageSize), 使用Prp1和Prp2,且Prp2 address都指向list。

{eg:如图Prp1=0x262879000,length = 16K,===> 8K < (168K), 所以Prp1 都指向data, Prp2指向list。
所以数据分5笔传输:
0x262879000~ 0x26287A000-----> NVMe trans 1024DW data from local to 0x262879000
0x258B2C000~ 0x258B2C018-----> NVMe trans 6DW PRP LIST from 0x258B2C000 to local
0x26287A000~ 0x26287B000-----> NVMe trans 1024DW data from local to 0x26287A000
0x26287B000~ 0x26287C000-----> NVMe trans 1024DW data from local to 0x26287A000
0x2615B0000~ 0x2615B1000-----> NVMe trans 1024DW data from local to 0x2615B0000
从上图可以看出,不同于前两种传输方式。这种传输方式多了Prp List,在传完Prp1的数据之后,从Host取3个Prp entry,0x26287A000 、0x26287B000、0x2615B0000, 再把数据传到这三个Prp entry 地址。
}
另外讲讲IO不对齐处理:(以4K为例)
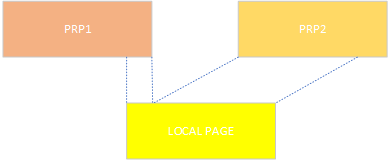
1. 地址不对齐LBA对齐,比如LBA0 ~ LBA7分布Prp1和Prp2, NVMe IP会把Prp1和Prp2数据搬到本地4K buffer。
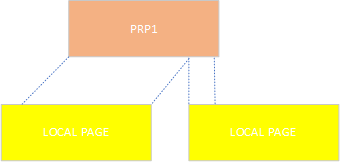
2. 地址对齐LBA不对齐,比如LBA1 ~ LBA8都在Prp1, 一般来说NVMe IP会把Prp1数据搬到本地两个4K buffer。
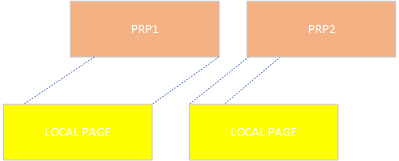
2. 地址不对齐LBA不对齐,比如LBA1 ~ LBA8都在Prp1和prp2, 一般来说NVMe IP会把Prp1和Prp2数据搬到本地两个4K buffer。
另,需要注意的是Prp address 地址以4B对齐,Prp entry以Page对齐。
本文来自博客园,作者:ingram14,转载请注明原文链接:https://www.cnblogs.com/ingram14/p/15778938.html

