Hadoop基础-11-用户行为日志分析
源码见:https://github.com/hiszm/hadoop-train
用户行为日志概述
- 用户每次搜索和点击的记录
- 历史行为数据,从历史订单
==> 然后进行推荐/ 从而 提高用户的转化量 (最终目的)
日志内容
20979872853^Ahttp://www.yihaodian.com/1/?type=3&tracker_u=10974049258^A^A^A3^ABAWG49VCYYTMZ6VU9XX74KPV5CCHPAQ2A4A5^A^A^A^A^APPG68XWJNUSSX649S4YQTCT6HBMS9KBA^A10974049258^A\N^A27.45.216.128^A^A,unionKey:10974049258^A^A2013-07-21 18:58:21^A\N^A^A1^A^A\N^Anull^A247^A^A^A^A^AMozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C)^AWin32^A^A^A^A^A^A广东省^A20^A^A^A惠州
市^A^A^A^A^A^A^A\N^A\N^A\N^A\N^A2013-07-21
20977690754^Ahttp://www.yihaodian.com/1/?type=3&tracker_u=10781349260^A^A^A3^A49FDCP696X2RDDRC2ED6Y4JVPTEVFNDADF1D^A^A^A^A^APPGCTKD92UT3DR7KY1VFZ92ZU4HEP479^A10781349260^A\N^A101.80.223.6^A^A,unionKey:10781349260^A^A2013-07-21 18:11:46^A\N^A^A1^A^A\N^Anull^A-10^A^A^A^A^AMozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; InfoPath.3; .NET4.0E)^AWin32^A^A^A^A^A^A上海市^A1^A^A2013-07-21 18:11:46^A上海市^A^A^A^A^A^A^A\N^A\N^A\N^A\N^A2013-07-21
- 第二个字段:
url=> 页面ID - 第十四字段:
ip=> 地点 - 第十八字段:
time
电商常用术语
1.Ad Views(广告浏览):网上广告被用户浏览的次数。
2.PV(访问量):即Page View。页面浏览量,用户每次刷新即被计算一次。网站各网页被浏览的总次数。一个访客有可能创造十几个甚至更多的浏览量。或者这样理解:用户在你的网站上打开网页的次数,浏览了多少个页面,或者刷新了的次数。
3.Impression (印象数):指受用户要求的网页每一次的显示,就是一个Impression;广告主希望10万人次看到广告,即10万次Impression;也是评估广告效果的元素之一。
4.UV(独立访客数):即Unique Visitor,访问网站或看到广告的一台电脑客户端为一个访客。24小时内相同的客户端只被计算一次。
5.IP (独立IP): 即Internet Protocol,指独立IP数。24小时内相同IP地址之被计算一次。 6.URL(统一资源定位器): URL给出任何服务器、文件、图象在网上的位置。用户可以通过超文本协议链接特定的URL而找到所需信息。也就是着陆页网址。
7.Key Word(关键字)
8.HTML(超文本标识语言): 一种基于文本格式的页面描述语言,是网页通用的编辑语言。
9.Band Width (带宽):在某一时刻能够通过传播线路传输的信息(文字、图片、音、视频)容量。带宽越高,网页的调用就越快。有限的带宽导致了尽可能地要使网页中的图片文件小。
10.Browser Cache(浏览器缓存):为了加速网页的浏览,浏览器在硬盘中储存了最近访问的页面,如果重新访问该站点,浏览器就从硬盘中显示这个页面,而不是从服务器中。
11.Cookie:电脑中记录用户在网络中的行为的文件;网站可通过Cookie来识别用户是否曾经访问过该网站。
12.Database(数据库):通常指的利用现代计算机技术,将各类信息有序分类整理,便于查找和管理。在网络营销中,指利用互联网收集用户个人信息,并存
档、管理;如:姓名、性别、年龄、地址、电话、兴趣爱好、消费行为等等。
13.Targeting(定向): 通过内容匹配、用户构成或者过滤传递最适宜的广告给用户。也是百度所说的寻找精准客户,是广告定向,客户定向。
14.Traffic(流量):用户访问站点的数字和种类
项目需求描述
- 统计访问量(
pv) - 统计每个省份(
ip)访问量 - 统计每个页面(
url)的访问量
数据处理流程及技术架构
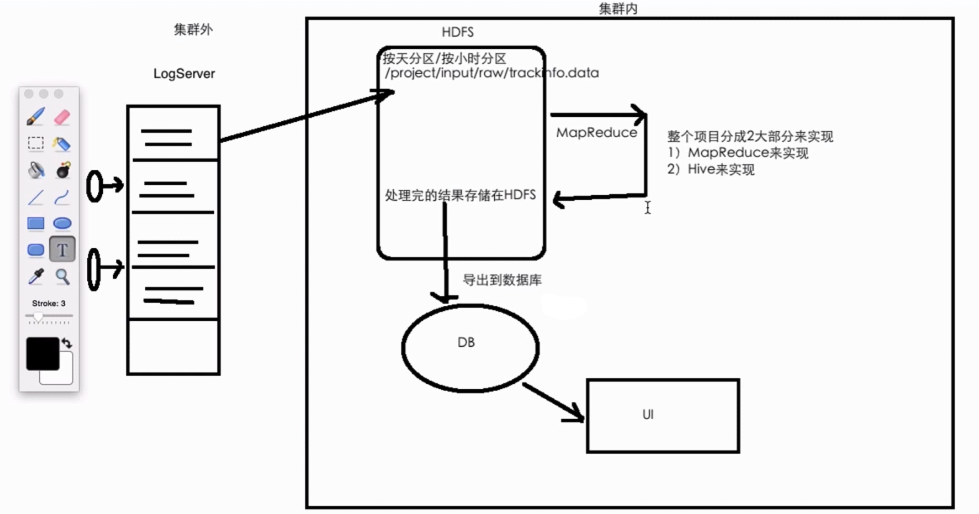
浏览量统计功能实现
统计页面的浏览量
count 一行记录做成一个固定的KET, value赋值为1
package com.bigdata.hadoop.mr.project.mrv1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 第一版本流量的统计
*
*/
public class PVStatApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
job.setJarByClass(PVStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("input/raw/trackinfo_20130721.data"));
FileOutputFormat.setOutputPath(job, new Path("output/pv1"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text KEY = new Text("key");
private LongWritable ONE = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(KEY, ONE);
}
}
static class MyReducer extends Reducer<Text, LongWritable, NullWritable, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count++;
}
context.write(NullWritable.get(), new LongWritable(count));
