

调优:
1.GC常用的垃圾清除算法
Java:new?
自动内存回收,鞭编程上简单,系统不容易出错,手动释放内存,容易出现两种类型的问题:
1. 忘记回收
2. 多次回收
问题:什么是垃圾?
没有任何引用指向对象或者多个对象(循环引用)。
1.定位垃圾:
引用计数(Reference Counting【Python】):
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
跟可达算法(RootSearching)
2.常见的垃圾回收算法
标记清除(Mark-Sweep): 位置不连续 产生碎片 效率偏低(两边扫描)
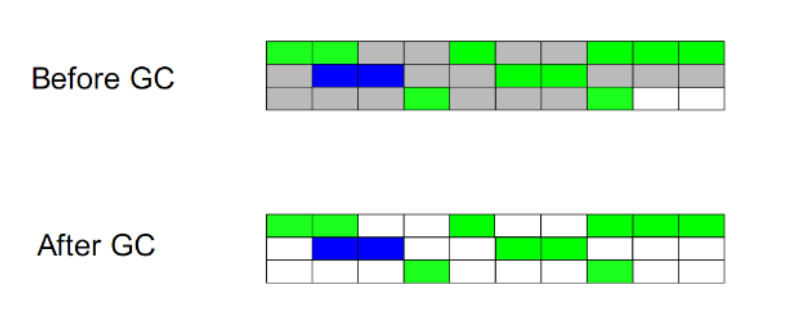
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
拷贝算法(Copying): 没有碎片 浪费空间
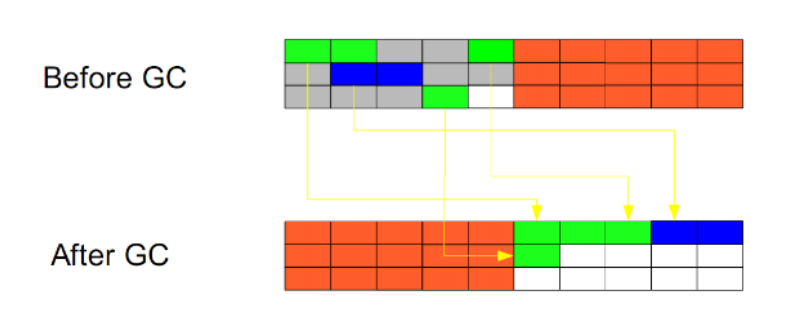
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
标记压缩(Mark-Compact): 没有碎片 效率偏低(两边扫描,指针需要调整)
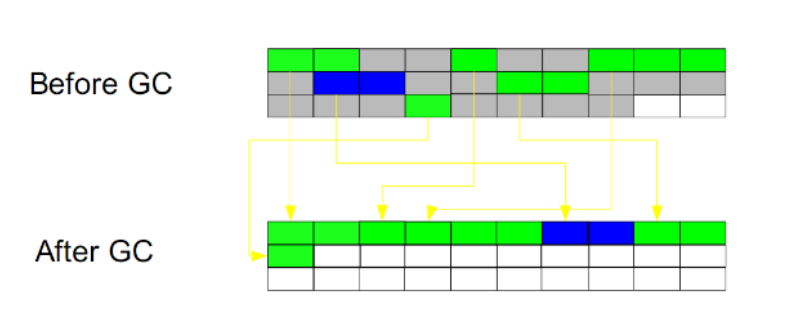
此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
2.JVM内存分代模型(用于分代垃圾回收算法)
1.按分区对待的方式分
增量收集(Incremental Collecting):
实时垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
分代收集(Generational Collecting):
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
2.按系统线程分
串行收集:
串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
并行收集:
并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
并发收集:
相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。
3.堆内存逻辑分区
1、垃圾回收器的选择
低延迟:CMS、G1、ZGC
高吞吐量:ParallelGC
2、最快的GC是不发生GC
数据是不是太多,例如:在查询大表的数据时,添加limit进行限制
对象的使用:用哪一个对象就查哪一个对象
对象的大小:能用基本类型就不用包装类型,例如:Integer占用24字节,而int占用4字节
代码中是否存在内存泄漏
3、新生代调优(old/tenured)
(1)新生代特点
所有的 new 操作的内存分配非常廉价
死亡对象的回收代价是零(复制的是存活的对象,死亡的对象直接清除了)
大部分对象用过即死
Minor GC的时间远远低于Full GC
(2)新生代是不是越大越好
较小的话易发生Minor-GC,Minor-GC的时候会出现 STW 造成时间增加
较大的话,老年代的内存就会变小,易发生垃圾回收(Full-GC),暂停时间要比新生代的暂停时间更长
Oracle建议的新生代内存大小为:占用堆内存的百分之25-百分之50
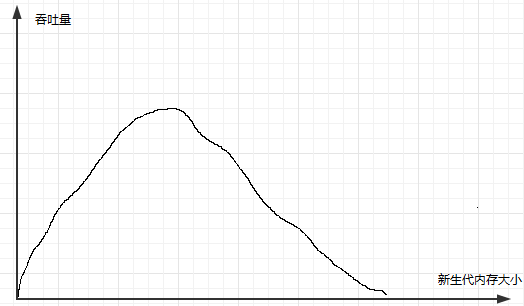
新生代的复制算法分为标记和复制两个阶段,复制要花费的时间更多,新生代的对象只有少量的对象能够存活,因此,复制的时间较少,即使新生代有较大的内存,回收的效率依旧不会太高
(3)幸存区
幸存区要能够保留:当前活跃对象和需要晋升的对象
幸存区的晋升阈值设置要合理,阈值太大的话,幸存区的幸存对象会被多次复制,阈值过小的话,晋升后的对象进入老年带后就只有Full-GC的时候才会被清理
4、老年代(new/young)
以CMS为例:
CMS的老年代内存越大越好:
因为垃圾处理线程和用户的线程是并发的,当垃圾处理的时候,用户的线程还会产生垃圾(浮动垃圾),如果再次导致内存不足,就会导致并发失败。退化为Serial-old,串行的垃圾回收器,响应时间较长
先尝试不去调优,因为如果未发生Full-GC,则证明老年代的内存正常,可以尝试调优新生代
如果老年代发生了Full-GC,就去观察发生Full-GC的时候老年代的内存占用,将老年代的内存预设调大1/4-1/3
