
《Unix/Linux系统编程》第二周学习笔记
I/O 函数库
(fread,fwrite,fclose)与 read,write,close 系统调用之间的交互
I/O 函数库的诞生
系统调用是文件操作的基础,但他们只是支持数据块的读/写。实际上,用户程序可能希望以最适合应用程序的逻辑单元读/写文件,
如行,字符,结构化记录等,而系统调用不支持这些逻辑单元。I/O库函数是一系列文件操作函数,既方便用户使用,有提高整体效率。
I/O 函数库与系统调用
I/O 函数库数据库几乎都建立在系统调用之上。
系统调用函数:open(),read(),write(),lseek(),close();
I/O库函数:fopen(),fread(),fwrite(),fseek(),fclose();
系统调用
#include <fcnt1.h>
int main(int argc,char *argv[])
{
int fd;
int i,n;
char buf[4096];
if(argc<2) exit(1);
fd = open(argv[1],O_RDONLY);
if (fd<0)
{
exit(2);
}
while(n = read(fd,buf,4096))
{
for(i = 0;i<n;i++)
{
write(1,$buf[i],1);
}
}
}
I/O 库函数
#include <stdio.h>
int main(int argc,char *argv[])
{
FILE *fp;
int c;
if(argc < 2) exit(1);
fp = fopen(argv[1],"r");
if(fp == 0) exit(2);
while ((c = fgetc(fp))!=EOF)
{
putchar(c);
}
}
通过以上例子分析i/0库函数和系统调用之间的相似点和差别。
来源 :open是UNIX系统调用函数(包括LINUX等),返回的是文件描述符,它是文件在文件描述符表里的索引。fopen是ANSIC标准中的C语言库函数,在不同的系统中应该调用不同的内核api。返回的是一个指向文件结构的指针的指针。
移植性 :这一点从上面的来源就可以推断出来,fopen是C标准函数,因此拥有良好的移植性;而open是UNIX系统调用,移植性有限。如windows下相似的功能使用API函数CreateFile。
适用范围:open返回文件描述符,而文件描述符是UNIX系统下的一个重要概念,UNIX下的一切设备都是以文件的形式操作。如网络套接字、硬件设备等。当然包括操作普通正规文件(Regular File)。fopen是用来操纵普通正规文件(Regular File)的。
缓冲:
缓冲文件系统:缓冲文件系统的特点是:在内存开辟一个“缓冲区”,为程序中的每一个文件使用;当执行读文件的操作时,从磁盘文件将数据先读入内存“缓冲区”,装满后再从内存“缓冲区”依此读出需要的数据。执行写文件的操作时,先将数据写入内 存“缓冲区”,待内存“缓冲区”装满后再写入文件。由此可以看出,内存“缓冲区”的大小,影响着实际操作外存的次数,内存“缓冲区”越大,则操作外存的次数就少,执行速度就快、效率高。一般来说,文件“缓冲区”的大小随机器 而定。fopen, fclose, fread, fwrite, fgetc, fgets, fputc, fputs, freopen, fseek, ftell, rewind等。
非缓冲文件系统 :缓冲文件系统是借助文件结构体指针来对文件进行管理,通过文件指针来对文件进行访问,既可以读写字符、字符串、格式化数据,也可以读写二进制数据。非缓冲文件系统依赖于操作系统,通过操作系统的功能对文件进行读写,是系统级的输入输出,它不设文件结构体指针,只能读写二进制文件,但效率高、速度快,由于ANSI标准不再包括非缓冲文件系统,因此建议大家最好不要选择它。open, close, read, write, getc, getchar, putc, putchar等。一句话总结一下,就是open无缓冲,fopen有缓冲。前者与read, write等配合使用, 后者与fread,fwrite等配合使用。
例子:使用fopen函数,由于在用户态下就有了缓冲,因此进行文件读写操作的时候就减少了用户态和内核态的切换(切换到内核态调用还是需要调用系统调用API:read,write);而使用open函数,在文件读写时则每次都需要进行内核态和用户态的切换;表现为,如果顺序访问文件,fopen系列的函数要比直接调用open系列的函数快;如果随机访问文件则相反。
字符模式I/O
#include <stdio.h>
FILE *fp,*gp;
int main()
{
int c;
fp = fopen("/home/hzx/hzx1.txt","r");
gp = fopen("/home/hzx/hzx2.txt","w");
while((c = getc(fp))!= EOF)
{
putc(c,gp);
}
fclose(fp);
fclose(gp);
}
行模式I/O
int main()
{
int c;
fp = fopen("/home/hzx/hzx1.txt","r");
gp = fopen("/home/hzx/hzx2.txt","w");
while((c = getc(fp))!= EOF)
{
putc(c,gp);
}
fclose(fp);
fclose(gp);
}
格式化输入
scanf(char *FMT,&items);
