Hadoop基础-12-Hive
源码见:https://github.com/hiszm/hadoop-train
Hive概述
- Hive是什么
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
- 为什么要使用Hive
MappReduce编程不便- 同时也要
RDBMS关系型数据库 - HDFS上没有
schema的概念
(schema就是数据库对象的集合 , 所谓的数据库对象也就是常说的表,索引,视图,存储过程等。)
- Hive特点:
- 简单、容易 上手 (提供了类似
SQL的查询语言HQL),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析; - 灵活 性高,底层引擎支持 MR/ Tez /Spark;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的
元数据管理,可与presto/impala/sparksql等 共享 数据; - 执行延迟高,不适合做数据的实时处理,但适合做海量数据的 离线 处理。
Hive体系架构
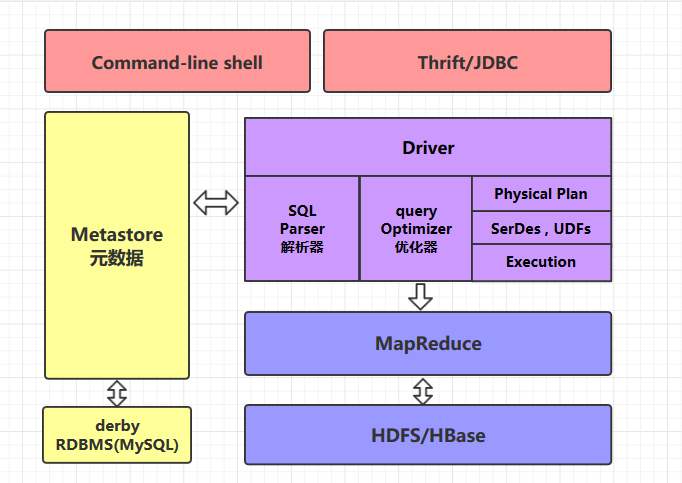
client:shell,jdbc,webUI(zeppelin)metastore: 指数据库中的元数据
Hive部署架构
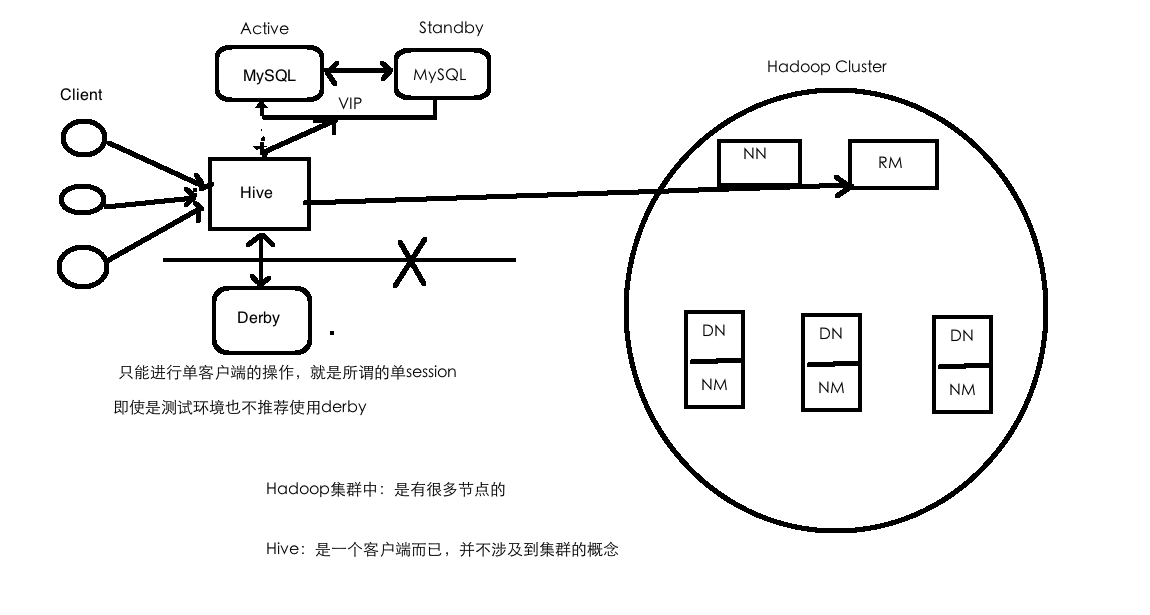
Hive与RDBMS的区别
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | Hive SQL | SQL |
| 数据储存 | HDFS | Raw Device or Local FS |
| 索引 | 无(支持比较弱) | 有 |
| 执行 | MapReduce、 Tez | Excutor |
| 执行时延 | 高,离线 | 低 , 在线 |
| 数据规模 | 非常大, 大 | 小 |
Hive部署
- 获得
wget hive-1.1.0-cdh5.15.1.tar.gz(url) - 解压
tar -zxvf hive-1.1.0-cdh5.15.1.tar.gz -C ~/app/ - 配置环境变量
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.15.1
export PATH=$HIVE_HOME/bin:$PATH
- 生效
source ~/.bash_profile
[hadoop@hadoop000 app]$ source ~/.bash_profile
[hadoop@hadoop000 app]$ echo $HIVE_HOME
/home/hadoop/app/hive-1.1.0-cdh5.15.1
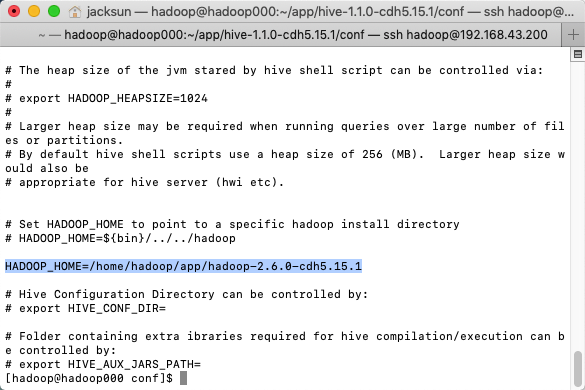
- 修改配置
/conf/hive-env.sh
增加一行
/conf/hive-site.xml
添加文件
[hadoop@hadoop000 conf]$ cat hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop000:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
[hadoop@hadoop000 conf]$
- MySQL驱动
mysql-connector-java-5.1.27-bin.jar
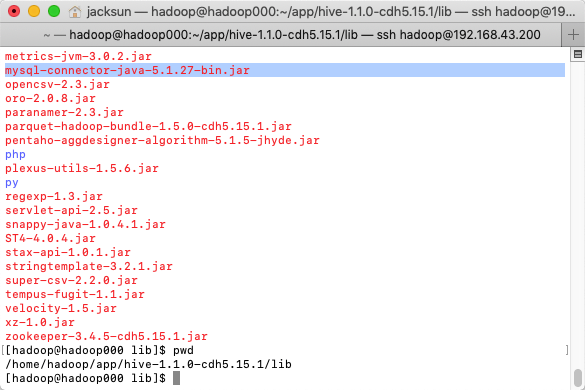
拷贝到目录home/hadoop/app/hive-1.1.0-cdh5.15.1/lib
- 安装数据库
用yum安装
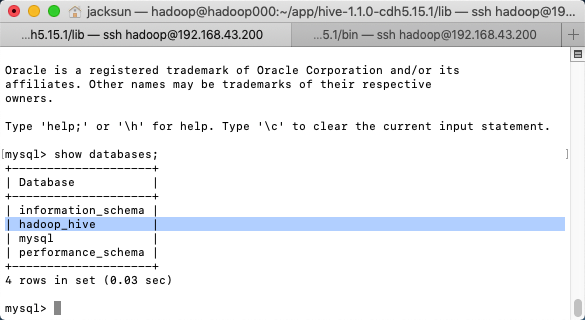
[hadoop@hadoop000 lib]$ mysql -uroot -proot
Warning: Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.6.42 MySQL Community Server (GPL)
Copyright (c) 2000, 2018, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Hive快速入门
- 启动hive
[hadoop@hadoop000 sbin]$ jps
3218 SecondaryNameNode
3048 DataNode
3560 NodeManager
3451 ResourceManager
2940 NameNode
3599 Jps
hive> create database test
> ;
OK
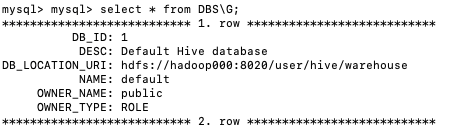
select * from DBS\G;
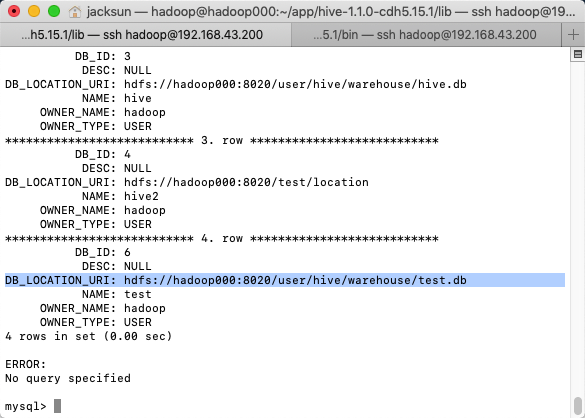
mysql> mysql> select * from DBS\G;
*************************** 1. row ***************************
DB_ID: 1
DESC: Default Hive database
DB_LOCATION_URI: hdfs://hadoop000:8020/user/hive/warehouse
NAME: default
OWNER_NAME: public
OWNER_TYPE: ROLE
*************************** 2. row ***************************
DB_ID: 3
DESC: NULL
DB_LOCATION_URI: hdfs://hadoop000:8020/user/hive/warehouse/hive.db
