


不知道有没有小伙伴跟我一样犯这样的懒,一些简单重复的工作,总是嫌麻烦,懒得一步步去做,还每次都重复一样的操作。比如解压zip或rar的包,也许你会说,不就解压嘛,有啥的。问题来了,如果只是一个简单的压缩包也是算了,关键是压缩包里还有压缩包,也不知道多少层,要一层层去解压,这就比较恶心了吧?如下图:
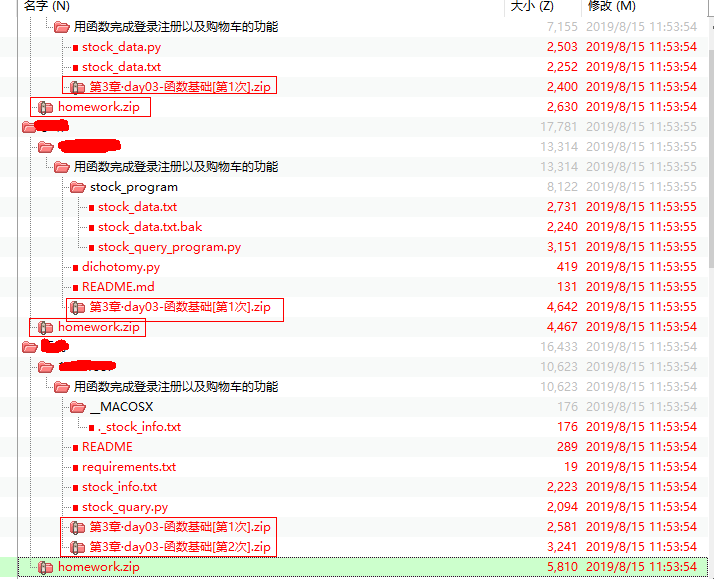
学习了Python的递归调用后,心想,为什么我不写一个脚本自动解压所有的压缩包呢?emmm....心动不如行动,说写就写,谁让我是这么懒的一个人呢,连解压都得自动化,哈哈哈。
那就来吧,先从最简单的开始,搞个zip包用命令行解压看看:
# -*- coding: utf-8 -*- import zipfile import os path = r'C:\Users\ES-IT-PC-193\Desktop\aa\A.zip' z = zipfile.ZipFile(path, 'r') unzip_path = os.path.split(path)[0] #解压路径 z.extractall(path=unzip_path)
嗯,试了试,没问题,能正常解压。那接下来就是解决如果把压缩包里包含压缩包的也一块解压了,那我得把解压的命令封装成函数,然后循环解压就好了。这里正好用上了刚学不久的递归调用。
# -*- coding: utf-8 -*- # 2019/8/13 14:57 import zipfile import os def unzip_file(path): '''解压zip包''' if os.path.exists(path): if path.endswith('.zip'): z = zipfile.ZipFile(path, 'r') unzip_path = os.path.split(path)[0] z.extractall(path=unzip_path) zip_list = z.namelist() # 返回解压后的所有文件夹和文件 for zip_file in zip_list: new_path = os.path.join(unzip_path,zip_file) unzip_file(new_path) z.close() elif os.path.isdir(path): for file_name in os.listdir(path): unzip_file(os.path.join(path, file_name)) else: print('the path is not exist!!!') if __name__ == '__main__': zip_path = r'C:\Users\ES-IT-PC-193\Desktop\aa\A.zip' unzip_file(zip_path)
嗯,效果还不错,能把所有的压缩包都递归解压开了,然而,问题来了,解压开的文件名称怎么都成乱码了?!!
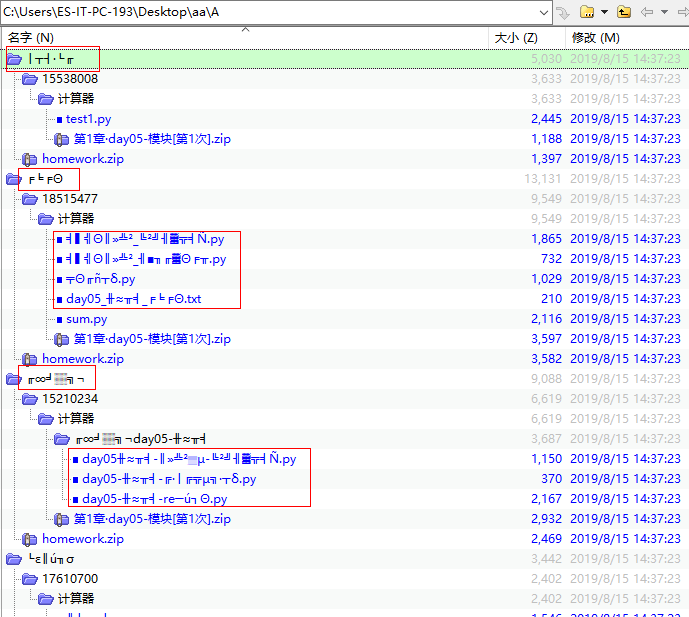
于是开始寻找解决乱码问题的方法,然后是各种百度。哎,编码问题一直困扰了我很久,总也搞不明白,这里推荐Alex写的一篇博客,写的很详细,反正我看完后就只知道,不管什么编码格式,都统统给它转成Unicode,然后再转成utf-8或者gbk的格式。哈哈哈。
Alex的博客链接:https://www.cnblogs.com/alex3714/articles/7550940.html
然后我就接着搞搞,各种尝试,还是不行,就是转换不过来,奇怪了。搞了好久还是没找到什么原因。彻底蒙圈了,郁闷~~,晚上睡觉我都能梦见我在解决编码问题,哈哈哈。今天早上脑袋还算比较清醒,再继续找bug。一行行代码调试。果然啊,功夫不负有心人。还是被我找到是什么原因了。
C:\Users\ES-IT-PC-193\Desktop\aa\A\│┬┤·└╓\
C:\Users\ES-IT-PC-193\Desktop\aa\A\╤Θ╓ñ┬δ.py
像这样的一个路径,打印出来的类型就是一个普通的<type 'str'>,整行路径去转换格式是不行的!!只有把乱码的部分切割出来,再单独转换就可以了。哦,天。就这样,一个小小的问题,卡了我好久。泪奔~
再加上编码转换:
# -*- coding: utf-8 -*- # 2019/8/13 14:57 import zipfile import os def unzip_file(path): '''解压zip包''' if os.path.exists(path): if path.endswith('.zip'): z = zipfile.ZipFile(path, 'r') unzip_path = os.path.split(path)[0] z.extractall(path=unzip_path) zip_list = z.namelist() # 返回解压后的所有文件夹和文件
for zip_file in zip_list:
try: zip_file2 = zip_file.encode('cp437').decode('gbk') except: zip_file2 = zip_file.encode('utf-8').decode('utf-8') old_path = os.path.join(unzip_path,zip_file) new_path = os.path.join(unzip_path,zip_file2) if os.path.exists(old_path): os.renames(old_path, new_path) unzip_file(new_path) z.close() elif os.path.isdir(path): for file_name in os.listdir(path): unzip_file(os.path.join(path, file_name)) else: print('the path is not exist!!!') if __name__ == '__main__': zip_path = r'C:\Users\ES-IT-PC-193\Desktop\aa\A.zip' unzip_file(zip_path)
