Hadoop基础-14-集群环境搭建
源码见:https://github.com/hiszm/hadoop-train
Hadoop集群规划
HDFS: NN(NameNode) DN(DataNode)
YARN: RM(ResourceManager) NM(NodeManager)
hadoop000 192.168.43.200
- HDFS: NN(NameNode) DN(DataNode)
- YARN: RM(ResourceManager) NM(NodeManager)
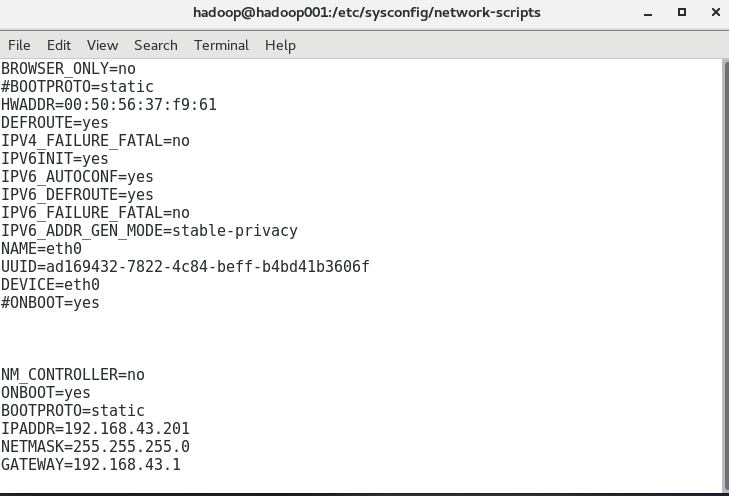
hadoop001 192.168.43.201
- HDFS: DN(DataNode)
- YARN: NM(NodeManager)
hadoop002 192.168.43.202
- HDFS: DN(DataNode)
- YARN: NM(NodeManager)
- 修改
/etc/hostname

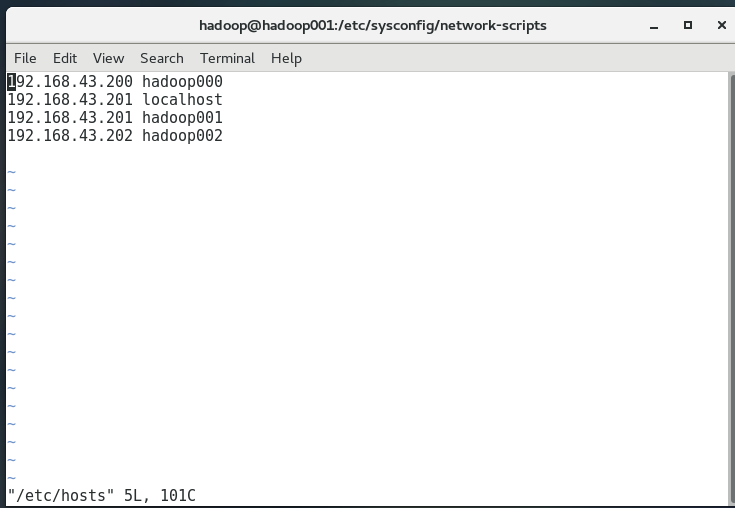
/etc/hosts;地址的映射
192.168.43.200 hadoop000
192.168.43.201 hadoop001
192.168.43.202 hadoop002