}
}
}
output : 300000
省份浏览量统计
统计各个省份的流量
select province count(1) from xxx group by province
地市信息 <= IP解析 <= IP如何转换城市信息
package com.bigdata.hadoop.hdfs;
import com.bigdata.hadoop.mr.project.utils.IPParser;
import org.junit.Test;
public class Iptest {
@Test
public void testIP(){
IPParser.RegionInfo regionInfo =IPParser.getInstance().analyseIp("58.32.19.255");
System.out.println(regionInfo.getCountry());
System.out.println(regionInfo.getProvince());
System.out.println(regionInfo.getCity());
}
}
/Library/Java/JavaVirtualMachines/jdk1.8.0_1/commons-logging/commons-logging/1.1.3/commons-logging-1.1.3.jar:/Users/jacksun/.m2/repository/log4j/log4j/1.2.17/log4j-1.2.17.jar:/Users/jacksun/.m2/repository/commons-lang/commons-lang/2.6/commons-lang-2.6.jar:/Users/jackop.hdfs.Iptest,testIP
中国
上海市
null
Process finished with exit code 0
IP库解析
import com.bigdata.hadoop.mr.project.utils.IPParser;
import com.bigdata.hadoop.mr.project.utils.LogParser;
package com.bigdata.hadoop.mr.project.utils;
import org.apache.commons.lang.StringUtils;
import java.util.HashMap;
import java.util.Map;
public class LogParser {
public Map<String, String> parse(String log) {
IPParser ipParser = IPParser.getInstance();
Map<String, String> info = new HashMap<>();
if (StringUtils.isNotBlank(log)) {
String[] splits = log.split("\001");
String ip = splits[13];
String country = "-";
String province = "-";
String city = "-";
IPParser.RegionInfo regionInfo = ipParser.analyseIp(ip);
if (regionInfo != null) {
country = regionInfo.getCountry();
province = regionInfo.getProvince();
city = regionInfo.getCity();
}
info.put("ip", ip);
info.put("country", country);
info.put("province", province);
info.put("city", city);
}
return info;
}
}
功能实现
package com.bigdata.hadoop.mr.project.mrv1;
import com.bigdata.hadoop.mr.project.utils.IPParser;
import com.bigdata.hadoop.mr.project.utils.LogParser;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
public class ProvinceStatApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("output/v1/provincestat");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ProvinceStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("input/raw/trackinfo_20130721.data"));
FileOutputFormat.setOutputPath(job, new Path("output/v1/provincestat"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
String ip = info.get("ip");
if (StringUtils.isNotBlank(ip)) {
IPParser.RegionInfo regionInfo = IPParser.getInstance().analyseIp(ip);
if (regionInfo != null) {
String province = regionInfo.getProvince();
if(StringUtils.isNotBlank(province)){
context.write(new Text(province), ONE);
}else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
} else {
context.write(new Text("-"), ONE);
}
}
}
static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
}
- 923
上海市 72898
云南省 1480
内蒙古自治区 1298
北京市 42501
台湾省 254
吉林省 1435
四川省 4442
天津市 11042
宁夏 352