4.对象的栈上分配
我们通过JVM内存分配可以知道Java中的对象都是在堆上进行分配,当对象没有被引用的的时候,需要靠GC进行回收内存,如果对象内存数量比较多的时候,会给GC带来很大的压力,也间接影响了应用的性能。为了减少临时对象在堆内分配的数量,JVM通过逃逸分析确定该对象不会被外部访问,如果不会逃逸可以将该对象栈上分配内存,这样该对象占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。
对象逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中。
常见的垃圾回收器

注解:JDK诞生的时候,Serial就追随了。为了提高效率,诞生了PS,为了配合CMS,就诞生了PN,CMS是1.4版本后期引入,CMS是里程碑式的GC,它开启了并发回收的过程,但是CMS毛病也比较多,因此目前任何一个JDK版本默认是CMS。
1.Serial年轻代串行回收
2.PS (Parallel Scavenge) 年轻代并行回收
4.ParNew 年轻代 配合CMS 的并行回收
5.SerialOld
6.ParallelOld
7.Concurrent Mark Sweep 老年代并发的,垃圾回收和应用程序同时运行,会降低STW 短时间(200ms)
CMS问题比较多,所以现在没有一个版本默认是CMS,只能手工指定
CMS既然是MarkSweep,就一定有碎片化的问题,碎片到达一定程度,CMS的老年代分配对象分配不下的时候,就使用SerialOld进行老年代回收。
试想一下:
PS+PO -> 加内存 换垃圾垃圾回收器 -> PN + CMS + SerialOld(几个小时 - 几天的STW),十几个G的内存,单线程回收 -> G1 + FGC十几个G -> 上T内存的服务器ZGC
算法: 三色标记 + Incremental Update
8.G1(10ms)
算法:三色标记 + SATB
9.ZGC(1ms)PK C++
算法:ColoredPointers + 写屏障
10.Shenandoah
算法:ColoredPointers + 读屏障
11.Eplison
12 垃圾回收器跟内存大小的关系
1. Serial 几十兆
2.PS上百兆 - 几个G
3.CMS - 20G
4. G1 - 上百G
5.ZGC - 4T
JDK1.8版本默认的垃圾回收器:PS + ParallelOld
5.常见垃圾回收器组合参数设定:(1.8)
- -XX:+UseSerialGC = Serial New(DefNew)+Serial Old
- 小型程序,默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器
- -XX:+UseParNewGC = ParNew+SerialOld UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
- 这个已经很少使用(某些版本之中已经废弃)
- -XX:+UseParallelGC = Parallel Scavenge + Parallel Old(1.8默认)【PS + Serial Old】
- -XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
- -XX:+UseG1GC = G1
- Linux中没找到默认GC的查看方法,而Windows中会打印UseParallelGC
- Java +XX:+PrintCommandLineFlags -version
- 通过GC的日志来分辨
-
- 1.8.0_181 默认(看不出来)Copy MarkCompact
- 1.8.0_222 默认 PS + PO
6.了解jVM常用命令行参数
- JVM的命令行参数参考:java (oracle.com)
- HotSpot参数分类
- 标准:开头,所有的HotSpot都支持
- 非标准: -X 开头,特定版本 HotSpot支持特定的命令
- 不稳定:-XX 开头,下个版本可能取消
java -version
java -X
什么的调优?
调优前的基础概念:
1. 吞吐量:用户代码时间 / (用户代码执行时间 + 垃圾回收时间)
2.相应时间:STW越短,相应时间越好
注意:首先确定,追求啥?吞吐量优先,还是时间优先? 还是在一定的相应时间的情况下,要求达到多大的吞吐量?.....
