


# -*- coding: utf-8 -*- #2019/12/16 10:35 import os import time import requests import traceback from bs4 import BeautifulSoup from multiprocessing import Process, Pool import threading from threading import Thread from concurrent.futures import ThreadPoolExecutor # 线程池 import gevent from conf import settings as ss from core.log import Log as log def save_img(file_name,content): '''保存图片到本地''' with open(file_name, 'wb') as f: f.write(content) def spider(num): '''爬虫操作''' rep_url = r"https://www.autohome.com.cn/all/{}/#liststart".format(num) print(rep_url) # 1. 模拟浏览器发请求 response = requests.get(url=rep_url) # response.encoding = 'gbk' # 2. 获取请求内容 text = response.text # 3. 使用bs4库解析请求 soup = BeautifulSoup(text, 'html.parser') # html.parser:解析器,负责解析文本 # 从整个文本中进一步缩小定位范围, div:所有图片外部的盒子 div_obj = soup.find(name='div', attrs={"class": "article-wrapper"}) # print(div_obj) # 4. 定位图片位置 # 从盒子中找所有li标签 li_list = div_obj.find_all(name="li") for li in li_list: # 5. 获取图片链接 img = li.find(name='img') try: src = img.get("src") # print(src) img_name = src.rsplit('/',1)[-1] file_name = os.path.join(ss.IMG_PATH,img_name) # 获取到的图片链接没有http,给补齐 if not src.startswith('http'): src = 'http:' + src # 6. 使用requests模块向图片链接发请求 res = requests.get(url=src) # 7.保存图片到本地 save_img(file_name, res.content) except Exception as e: log.error(traceback.format_exc()) # break def thread_func(n): '''协程操作''' gevent_list = [] t = 50 # 开50个协程 m = t * n s = 1 + (m - t) for i in range(s, m+1): # print(i) gevent_list.append(gevent.spawn(spider,i)) # 生成的协程加入列表 gevent.joinall(gevent_list) #执行协程,遇到IO阻塞时会自动切换任务 def process_func(n): '''线程操作''' t = 20 # 开20个线程 m = t*n s = 1+(m-t) for num in range(s, m+1): m = threading.Thread(target=thread_func,args=(num,)) m.start() # m.join() if __name__ == '__main__': start = time.time() for i in range(1,6): # 开5个进程 m = Process(target=process_func,args=(i,)) m.start() # m.join() m.join() print(time.time() - start)
# -*- coding: utf-8 -*- #2019/12/19 16:41 import os import threading import gevent from multiprocessing import Process # 进程、线程和协程结合使用 def gevent_func(i): print('@@子协程@@',i) def thread_func(): print('-->子线程-->', os.getpid(), threading.current_thread().ident) gevent_list = [] for i in range(3): gevent_list.append(gevent.spawn(gevent_func,i)) # 生成3个协程加入列表 gevent.joinall(gevent_list) #执行协程,遇到IO阻塞时会自动切换任务 def process_func(): print('!!