fscanf(char *FMT,&items);
格式化输出
print(char *FMT,&items);
fprint(char *FMT,&items);
内存中转换函数
sscanf(buf,FMT,&items);
sprintf(buf,FMT,&items);
限制混合 fread - fwrite
size_t fread(void*buffer,size_t size,size_t count,FILE*stream)
buffer: 是读取的数据存放的内存的指针,
size: 是每次读取的字节数
count: 是读取的次数
stream: 是要读取的文件的指针
ps: 是数据读取的流(输入流)
返回值:
成功:是实际读取的元素(并非字节)数目
失败:返回0
ps:如果输入过程中遇到了文件尾或者输出过程中出现了错误,这个数字可能比请求的元素数目要小
`size_t fread(void *buffer, size_t size, size_t count, FILE *stream)`;
-- `buffer`:指向数据块的指针
-- `size`:每个数据的大小,单位为Byte(例如:sizeof(int)就是4)
-- `count`:数据个数
-- `stream`:文件指针
fread - fwrite限制例子
int main()
{
FILE *fp = fopen("/home/hzx/hzx1.txt", "r+");
char Rbuf[5], Wbuf[5] = "4321";
fread(Rbuf, sizeof(char), 4, fp);
Rbuf[4] = '\0';
fseek(fp,ftell(fp),SEEK_SET);
fwrite(Wbuf, sizeof(char), 4, fp);
printf("%s\n", Rbuf);
fclose(fp);
return 0;
}
文件缓冲流(进行无缓冲,行缓冲,全缓冲之间的比较)
#include <stdio.h>
#include <stdlib.h>
#include <error.h>
#include <string.h>
int main(void)
{
FILE *fp;
char msg1[] = "hello,world";
char msg2[] = "hello\nworld";
char buf[128];
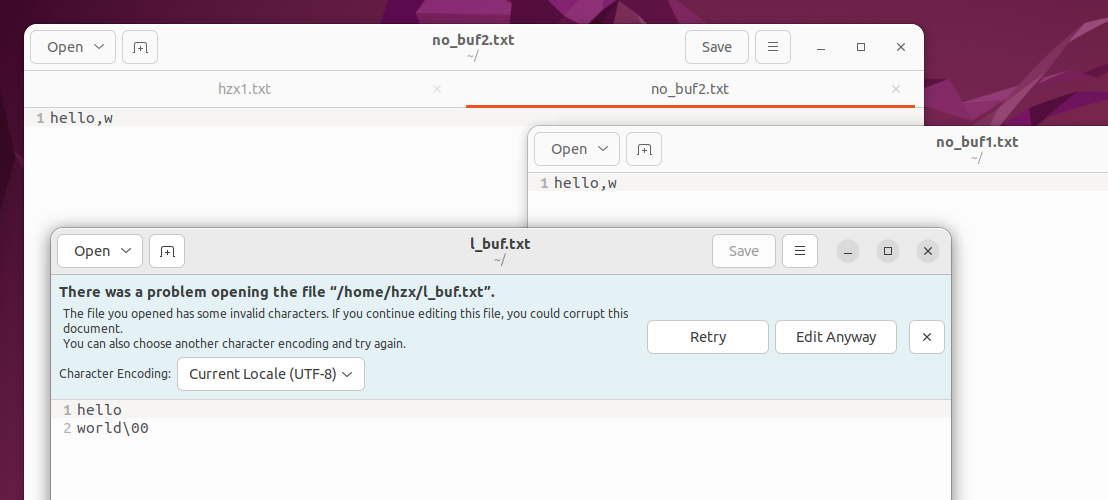
if((fp=fopen("/home/hzx/no_buf1.txt", "w")) == NULL)
{
perror("file open failure!");
return(-1);
}
setbuf(fp, NULL); //关闭缓冲区
memset(buf, '\0', 128); //字符串buf初始化'\0'
fwrite(msg1, 7, 1, fp); //向fp所指向的文件流中写7个字符
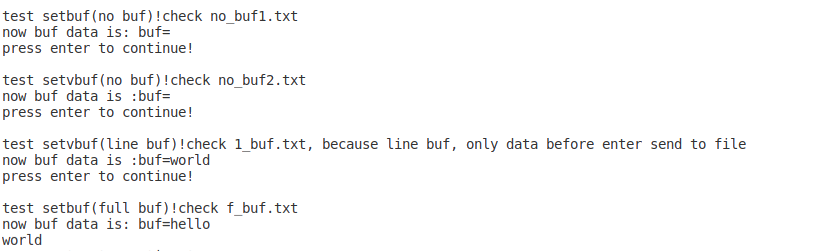
printf("test setbuf(no buf)!check no_buf1.txt\n");
printf("now buf data is: buf=%s\n", buf); //因为关闭了缓冲区,所以buf中无数据
printf("press enter to continue!\n");
getchar();
fclose(fp);
if((fp =fopen("/home/hzx/no_buf2.txt", "w")) == NULL)
{
perror("file open failure!");
return(-1);
}
setvbuf(fp, NULL, _IONBF, 0); //设置为无缓冲模式
memset(buf, '\0', 128);
fwrite(msg1, 7, 1, fp);
printf("test setvbuf(no buf)!check no_buf2.txt\n");
printf("now buf data is :buf=%s\n", buf);
printf("press enter to continue!\n");
getchar();
fclose(fp);
if((fp=fopen("/home/hzx/l_buf.txt", "w")) == NULL)
{
perror("file open failure!");
return(-1);
}
/*
* 设置为行缓冲
* 遇到'\n'就会刷新缓冲区
* 所以后面buf中只显示world字符,
* 在调用fclose()之前,
* 文件中写入的内容为"\n"之前的内容
*/
setvbuf(fp, buf, _IOLBF, sizeof(buf));
memset(buf, '\0', 128);
fwrite(msg2, sizeof(msg2), 1, fp);
printf("test setvbuf(line buf)!check 1_buf.txt, because line buf, only data before enter send to file\n");
printf("now buf data is :buf=%s\n", buf);
printf("press enter to continue!\n");
getchar();
fclose(fp);