NAME: hive
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 3. row ***************************
DB_ID: 4
DESC: NULL
DB_LOCATION_URI: hdfs://hadoop000:8020/test/location
NAME: hive2
OWNER_NAME: hadoop
OWNER_TYPE: USER
*************************** 4. row ***************************
DB_ID: 6
DESC: NULL
DB_LOCATION_URI: hdfs://hadoop000:8020/user/hive/warehouse/test.db
NAME: test
OWNER_NAME: hadoop
OWNER_TYPE: USER
4 rows in set (0.00 sec)
ERROR:
No query specified
Hive DDL
Hive DDL=Hive Data Definition Language

数据库操作
- Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
hive> create DATABASE hive_test;
OK
Time taken: 0.154 seconds
hive>
再HDFS上的 默认路径 /user/hive/warehouse/hive_test.db
默认的hive数据库没有default.db的路径/user/hive/warehouse/
自定义创建路径
hive> create DATABASE hive_test2 LOCATION '/test/hive'
> ;
OK
Time taken: 0.119 seconds
hive>
[hadoop@hadoop000 network-scripts]$ hadoop fs -ls /test/
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2020-09-09 06:29 /test/hive
自定义参数
DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否显示额外属性
hive> create DATABASE hive_test3 LOCATION '/test/hive'
> with DBPROPERTIES('creator'='jack');
OK
Time taken: 0.078 seconds
hive> desc database hive_test3
> ;
OK
hive_test3 hdfs://hadoop000:8020/test/hive hadoop USER
Time taken: 0.048 seconds, Fetched: 1 row(s)
hive> desc database extended hive_test3;
OK
hive_test3 hdfs://hadoop000:8020/test/hive hadoop USER {creator=jack}
Time taken: 0.018 seconds, Fetched: 1 row(s)
hive>
显示当前目录
hive> set hive.cli.print.current.db;
hive.cli.print.current.db=false
hive> set hive.cli.print.current.db=true;
hive (default)>
- Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
hive (default)> show databases;
OK
default
hive
hive2
hive_test
hive_test3
test
Time taken: 0.02 seconds, Fetched: 6 row(s)
hive (default)> drop database hive_test3;
OK
Time taken: 0.099 seconds
hive (default)> show databases;
OK
default
hive
hive2
hive_test
test
Time taken: 0.019 seconds, Fetched: 5 row(s)
hive (default)>
- 查找数据库
hive (default)> show databases like 'hive*';
OK
hive
hive2
hive_test
Time taken: 0.024 seconds, Fetched: 3 row(s)
hive (default)>
- 使用数据库
USE database_name;
表操作
- 创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --表名
[(col_name data_type [COMMENT col_comment],
... [constraint_specification])] --列名 列数据类型
[COMMENT table_comment] --表描述
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --分区表分区规则
[
CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS
] --分桶表分桶规则
[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
] --指定倾斜列和值
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