安徽省 5429
山东省 10145
山西省 2301
广东省 51508
广西 1681
新疆 840
江苏省 25042
江西省 2238
河北省 7294
河南省 5279
浙江省 20627
海南省 814
湖北省 7187
湖南省 2858
澳门特别行政区 6
甘肃省 1039
福建省 8918
西藏 110
贵州省 1084
辽宁省 2341
重庆市 1798
陕西省 2487
青海省 336
香港特别行政区 45
黑龙江省 1968
页面浏览量统计
统计页面的访问量
把符合规则的pageID获取到,然后进行统计即可
页面编号获取
package com.bigdata.hadoop.mr.project.utils;
import org.apache.commons.lang.StringUtils;
import java.util.HashMap;
import java.util.Map;
public class LogParser {
public Map<String, String> parse(String log) {
IPParser ipParser = IPParser.getInstance();
Map<String, String> info = new HashMap<>();
if (StringUtils.isNotBlank(log)) {
String[] splits = log.split("\001");
String ip = splits[13];
String country = "-";
String province = "-";
String city = "-";
IPParser.RegionInfo regionInfo = ipParser.analyseIp(ip);
if (regionInfo != null) {
country = regionInfo.getCountry();
province = regionInfo.getProvince();
city = regionInfo.getCity();
}
info.put("ip", ip);
info.put("country", country);
info.put("province", province);
info.put("city", city);
String url = splits[1];
info.put("url", url);
String time = splits[17];
info.put("time", time);
}
return info;
}
public Map<String, String> parseV2(String log) {
IPParser ipParser = IPParser.getInstance();
Map<String, String> info = new HashMap<>();
if (StringUtils.isNotBlank(log)) {
String[] splits = log.split("\t");
String ip = splits[0];
String country = splits[1];
String province = splits[2];
String city = splits[3];
IPParser.RegionInfo regionInfo = ipParser.analyseIp(ip);
info.put("ip", ip);
info.put("country", country);
info.put("province", province);
info.put("city", city);
String url = splits[4];
info.put("url", url);
}
return info;
}
}
功能实现
package com.bigdata.hadoop.mr.project.mrv1;
import com.bigdata.hadoop.mr.project.utils.ContentUtils;
import com.bigdata.hadoop.mr.project.utils.LogParser;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
public class PageStatApp {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("output/v1/pagestat");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(PageStatApp.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path("input/raw/trackinfo_20130721.data"));
FileOutputFormat.setOutputPath(job, new Path("output/v1/pagestat"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
String url = info.get("url");
if (StringUtils.isNotBlank(url)) {
String pageId = ContentUtils.getPageId(url);
context.write(new Text(pageId), ONE);
}
}
}
static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count++;
}
context.write(key, new LongWritable(count));
}
}
}
- 298827
13483 19
13506 15
13729 9
13735 2
13736 2
14120 28
14251 1
14572 14
14997 2
15065 1
17174 1
17402 1
17449 2
17486 2
17643 7
18952 14
18965 1
18969 32
18970 27
18971 1
18972 3
18973 8
18977 10
18978 5
18979 11
18980 8
18982 50
18985 5
18988 2
18991 27
18992 4
18994 3
18996 3
18997 3
18998 2
18999 4
19000 5