ssh的免密码登录
- 三台主机都配置
ssh-keygen -t rsa

- 在主服务器hadoop配置
- ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop000
- ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
- ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
[hadoop@hadoop000 ~]$ cd .ssh/
[hadoop@hadoop000 .ssh]$ ls
authorized_keys id_rsa id_rsa.pub known_hosts
[hadoop@hadoop000 .ssh]$ pwd
/home/hadoop/.ssh
[hadoop@hadoop000 .ssh]$ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop000
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hadoop/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hadoop@hadoop000's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop000'"
and check to make sure that only the key(s) you wanted were added.
[hadoop@hadoop000 .ssh]$ ssh hadoop@hadoop000
Last login: Fri Sep 11 00:34:59 2020 from 192.168.43.154
[hadoop@hadoop000 ~]$ exit
登出
Connection to hadoop000 closed.
注意
如果是同事配置三台虚拟机记得将网卡的mac地址重新生成
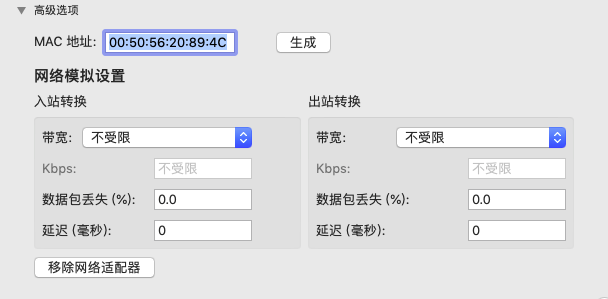
修改mac和ip地址
JDK安装
- 现在hadoop000 部署jdk
- 配置环境变量
- 拷贝jdk到其它节点
scp -r jdk1.8.0_91 hadoop@hadoop001:~/app/
scp -r jdk1.8.0_91 hadoop@hadoop002:~/app/
- 拷贝环境变量
scp -r ~/.bash_profile hadoop@hadoop002:~/
scp -r ~/.bash_profile hadoop@hadoop001:~/
source ~/.bash_profile
Hadoop集群部署
hadoop-env.sh
/home/hadoop/app/hadoop-2.6.0-cdh5.15.1/etc/hadoop
配置JAVA_HOME
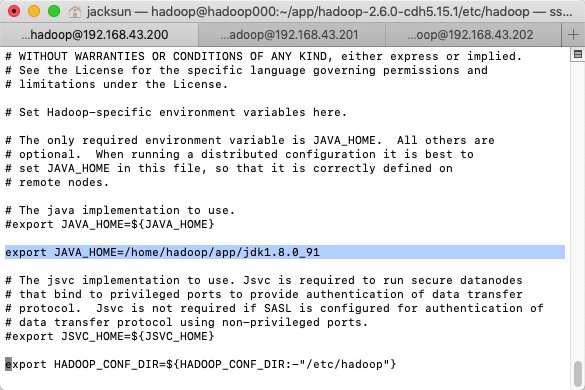
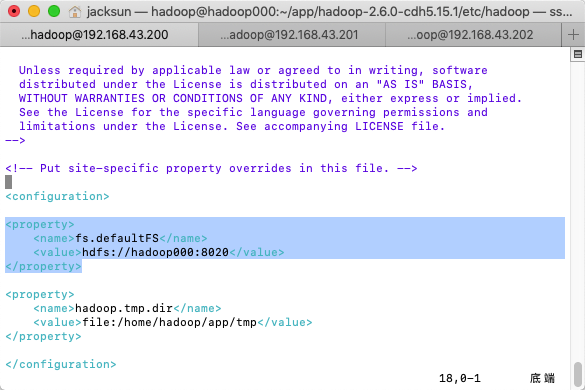
core-site.xml
主节点配置
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/tmp/dfs/data</value>
</property>
yarn-site.xml
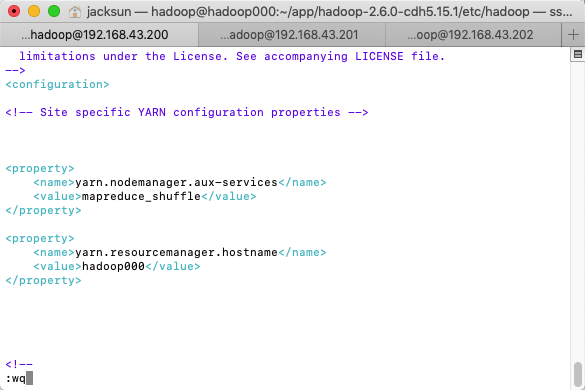
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop000</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

