2015年上半年 软件设计师 上午试卷 综合知识-3

对高级语言源程序进行编译或解释的过程可以分为多个阶段,解释方式不包含(48)阶段。
解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间代码后再加以执行;而编译程序(编译器)则是将源程序翻译成目标语言程序,然后在计算机上运行目标程序。
简单来说,在解释方式下,翻译源程序时不生成独立的目标程序,而编译器则将源程序翻译成独立保存的目标程序。

某非确定的有限自动机(NFA)的状态转换图如下图所示(q0既是初态也是终态),与该NFA等价的确定的有限自动机(DFA)是(49)。
题目图

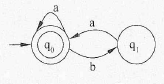
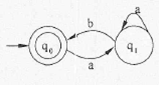
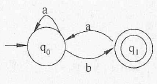
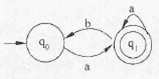
题中的NFA的功能是识别空串以及b不能连续出现(即每个b后至少含有1个a.) 的a、b字符串,若是非空串,则以a结尾。
选项A识别的是空串以及每个b后至少含有1个a的a、b字符串,若是非空串, 则以a结尾。
选项C识别b不能连续出现且以b结尾的a、b字符串,不能识别空串。
选项D识别b不能连续出现且以a结尾的a、b字符串,不能识别空串。


若关系R (H,L,M,P)的主键为全码(All-key),则关系R的主键应(51)。
C. 在集合{ HL,HM,HP,LM,LP,MP)中任选一个
在关系数据库系统中,全码(All-key)是指关系模型的所有属性组是这个关系模式的候选键,本题所有属性组为HLMP,故本题的正确选项为A。

给定关系模式R(A1,A2,A3,A4)上的函数依赖集F={A1A3->A2,A2->A3}。若将R分解为p ={( A1,A2),( A1,A3)},则该分解是(52)的。


(53)算法采用模拟生物进化的三个基本过程"繁殖(选择)-> 交叉(重组)->变异(突变)"。
①决策树:决策树方法是利用信息论中的互信息(信息增益)寻找数据库中具有最大信息量的属性字段,建立决策树的一个结点,再根据该属性字段的不同取值建设树的分支;在每个分支子集中重复建立树的下层结点和分支的过程。国际上最早的、也是最有影响的决策树方法是Quiulan研究的ID3方法。
②神经网络:神经网络方法是模拟人脑神经元结构,完成类似统计学中的判别、 回归、聚类等功能,是一种非线性的模型,主要有三种神经网络模型:前馈式网络、反馈式网络和自组织网络。人工神经网络最大的长处是可以自动地从数据中学习,形成知识,这些知识有些是我们过去未曾发现的,因此它具有较强的创新性。神经网络的知识体现在网络连接的权值上,神经网络的学习主要表现在神经网络权值的逐步计算上。
③遗传算法:遗传算法是模拟生物进化过程的算法,它由三个基本过程组成:繁殖(选择)、交叉(重组)、变异(突变)。采用遗传算法可以产生优良的后代,经过若干代的遗传,将得到满足要求的后代即问题得解。
④关联规则挖掘算法:关联规则是描述数据之间存在关系的规则,形式为 "A1A2...An=>B1B2...Bn"。一般分为两个步骤:求出大数据项集、用大数据项集产生关联规则。
除了上述的常用方法外,还有粗集方法,模糊集合方法,Bayesian Belief Netords , 最邻近算法(K-nearest Neighbors Method, kNN)等。

设栈S和队列Q的初始状态为空,元素a b c d e f g依次进入栈S。要求每个元素出栈后立即进入队列Q,若7个元素出队列的顺序为b d f e c a g,则栈S的容量最小应该是(58)。
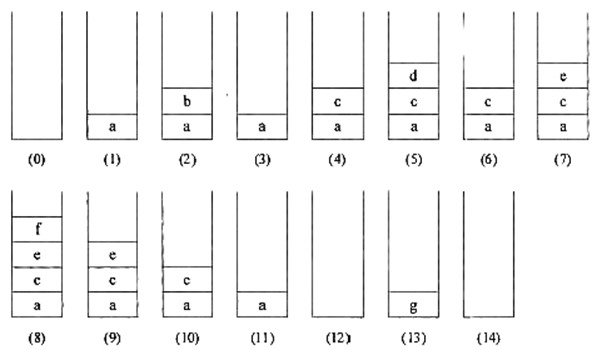

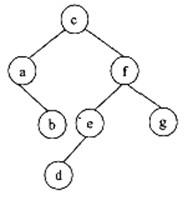
某二叉树的先序遍历序列为c a b f e d g ,中序遍历序列为a b c d e f g ,则该二叉树是(59)。
A. 完全二叉树 B. 最优二叉树(哈夫曼树) C. 平衡二叉树 D. 满二叉树