19004 23
19006 4
19009 1
19010 1
19013 1
20154 2
20933 1
20953 5
21208 11
21340 1
21407 1
21484 1
21826 8
22068 1
22107 4
22114 4
22116 5
22120 6
22123 13
22125 1
22127 16
22129 3
22130 3
22140 1
22141 5
22142 8
22143 5
22144 1
22146 5
22169 1
22170 20
22171 51
22180 4
22196 75
22249 4
22331 6
22372 1
22373 1
22805 3
22809 3
22811 5
22813 11
23203 1
23481 194
23541 1
23542 1
23704 1
23705 1
3541 2
8101 36
8121 32
8122 38
9848 2
9864 1
数据处理之ETL
-----------------------
[INFO ] method:org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:1008)
kvstart = 26214396; length = 6553600
Counters: 30
File System Counters
FILE: Number of bytes read=857754791
FILE: Number of bytes written=23557997
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=300000
Map output records=299797
Map output bytes=3001739
Map output materialized bytes=3601369
Input split bytes=846
Combine input records=0
Combine output records=0
Reduce input groups=92
Reduce shuffle bytes=3601369
Reduce input records=299797
Reduce output records=92
Spilled Records=599594
Shuffled Maps =6
Failed Shuffles=0
Merged Map outputs=6
GC time elapsed (ms)=513
Total committed heap usage (bytes)=3870818304
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=173576072
File Output Format Counters
Bytes Written=771
我们在发现在处理原生数据的时候,会花费大量的时间,我们需要对数据进行加工
所以这里我们引入ETL
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
- 全量的原始数据不方便进行计算,需要做一步处理进行相应的维度统计分析
- 解析需要的数据:ip ==》 城市信息
- 去除不需要的字段
ip/time/url/page_id/coutry/province/city
package com.bigdata.hadoop.mr.project.mrv2;
import com.bigdata.hadoop.mr.project.mrv1.PageStatApp;
import com.bigdata.hadoop.mr.project.utils.ContentUtils;
import com.bigdata.hadoop.mr.project.utils.LogParser;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Map;
public class ETLApp {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(configuration);
Path outputPath = new Path("input/etl");
if (fileSystem.exists(outputPath)) {
fileSystem.delete(outputPath, true);
}
Job job = Job.getInstance(configuration);
job.setJarByClass(ETLApp.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("input/raw/trackinfo_20130721.data"));
FileOutputFormat.setOutputPath(job, new Path("input/etl"));
job.waitForCompletion(true);
}
static class MyMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
private LongWritable ONE = new LongWritable(1);
private LogParser logParser;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
logParser = new LogParser();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String log = value.toString();
Map<String, String> info = logParser.parse(log);
String ip = info.get("ip");
String country = info.get("country");
String province = info.get("province");
String city = info.get("city");
String url = info.get("url");
String time = info.get("time");
String pageId = ContentUtils.getPageId(url);
StringBuilder builder = new StringBuilder();