slaves

- 分发文件

scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop001:~/app/
scp -r hadoop-2.6.0-cdh5.15.1 hadoop@hadoop002:~/app/
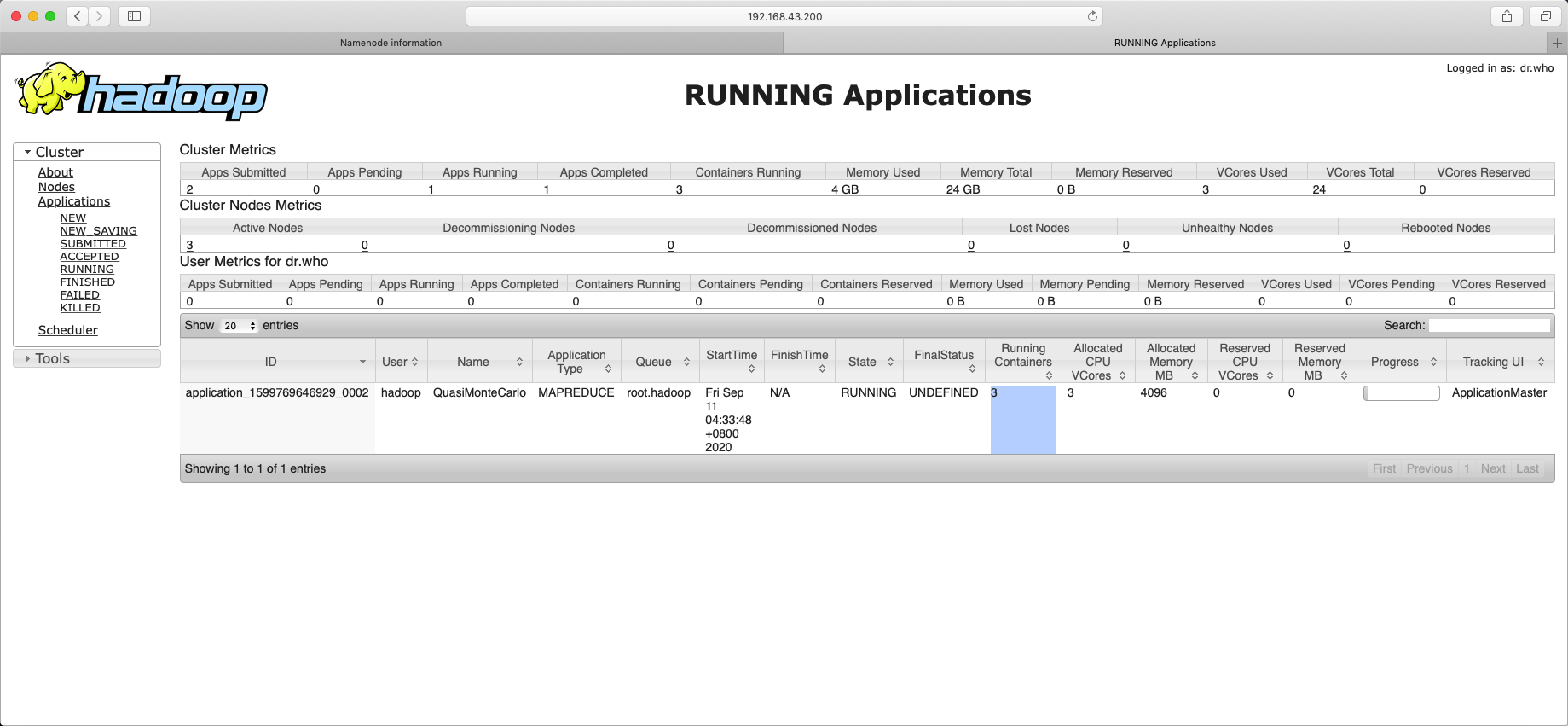
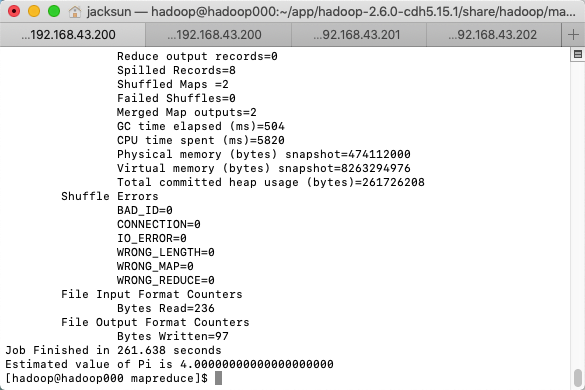
提交作业到Hadoop集群上运行
课程总结
NameNode格式化
hadoop namenode -format

