
整理自:
https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1
- 各种熵的计算
- 常用的树搭建方法
- 防止过拟合—剪枝
- 前剪枝的几种停止条件
1.各种熵的计算
熵、联合熵、条件熵、交叉熵、KL散度(相对熵)
- 熵用于衡量不确定性,所以均分的时候熵最大
- KL散度用于度量两个分布的不相似性,KL(p||q)等于交叉熵H(p,q)-熵H(p)。交叉熵可以看成是用q编码P所需的bit数,减去p本身需要的bit数,KL散度相当于用q编码p需要的额外bits。
- 交互信息Mutual information :I(x,y) = H(x)-H(x|y) = H(y)-H(y|x) 表示观察到x后,y的熵会减少多少。
2.常用的树搭建方法
ID3、C4.5、CART分别利用信息增益、信息增益率、Gini指数作为数据分割标准。
- 其中信息增益衡量按照某个特征分割前后熵的减少程度,其实就是上面说的交互信息。

- 用上述信息增益会出现优先选择具有较多属性的特征,毕竟分的越细的属性确定性越高。所以提出了信息增益率的概念,让含有较多属性的特征的作用降低。
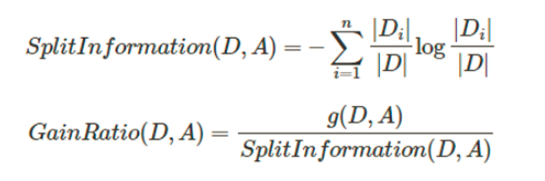
- CART树在分类过程中使用的基尼指数Gini,只能用于切分二叉树,而且和ID3、C4.5树不同,Cart树不会在每一个步骤删除所用特征。
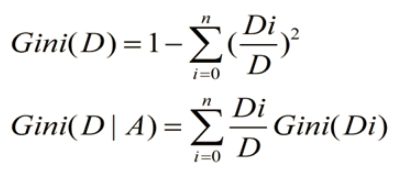
3.防止过拟合—剪枝
剪枝分为前剪枝和后剪枝,前剪枝本质就是早停止,后剪枝通常是通过衡量剪枝后损失函数变化来决定是否剪枝。后剪枝有:错误率降低剪枝、悲观剪枝、代价复杂度剪枝
4.前剪枝的几种停止条件
- 节点中样本为同一类
- 特征不足返回多类
- 如果某个分支没有值则返回父节点中的多类
- 样本个数小于阈值返回多类
年岁有加并非垂老
理想丢弃方堕暮年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号