] -- 指定行分隔符、存储文件格式或采用自定义存储格式
[LOCATION hdfs_path] -- 指定表的存储位置
[TBLPROPERTIES (property_name=property_value, ...)] --指定表的属性
[AS select_statement]; --从查询结果创建表
CREATE TABLE emp(
empno int ,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
hive> CREATE TABLE emp(
> empno int ,
> ename string,
> job string,
> mgr int,
> hiredate string,
> sal double,
> comm double,
> deptno int
> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.115 seconds
hive> desc formatted emp;
OK
# col_name data_type comment
empno int
ename string
job string
mgr int
hiredate string
sal double
comm double
deptno int
# Detailed Table Information
Database: hive
Owner: hadoop
CreateTime: Wed Sep 09 09:34:57 CST 2020
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://hadoop000:8020/user/hive/warehouse/hive.db/emp
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1599615297
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.131 seconds, Fetched: 34 row(s)
- 加载数据
用DML的加载数据
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp;
hive> LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp;
Loading data to table hive.emp
Table hive.emp stats: [numFiles=1, totalSize=700]
OK
Time taken: 2.482 seconds
hive> select * from emp;
OK
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.0 NULL NULL
Time taken: 0.363 seconds, Fetched: 15 row(s)
hive>
- 更改表名
ALTER TABLE table_name RENAME TO new_table_name;
Hive DML
Hive Data Manipulation Language
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
-
LOCAL: 有 就是从服务器目录获取文件, 无则从HDFS系统
-
OVERWRITE: 有 表示新建数据 ; 无 表示追加数据
-
INPATH
- a relative path, such as
project/data1 - an absolute path, such a
s /user/hive/project/data1 - a full URI with scheme and (optionally) an authority, such as
hdfs://namenode:9000/user/hive/project/data1
- a relative path, such as
创建查询表 create table emp_1 as select * from emp;
- 导出数据
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/hive'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select empno , ename ,sal,deptno from emp;
hive>
> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/hive'
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
> select empno , ename ,sal,deptno from emp;
Query ID = hadoop_20200909102020_aeb2ef7d-cf18-4bcb-b903-8c6ea1719626
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1599583423179_0001, Tracking URL = http://hadoop000:8088/proxy/application_1599583423179_0001/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1599583423179_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-09-09 10:21:18,074 Stage-1 map = 0%, reduce = 0%
