

参考链接:https://www.cnblogs.com/wangyong/p/8523814.html
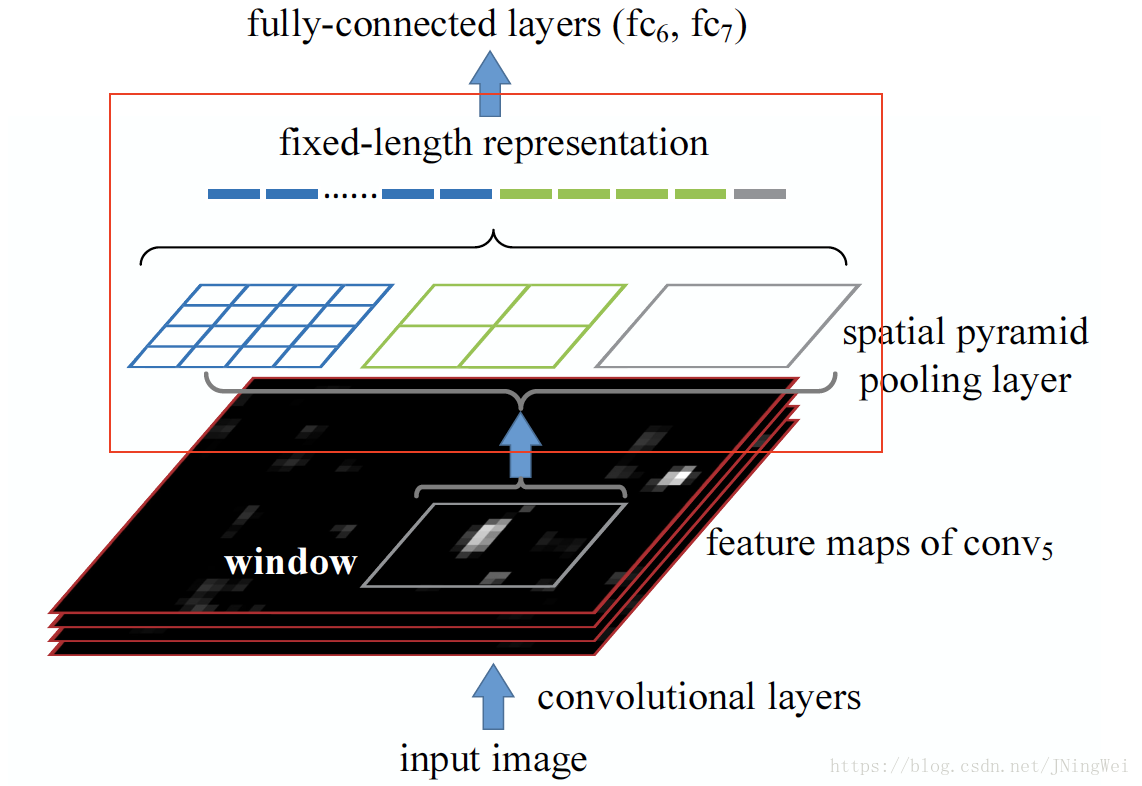
SPP Layer
对RoI进行pooling的操作最早由SPPNet中的SPP layer提出:
提出的好处是:对RoI进行pooling,检测网络便可以输入任意size的图片。
RoIPooling
在Faster RCNN中继承了SPP layer的精髓,并简化了该设计,提出了RoIPooling。使用RolPooling,检测网络便可以输入任意size的图片,所以生成的候选框region proposal映射会在全连接层之前产生固定大小的feature map。
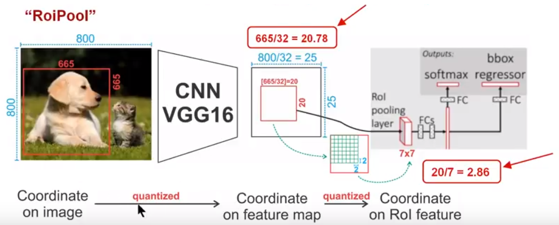
针对上图
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800*800,最后一层特征图feature map大小:25*25
2)假定原图中有一region proposal,大小为665*665,这样,映射到特征图中的大小:665/32=20.78,即20.78*20.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20*20
3)假定pooled_w=7,pooled_h=7,即pooling后固定成7*7大小的特征图,所以,将上面在 feature map上映射的20*20的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.86*2.86,此时,进行第二次量化,故小区域大小变成2*2
4)每个2*2的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成7*7大小的feature map
从上面可以看出来RoIPooling缺点是由于 RoIPooling 采用的是 INTER_NEAREST(即最近邻插值) ,即在resize时,对于 缩放后坐标不能刚好为整数 的情况,采用了 粗暴的四舍五入,相当于选取离目标点最近的点,在一定程度上损失了空间对称性,这样的像素偏差势必会对后层的回归定位产生影响。
总结,所以,通过上面可以看出,经过两次量化,即将浮点数取整,原本在特征图上映射的20*20大小的region proposal,偏差成大小为14*14的,这样的像素偏差势必会对后层的回归定位产生影响
所以,产生了替代方案,RoiAlign。
RoIAlign
在Mask RCNN里把 最近邻插值 换成了 双线性插值 ,换完插值法的 RoIPooling 就有了一个更加高大上的名字 —— RoIAlign :

同样,针对上图,有着类似的映射
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800*800,最后一层特征图feature map大小:25*25
2)假定原图中有一region proposal,大小为665*665,这样,映射到特征图中的大小:665/32=20.78,即20.78*20.78,此时,没有像RoiPooling那样就行取整操作,保留浮点数
3)假定pooled_w=7,pooled_h=7,即pooling后固定成7*7大小的特征图,所以,将在 feature map上映射的20.78*20.78的region proposal 划分成49个同等大小的小区域,每个小区域的大小20.78/7=2.97,即2.97*2.97
4)假定采样点数为4,即表示,对于每个2.97*2.97的小区域,平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,如下图

上图中,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的
最后,取四个像素值中最大值作为这个小区域(即:2.97*2.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成7*7大小的feature map。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号