科学计算,吞吐量,数据挖掘,thrput。吞吐量优先选择的垃圾回收器:(PS + PO)
相应时间: 网站 GUI API (1.8G1)
1.根据需求进行JVM规划和预调优
- 调优,从规划开始
- 调优,从业务场景开始,没有业务场景的调优都是耍流氓
- 无监控(压力测试,能看到结果),不调优
- 步骤:
1.熟悉业务场景(没有最好的垃圾回收器,只有最合适的垃圾回收器)
1.相应时间,停顿时间(CMS G1 ZGC)需要给用户响应
2.吞吐量 = 用户时间 / (用户时间 + GC时间)[PS]
2.选择回收器组合
3.计算内存需求(经验值 1.5G 16G)
4.设定年代大小,升级年龄
5.设定日志参数
1.-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFile=5
-XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps-XX:+PrintGCCause
2.或者每天生产一个日志文件
6.观察日志情况
2.优化运行JVM运行环境
1.有一个50万PV的资料科类网站(从磁盘提取文档到内存)服务器32位,1.5G的堆,用户反馈网站比较慢,因此公司决定升级,新的服务器为64 位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了,为什么?
1.为什么原网站慢?
很多用户浏览数据,因此就有很多数据到内存中,导致内存不足,频繁GC,STW长,响应时间变慢。
如何优化?
2.为什么会更卡顿?
内存越大 ,FGC时间越长
3.怎么解决?
PS -> PN + CMS 或者 G1
2.系统CPU经常100%,如何调优?(面试高频)
一定有线程占用系统资源。找出哪个进程(使用 top命令)中的哪个线程比较高(top - Hp),导出该线程中的堆栈(jstack),查找出哪个方法(栈帧)消耗时间(jstack)。
3.系统内存飙高,如何查找问题?(面试高频)
1.导出堆内存(jmap)
2.分析(jhat jvisualvm mat jprofiler ....)
4.如何监控JVM
jstat jvisualvm jprofiler jprofiler artjas top...
3.解决JVM运行过程中出现的各种问题
1. 案例
2. java -Xms200M -Xmx200M -XX:+PrintGC demo04day.T15_FullGC_Problem01
3.一般是运维团队收到报警信息(CPU Memory)
4.top命令观察到问题:内存不断增长 CPU占用率居高不下
5.top -Hp 观察进程中的线程,是哪个线程CPU和内存占比高
6.jps定位具体Java进程
jstack定位线程状况,重点关注:WAITING BLOCKED等待获得锁
waiting on<0x00000000000088ca3310>(s java.lang.Object)
假如有这么一个进程中有100个线程,很多线程都在waiting on<xxx>,一定要找到是哪个线程持有这把锁。
这么找呢?搜索jstack dump的信息,找<xxx>,看哪个线程持有这把锁RUNNABLE
7.为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称
怎么样自定义线程池里的线程名称?(自定义ThreadFactory)
8.jinfo pid
9.jstat -gc 动态观察gc情况/阅读GC日志发现频繁GC / arthas观察 / jconsole / jvisualVM / Jprofiler(最好用,但收费)
jstat -gc 4566 500 :每个500毫秒打印GC情况。如果面试官问你 怎么定位 OOM问题?如果你回答用图形化界面 (错误)
1. 已经上线的系统不用图形化界面的,那用什么呢?使用(cmdline arthas)
2.图形化界面用在什么地方呢?测试,测试的时候进行监控!(压测观察)
10.jmap -histo 4566 | head -20,查找有多少对象产生
线上系统。一般都是内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1.设定了参数HeapDump,OOM的时候会自动产生堆转储文件
2.很多服务器备份(高可用),停掉这台服务器不会对其他服务器产生影响
3.在线定位(一般小一点儿的公司用不到)
11.jmap -dump:format=b,file=xxx pid / jmap -histo
12.java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutMemoryError
com.mashibing.jvm.gc.T15_fullGC_Problem01
13.使用MAT / jhat 进行dump文件分析
14.找到代码问题
4.jvisualvm远程连接
https://www.cnblogs.com/liugh/p/7620336.html(简单做法)
jprofiler(收费)
arthas在线排查工具
- 为什么需要在线排查?
- 在生产线上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的Threaddump或者heapdump不好查到原因。问了排查到这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参数。然后重新打包发布,如果打印了日志还是没找到问题,基础加日志,重新打包发布。对于线上流程复杂而且审核比较严格的公司从改代码到上线需要层层的流转,会大大影响问题排查的进度。
- jvm观察jvm信息
- thead定位线程问题
- dashboard观察系统情况
1.程序启动加入参数
java -Djava.rmi.server.hostname=192.168.17.11 -Dcom.sun.management.jmxremote -
Dcom.sun.management.jmxremote.port=11111 -
Dcom.sun.management.jmxremote.authenticate=false -
Dcom.sun.management.jmxremote.ssl=false xxx
2.如果遭遇 Local host name unknown: XXX的错误,修改/etc/hosts文件,把XXX加进去
192.168.17.11 bsic localhost localhost.localdomain localhost4
localhost4.localdomain4
::1 localhost localshot.localdomain localhost6 localhost6.localdomain6
3.关闭Linux防火墙(实战中应该打开对应端口)
service iptables stop
chkconfig iptables off #永久关闭
4.windows上打开 jconsole 远程连接 192.168.17.11:11111

 浙公网安备 33010602011771号
浙公网安备 33010602011771号