2020-09-09 10:21:29,109 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 5.64 sec
MapReduce Total cumulative CPU time: 5 seconds 640 msec
Ended Job = job_1599583423179_0001
Copying data to local directory /tmp/hive
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 5.64 sec HDFS Read: 4483 HDFS Write: 313 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 640 msec
OK
Time taken: 35.958 seconds
hive>
[hadoop@hadoop000 hive]$ cat 000000_0
7369 SMITH 800.0 20
7499 ALLEN 1600.0 30
7521 WARD 1250.0 30
7566 JONES 2975.0 20
7654 MARTIN 1250.0 30
7698 BLAKE 2850.0 30
7782 CLARK 2450.0 10
7788 SCOTT 3000.0 20
7839 KING 5000.0 10
7844 TURNER 1500.0 30
7876 ADAMS 1100.0 20
7900 JAMES 950.0 30
7902 FORD 3000.0 20
7934 MILLER 1300.0 10
8888 HIVE 10300.0 \N
[hadoop@hadoop000 hive]$
Hive QL
- 基本统计
和普通的sql并无两样
select * from emp where deptno=10;
- 聚合函数
像这种聚合(max,min,avg,sum)函数就是要跑
mappreduce的
hive> select count(1) from emp where deptno=10;
Query ID = hadoop_20200909104949_1ce185de-2025-4633-9324-3e47f30fb157
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1599583423179_0002, Tracking URL = http://hadoop000:8088/proxy/application_1599583423179_0002/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1599583423179_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-09-09 10:50:00,361 Stage-1 map = 0%, reduce = 0%
2020-09-09 10:50:10,092 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 6.52 sec
2020-09-09 10:50:25,233 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.72 sec
MapReduce Total cumulative CPU time: 11 seconds 720 msec
Ended Job = job_1599583423179_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 11.72 sec HDFS Read: 9708 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 720 msec
OK
3
Time taken: 38.666 seconds, Fetched: 1 row(s)
hive> select * from emp where deptno=10;
OK
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.209 seconds, Fetched: 3 row(s)
hive>
- 分组函数
select deptno , avg(sal) from group by deptno;
注意 select的字段没有再聚合函数就要出现再group by 里面
- join的使用
用于涉及到多表
CREATE TABLE dept(
deptno int,
dname string,
loc string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/data/dept.txt' OVERWRITE INTO TABLE dept;
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e join dept d
on e.deptno=d.deptno;
hive> select e.empno,e.ename,e.sal,e.deptno,d.dname
> from emp e join dept d
> on e.deptno=d.deptno;
Query ID = hadoop_20200909140808_8635204d-8e8a-4267-8503-ef242f022ebc
Total jobs = 1
2020-09-09 02:08:51 Starting to launch local task to process map join; maximum memory = 477626368