作为有强迫症患者的我,看着这个代码真是乱啊,不爽,需要优化一下。
于是做了一下几点优化:
1、加上rar压缩包的解压,这里需要注意的是,需要下载一个UnRAR.exe文件放在脚本的同级目录。
2、把编码转换再单独写一个函数,传入一个带有乱码的路径,返回转换好的路径就行了。
3、把解压单独写一个函数,这样解压zip和rar的包就不用写段重复的代码了。
4、解压后,目录里有一堆压缩包,我只想要解压后的文件,于是再写了一个删除解压后不用的压缩包的函数。
最终版的代码如下,欢迎各位小伙伴指导。
# -*- coding: utf-8 -*- # 2019/8/13 14:57 import zipfile import rarfile import os import sys def chengeChar(path): '''处理乱码''' if not os.path.exists(path): return path path = path.rstrip('/').rstrip('\\') # 去除路径最右边的/ file_name = os.path.split(path)[-1] # 获取最后一段字符,准备转换 file_path = os.path.split(path)[0] # 获取前面的路径,为rename做准备 try: # 将最后一段有乱码的字符串转换,尝试过整个路径转换,不生效,估计是无法获取整个路径的编码格式吧。 new_name = file_name.encode('cp437').decode('gbk') except: # 先转换成Unicode再转换回gbk或utf-8 new_name = file_name.encode('utf-8').decode('utf-8') path2 = os.path.join(file_path, new_name) # 将转换完成的字符串组合成新的路径 try: os.renames(path, path2) # 重命名文件 except: print('renames error!!') return path2 def del_zip(path): '''删除解压出来的zip包''' path = chengeChar(path) if path.endswith('.zip') or path.endswith('.rar'): os.remove(path) elif os.path.isdir(path): for i in os.listdir(path): file_path = os.path.join(path, i) del_zip(file_path) # 递归调用,先把所有的文件删除 def unzip_file(z, unzip_path): '''解压zip包''' z.extractall(path=unzip_path) zip_list = z.namelist() # 返回解压后的所有文件夹和文件list z.close() for zip_file in zip_list: path = os.path.join(unzip_path, zip_file) if os.path.exists(path): main(path) def main(path): '''主逻辑函数''' path = chengeChar(path) if os.path.exists(path): unzip_path = os.path.splitext(path)[0] # 解压至当前目录 if path.endswith('.zip') and zipfile.is_zipfile(path): z = zipfile.ZipFile(path, 'r') unzip_file(z, unzip_path) elif path.endswith('.rar'): r = rarfile.RarFile(path) unzip_file(r, unzip_path) elif os.path.isdir(path): for file_name in os.listdir(path): path = os.path.join(path, file_name) if os.path.exists(path): main(path) else: print(path) else: print('the path is not exist!!!') print(path) if __name__ == '__main__': #zip_path = r'C:\Users\ES-IT-PC-193\Desktop\aa\HighLevel\HighLevel' zip_path = r'C:\Users\ES-IT-PC-193\Desktop\aa\HighLevel.zip' # zip_path = sys.argv[1] # 接收传入的路径参数 if os.path.isdir(zip_path): for file_name in os.listdir(zip_path): path = os.path.join(zip_path, file_name) main(path) else: main(zip_path) if zipfile.is_zipfile(zip_path): # 删除解压出来的压缩包 del_zip(os.path.splitext(zip_path)[0]) # 以后缀名切割