if((fp=fopen("/home/hzx/f_buf.txt", "w")) == NULL)
{
perror("file open failure!");
return(-1);
}
/*
* 设置为全缓冲模式
* 会将msg2 <=128 字符的数据全部写入缓冲区buf
* 这时查看buf,里面的内容是所有msg2的字符串的内容
* 在调用fclose()之前,缓冲区的内容是不会刷新到文件中去的
* 所以文件中的内容会为空
* 直到调用fclose()才会把内容写到文件中去
*/
setvbuf(fp, buf, _IOFBF, sizeof(buf));
memset(buf, '\0', 128);
fwrite(msg2, sizeof(msg2), 1, fp);
printf("test setbuf(full buf)!check f_buf.txt\n");
printf("now buf data is: buf=%s\n", buf);
printf("press enter to continue!\n");
getchar();
fclose(fp);
return 0;
}
项目实践:(比较库函数和系统调用的速度)
库函数
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(){
clock_t start_t, end_t;
double total_t;
start_t = clock();
FILE *fp1,*fp2;
int n;
fp1 = fopen("/home/doxide/20201310unix/src/ch9/1.txt","r");
if(fp1==NULL){
perror("fopen error");
exit(1);
}
fp2 = fopen("/home/doxide/20201310unix/src/ch9/2.txt","w");
if(fp2==NULL){
perror("fopen error");
exit(1);
}
while((n=fgetc(fp1))!=EOF){
fputc(n,fp2);
}
fclose(fp1);
fclose(fp2);
end_t =clock();
total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
printf("用时%f\n",total_t);
return 0;
}
系统调用
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <unistd.h>
#define N 1
int main(){
clock_t start_t, end_t;
double total_t;
start_t = clock();
int fd1,fd2;
int n;
char buf[N];
fd1 = open("/home/doxide/20201310unix/src/ch9/1.txt",O_RDONLY);
if(fd1<0){
perror("fopen error");
exit(1);
}
fd2 = open("/home/doxide/20201310unix/src/ch9/2.txt",O_WRONLY|O_CREAT|O_TRUNC,0644);
if(fd2<0){
perror("fopen error");
exit(1);
}
while(n=read(fd1,buf,N)){
if(n<0){
perror("read error");
exit(1);
}
write(fd2,buf,n);
}
close(fd1);
close(fd2);
end_t =clock();
total_t = (double)(end_t - start_t) / CLOCKS_PER_SEC;
printf("用时%f\n",total_t);
return 0;
}
问题:
文件描述符是什么?
文件描述符本质是一个数组的索引值,这个数组里面存储的是指针,指针指向一个文件结构体。(也有说是“键值对”的,文件描述符是key,文件指针是value)
既然文件描述符是数组下标,自然就是非负数了。
0,1,2 文件描述符一般是固定的,即stdin,stdout,stderro,所以用户打开的第一个文件的描述符一般是3
那为什么不直接指针指定文件,非得中间加一层数组,转而使用数组下表呢?
大概是因为操作系统不想让用户知道它的具体实现细节
为什么库函数会比系统调用性能更好?
按道理来说,如果使用库函数,会比直接使用系统调用多一道手续,因为库函数也是要去调用系统调用,才能进入内核
但是从结果来看,我们编写的,以字节为单位读写文件的程序,调用库函数的程序运行快得多,为什么?
主要还是因为我们不了解操作系统,自己写出来的系统调用效率太低,与标准库函数的效率相差甚远。
就这次我们写的系统调用的程序来说,存在这样的问题,每一次系统调用,都需要从用户态向内核态转换,这个开销很大;如此巨大的开销,却只操作了一个字节的数据。
而库函数的fgetc()和fputc(),表面看也是每次只操作一个字节,而实际上,在其实现的时候,维护了一个4K的缓冲区(和内核态中的缓冲区大小一致),只有当用户态的缓冲区写满了之后,才发起真正的系统调用,产生一次巨大的开销,一次性将4k的数据,写入内核态的缓冲区,
所以库函数的速度才会比自己写的系统调用快
当我们把自己写的系统调用也设置一个4k的缓冲区后,发现系统调用的速度就会比库函数快了