子进程!!', os.getpid(), threading.current_thread().ident) for i in range(3):# 开3个线程 threading.Thread(target=thread_func).start() if __name__ == '__main__': print('-->主进程',os.getpid(), threading.current_thread().ident) for i in range(3): #开3个进程 Process(target=process_func).start()
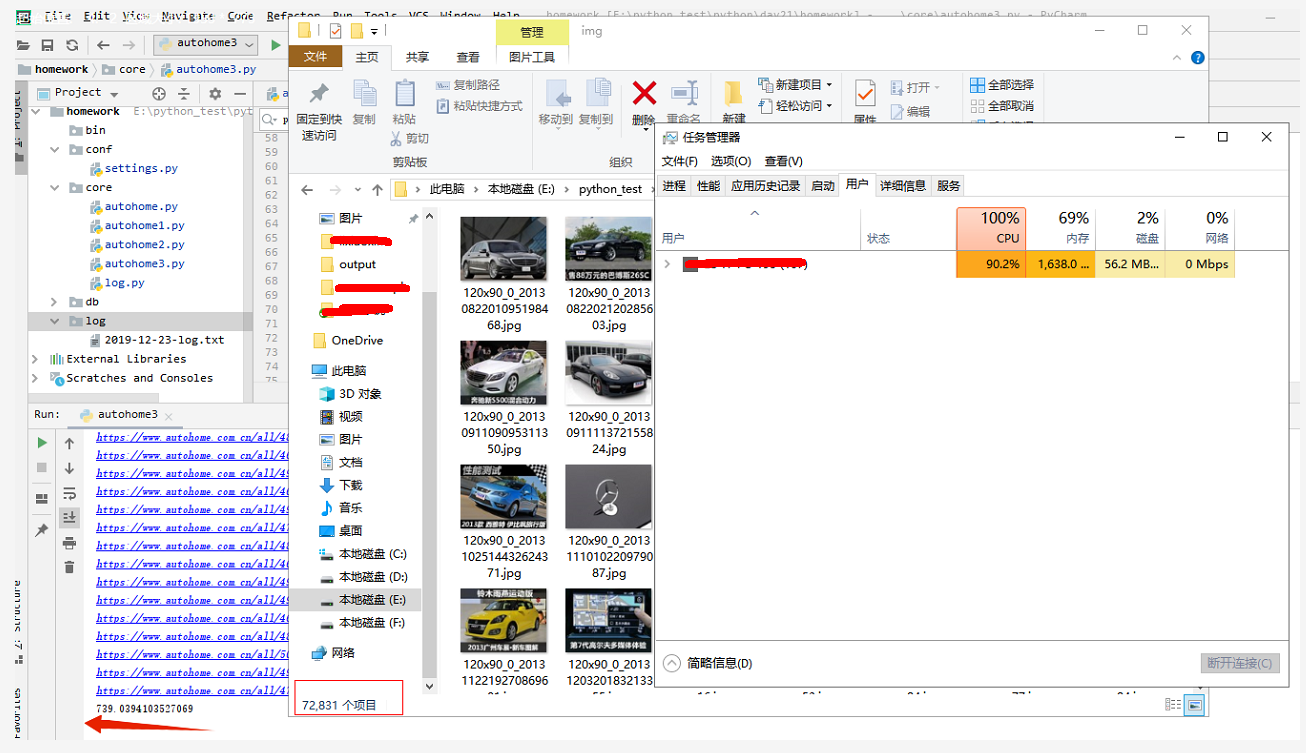
只用线程池的情况
# -*- coding: utf-8 -*- #2019/12/16 10:35 import os import time import requests import traceback from bs4 import BeautifulSoup from multiprocessing import Process, Pool from threading import Thread from concurrent.futures import ThreadPoolExecutor # 线程池 import gevent from conf import settings as ss from core.log import Log as log def save_img(file_name,content): '''保存图片到本地''' with open(file_name, 'wb') as f: f.write(content) def spider(num): '''爬虫操作''' rep_url = r"https://www.autohome.com.cn/all/{}/#liststart".format(num) print(rep_url) # 1. 模拟浏览器发请求 response = requests.get(url=rep_url) # response.encoding = 'gbk' # 2. 获取请求内容 text = response.text # 3. 使用bs4库解析请求 soup = BeautifulSoup(text, 'html.parser') # html.parser:解析器,负责解析文本 # 从整个文本中进一步缩小定位范围, div:所有图片外部的盒子 div_obj = soup.find(name='div', attrs={"class": "article-wrapper"}) # print(div_obj) # 4. 定位图片位置 # 从盒子中找所有li标签 li_list = div_obj.find_all(name="li") for li in li_list: # 5. 获取图片链接 img = li.find(name='img') try: src = img.get("src") # print(src) img_name = src.rsplit('/',1)[-1] file_name = os.path.join(ss.IMG_PATH,img_name) # 获取到的图片链接没有http,给补齐 if not src.startswith('http'): src = 'http:' + src # 6. 使用requests模块向图片链接发请求 res = requests.get(url=src) # 7.保存图片到本地 save_img(file_name, res.content) except Exception as e: log.error(traceback.format_exc()) # break def thread_pool(): t = ThreadPoolExecutor(max_workers=10) for num in range(1, 101): t.submit(spider,num) t.shutdown() if __name__ == '__main__': start = time.time() thread_pool() print(time.time() - start)