2020-09-09 02:08:54 End of local task; Time Taken: 3.023 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1599583423179_0004, Tracking URL = http://hadoop000:8088/proxy/application_1599583423179_0004/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.15.1/bin/hadoop job -kill job_1599583423179_0004
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2020-09-09 14:09:06,852 Stage-3 map = 0%, reduce = 0%
2020-09-09 14:09:18,823 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 6.7 sec
MapReduce Total cumulative CPU time: 6 seconds 700 msec
Ended Job = job_1599583423179_0004
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 6.7 sec HDFS Read: 7649 HDFS Write: 406 SUCCESS
Total MapReduce CPU Time Spent: 6 seconds 700 msec
OK
7369 SMITH 800.0 20 RESEARCH
7499 ALLEN 1600.0 30 SALES
7521 WARD 1250.0 30 SALES
7566 JONES 2975.0 20 RESEARCH
7654 MARTIN 1250.0 30 SALES
7698 BLAKE 2850.0 30 SALES
7782 CLARK 2450.0 10 ACCOUNTING
7788 SCOTT 3000.0 20 RESEARCH
7839 KING 5000.0 10 ACCOUNTING
7844 TURNER 1500.0 30 SALES
7876 ADAMS 1100.0 20 RESEARCH
7900 JAMES 950.0 30 SALES
7902 FORD 3000.0 20 RESEARCH
7934 MILLER 1300.0 10 ACCOUNTING
Time taken: 46.765 seconds, Fetched: 14 row(s)
hive>
- 执行计划

explain
select e.empno,e.ename,e.sal,e.deptno,d.dname
from emp e join dept d
on e.deptno=d.deptno;
hive> explain
> select e.empno,e.ename,e.sal,e.deptno,d.dname
> from emp e join dept d
> on e.deptno=d.deptno;
OK
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
Statistics: Num rows: 1 Data size: 79 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: deptno is not null (type: boolean)
Statistics: Num rows: 1 Data size: 79 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 deptno (type: int)
1 deptno (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: e
Statistics: Num rows: 6 Data size: 700 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: deptno is not null (type: boolean)
Statistics: Num rows: 3 Data size: 350 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 deptno (type: int)
1 deptno (type: int)
outputColumnNames: _col0, _col1, _col5, _col7, _col12
Statistics: Num rows: 3 Data size: 385 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: string), _col5 (type: double), _col7 (type: int), _col12 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4
Statistics: Num rows: 3 Data size: 385 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 3 Data size: 385 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.TextInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink

|
🐳 作者:hiszm 📢 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,万分感谢。 💬 留言:同时 , 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号