注意
不建议多次格式化, 多次格式化,导致 NameNode 和 DataNode 的集群 id 不匹配 DataNode 无法启动
方法删除tmp下面的data和name文件重新启动
- 启动HDFS(主机起动,从机自动启动)
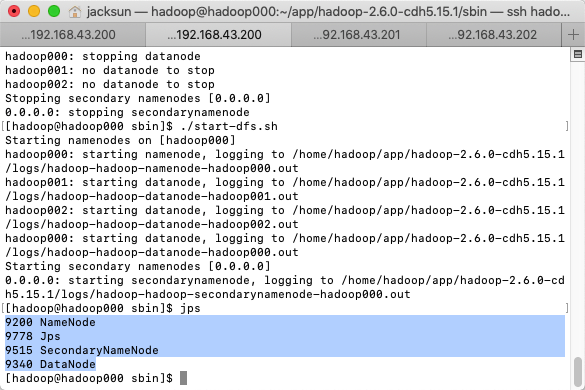
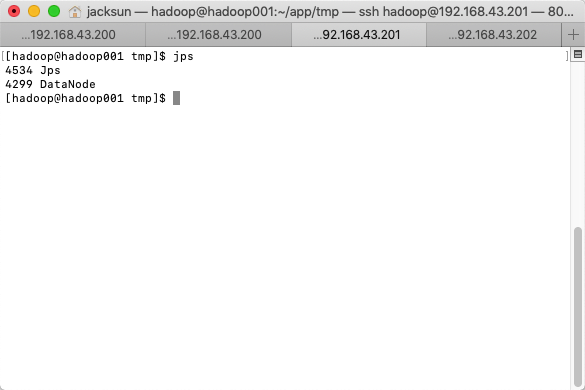

