
处理从文件中读数据
官方说明
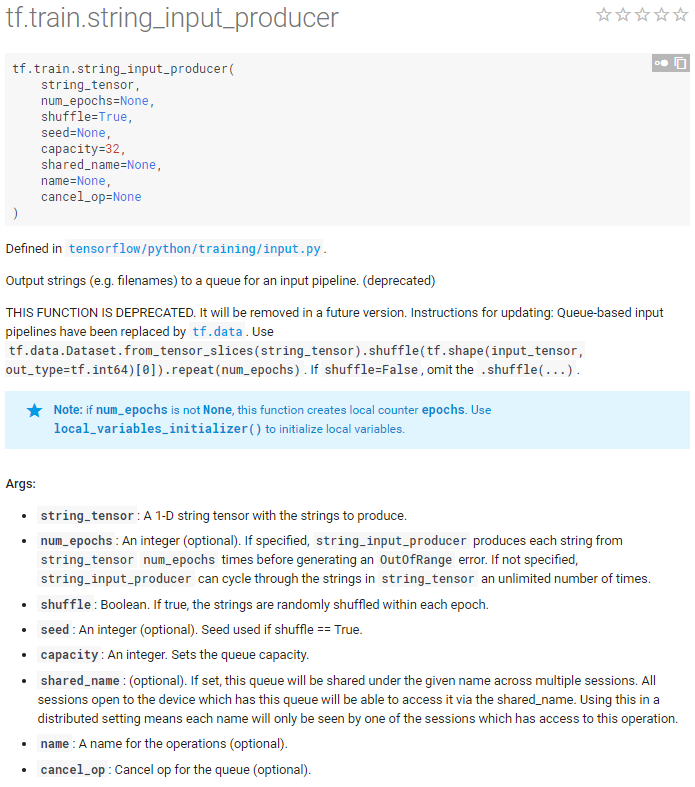
简单使用
示例中读取的是csv文件,如果要读tfrecord的文件,需要换成 tf.TFRecordReader
import tensorflow as tf filename_queue = tf.train.string_input_producer(["file0.csv", "file1.csv"]) reader = tf.TextLineReader() key, value = reader.read(filename_queue) # Default values, in case of empty columns. Also specifies the type of the decoded result. record_defaults = [[1], [1], [1], [1], [1]] col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults=record_defaults) features = tf.stack([col1, col2, col3, col4]) with tf.Session() as sess: # Start populating the filename queue. coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) for i in range(12): # Retrieve a single instance: example, label = sess.run([features, col5]) print(example, label) coord.request_stop() coord.join(threads)
运行结果:

结合批处理
import tensorflow as tf def read_my_file_format(filename_queue): # reader = tf.SomeReader() reader = tf.TextLineReader() key, record_string = reader.read(filename_queue) # example, label = tf.some_decoder(record_string) record_defaults = [[1], [1], [1], [1], [1]] col1, col2, col3, col4, col5 = tf.decode_csv(record_string, record_defaults=record_defaults) # processed_example = some_processing(example) features = tf.stack([col1, col2, col3, col4]) return features, col5 def input_pipeline(filenames, batch_size, num_epochs=None): filename_queue = tf.train.string_input_producer(filenames, num_epochs=num_epochs, shuffle=True) example, label = read_my_file_format(filename_queue) # min_after_dequeue + (num_threads + a small safety margin) * batch_size min_after_dequeue = 100 capacity = min_after_dequeue + 3 * batch_size example_batch, label_batch = tf.train.shuffle_batch([example, label], batch_size=batch_size, capacity=capacity, min_after_dequeue=min_after_dequeue) return example_batch, label_batch x,y = input_pipeline(["file0.csv", "file1.csv"],5,4) sess = tf.Session() sess.run([tf.global_variables_initializer(),tf.initialize_local_variables()]) coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(sess=sess, coord=coord) try: print("in try") while not coord.should_stop(): # Run training steps or whatever example, label = sess.run([x,y]) print(example, label) print("ssss") except tf.errors.OutOfRangeError: print ('Done training -- epoch limit reached') finally: # When done, ask the threads to stop. coord.request_stop() # Wait for threads to finish. coord.join(threads) sess.close()
运行结果:

年岁有加并非垂老
理想丢弃方堕暮年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号