builder.append(ip).append("\t");
builder.append(country).append("\t");
builder.append(province).append("\t");
builder.append(city).append("\t");
builder.append(url).append("\t");
builder.append(time).append("\t");
builder.append(pageId);
context.write(NullWritable.get(), new Text(builder.toString()));
}
}
}
106.3.114.42 中国 北京市 null http://www.yihaodian.com/2/?tracker_u=10325451727&tg=boomuserlist%3A%3A2463680&pl=www.61baobao.com&creative=30392663360&kw=&gclid=CPC2idPRv7gCFQVZpQodFhcABg&type=2 2013-07-21 11:24:56 -
58.219.82.109 中国 江苏省 无锡市 http://www.yihaodian.com/5/?tracker_u=2225501&type=4 2013-07-21 13:57:11 -
58.219.82.109 中国 江苏省 无锡市 http://search.yihaodian.com/s2/c0-0/k%25E7%25A6%258F%25E4%25B8%25B4%25E9%2597%25A8%25E9%2587%2591%25E5%2585%25B8%25E7%2589%25B9%25E9%2580%2589%25E4%25B8%259C%25E5%258C%2597%25E7%25B1%25B35kg%2520%25E5%259B%25BD%25E4%25BA%25A7%25E5%25A4%25A7%25E7%25B1%25B3%2520%25E6%2599%25B6%25E8%258E%25B9%25E5%2589%2594%25E9%2580%258F%2520%25E8%2587%25AA%25E7%2584%25B6%2520%2520/5/ 2013-07-21 13:50:48 -
58.219.82.109 中国 江苏省 无锡市 http://search.yihaodian.com/s2/c0-0/k%25E8%258C%25B6%25E8%258A%25B1%25E8%2582%25A5%25E7%259A%2582%25E7%259B%2592%25202213%2520%25E5%258D%25AB%25E7%2594%259F%25E7%259A%2582%25E7%259B%2592%2520%25E9%25A6%2599%25E7%259A%2582%25E7%259B%2592%2520%25E9%25A2%259C%25E8%2589%25B2%25E9%259A%258F%25E6%259C%25BA%2520%2520/5/ 2013-07-21 13:57:16 -
58.219.82.109 中国 江苏省 无锡市 http://www.yihaodian.com/5/?tracker_u=2225501&type=4 2013-07-21 13:50:13 -
218.11.179.22 中国 河北省 邢台市 http://www.yihaodian.com/2/?tracker_u=10861423206&type=1 2013-07-21 08:00:13 -
218.11.179.22 中国 河北省 邢台市 http://www.yihaodian.com/2/?tracker_u=10861423206&type=1 2013-07-21 08:00:20 -
123.123.202.45 中国 北京市 null http://search.1mall.com/s2/c0-0/k798%25203d%25E7%2594%25BB%25E5%25B1%2595%2520%25E5%259B%25A2%25E8%25B4%25AD/2/ 2013-07-21 11:55:28 -
123.123.202.45 中国 北京市 null http://t.1mall.com/100?grouponAreaId=3&uid=1ahrua02b8mvk0952dle&tracker_u=10691821467 2013-07-21 11:55:21 -
...........
功能升级
再etl的基础上改一下log即可
public Map<String, String> parseV2(String log) {
IPParser ipParser = IPParser.getInstance();
Map<String, String> info = new HashMap<>();
if (StringUtils.isNotBlank(log)) {
String[] splits = log.split("\t");
String ip = splits[0];
String country = splits[1] ;
String province = splits[2];
if(province.equals("null")){
province="其它";
}
String city = splits[3];
IPParser.RegionInfo regionInfo = ipParser.analyseIp(ip);
info.put("ip", ip);
info.put("country", country);
info.put("province", province);
info.put("city", city);
String url = splits[4];
info.put("url", url);
String time = splits[5];
info.put("time", time);
String client = splits[6];
info.put("client", client);
}
return info;
}

|
🐳 作者:hiszm 📢 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,万分感谢。 💬 留言:同时 , 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号