- 启动YARN
./start-yarn.sh
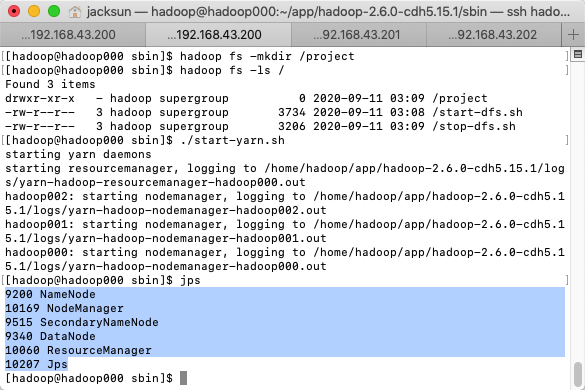

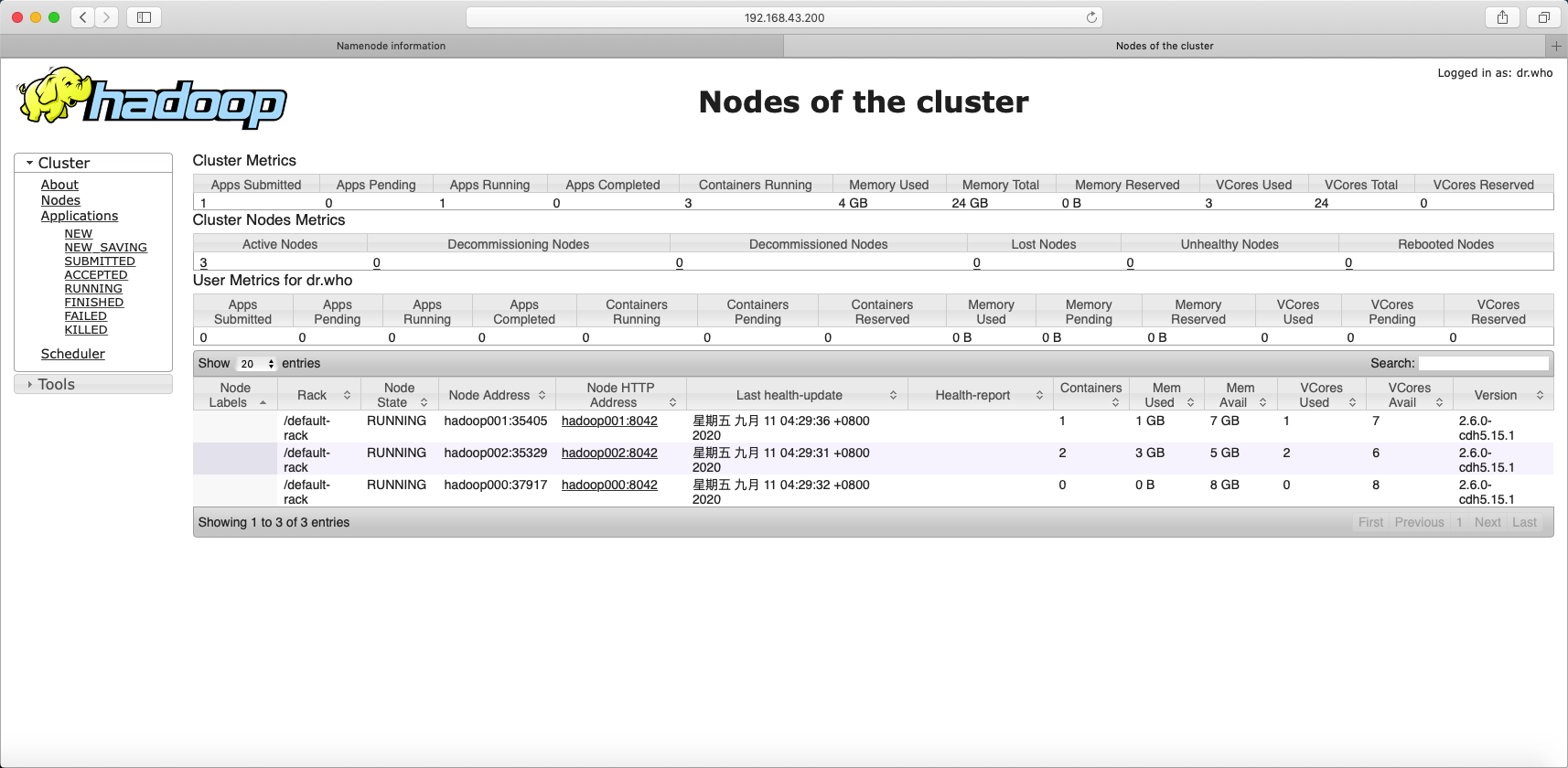
提交作业
[hadoop@hadoop000 mapreduce]$ pwd
/home/hadoop/app/hadoop-2.6.0-cdh5.15.1/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.1.jar pi 2 3
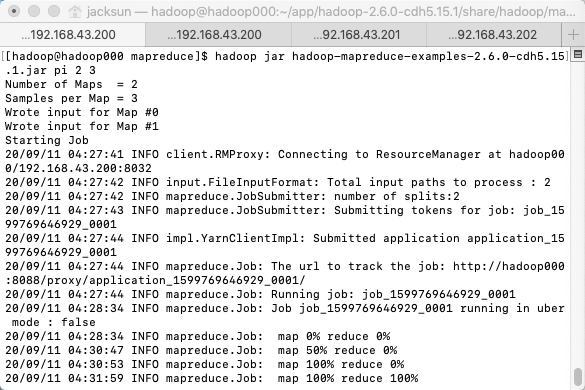

|
🐳 作者:hiszm 📢 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,万分感谢。 💬 留言:同时 , 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号