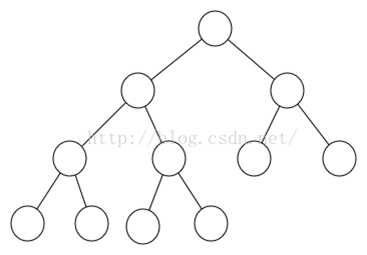
满二叉树:除了叶节点外每一个结点都有左右子女且叶节点都处在最底层的二叉树。
这个满二叉树应该很好想象,就是一颗非常完美的树,除了叶节点其他节点都有两个孩子。
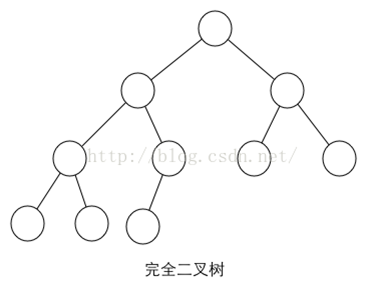
完全二叉树:只有最下面的两层结点度小于2,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
也就是说,在满叉树的基础上,我在最底层从右往左删去若干节点,得到的都是完全二叉树。
所以说,满二叉树一定是完全二叉树,但是完全二叉树不一定是满二叉树
平衡二叉树:又称为AVL树,它是一颗空树或它的左右两个子树的高度差的绝对值不超过1
注意到这里,哈夫曼树只是一棵最优二叉树,不一定是完全二叉树,也不一定是平衡二叉树。完全是八竿子打不着的事情,人家哈夫曼树不关注树的结构,只关注带权路径长度好吗。。
下面再说几点关于二叉树性质,对于解答笔试题中的小题目很有用。
1.对于一棵有着k层的二叉树,最多有节点个数为 2^k-1,最少有k个节点
3.对于一棵非空的二叉树,叶子节点数目总比度为2的节点数要多1
引用于 http://blog.csdn.net/jaster_wisdom/article/details/51472271

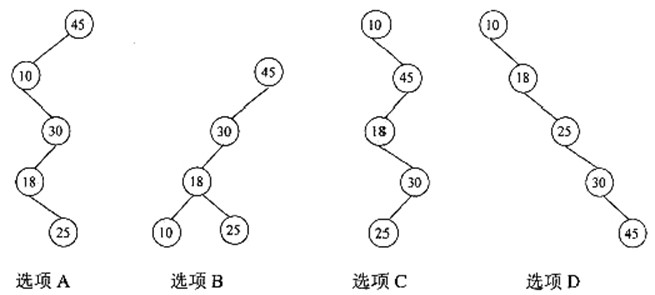
对某有序顺序表进行折半查找时,(60)不可能构成查找过程中关键字的比较序列。
A. 45,10,30,18,25 B. 45,30,18,25,10 C. 10,45,18,30,25 D. 10,18,25,30,45

优先队列通常采用(62)数据结构实现,向优先队列中插入—个元素的时间复杂度为(63)。

在下图所示的网络配置中,发现工作站B无法与服务器A通信。(66)故障影响了两者互通。
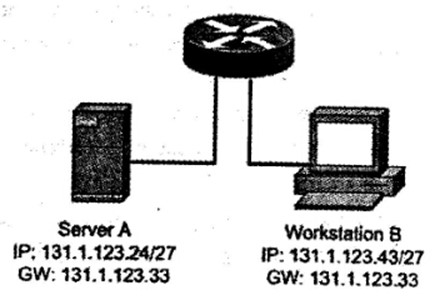
服务器A的IP地址 131.1.123.24/27: 10000011.00000001. 01111011.00011000 服务器A的地址不是广播地址。
服务器A的网关地址 131.1.123.33: 10000011.00000001. 01111011.00100001 这个地址与服务器A的地址不属于同一个子网。
工作站B的IP地址131.1.123.43/27: 10000011.00000001.01111011.00101011 这个地址不是网络地址。
工作站B的网关地址131.1.123.33: 10000011.00000001. 01111011.00100001 工作站B与网关属于同一个子网。

A. 使用www.abc.com和abc.com打开的是同一页面
B. 在地址栏中输入www.abc.com默认使用http协议
URL由三部分组成:资源类型、存放资源的主机域名、资源文件名。
protocol :// hostname[:port] / path /filename
一般情况下,一个URL可以采用"主机名.域名"的形式打开指定页面,也可以单独使用"域名"来打开指定页面,但是这样实现的前提是需进行相应的设置和对应。

CP协议的功能是(69);FTP使用的传输层协议为(70)。
DHCP协议的功能是自动分配IP地址;FTP协议的作用是文件传输,使用的传输层协议为TCP。

A. 版本控制 B. 变更控制 C. 过程支持 D. 质量控制
软件配置管理SCM用于整个软件工程过程,其主要目标是标识变更、控制变更、确保变更正确的实现,报告变更。其主要内容包括版本管理、配置支持、变更支持、过 程支持、团队支持、变化报告和审计支持等。
|
🐳 作者:hiszm 📢 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,万分感谢。 💬 留言:同时 , 如果文中有什么错误,欢迎指出。以免更多的人被误导。 |
 |

