容器基础-- namespace,Cgroup 和 UnionFS
Namespace
什么是 Namespace ?
这里的 "namespace" 指的是 Linux namespace 技术,它是 Linux 内核实现的一种隔离方案。简而言之,Linux 操作系统能够为不同的进程分配不同的 namespace,每个 namespace 都具有独立的资源分配,从而实现了进程间的隔离。如果你的 Linux 安装了 GCC,可以通过运行 man namespaces 命令来查看相关文档,或者你也可以访问在线手册获取更多信息。
介绍
下图为各种 namespace 的参数,支持的起始内核版本,以及隔离内容。
| Namespace | 系统调用参数 | 内核版本 | 隔离内容 |
|---|---|---|---|
| UTS (Unix Time-sharing System) | CLONE_NEWUTS | Linux 2.4.19 | 主机名与域名 |
| IPC (Inter-Process Communication) | CLONE_NEWIPC | Linux 2.6.19 | 信号量、消息队列和共享内存 |
| PID (Process ID) | CLONE_NEWPID | Linux 2.6.19 | 进程编号 |
| Network | CLONE_NEWNET | Linux 2.6.24 | 网络设备、网络栈、端口等等 |
| Mount | CLONE_NEWNS | Linux 2.6.29 | 挂载点(文件系统) |
| User | CLONE_NEWUSER | Linux 3.8 | 用户和用户组 |
- PID Namespace:
- 不同用户的进程通过 PID Namespace 进行隔离,并且不同的 Namespace 中可以有相同的进程 ID。在 Docker 中,所有的 LXC(Linux 容器)进程的父进程是 Docker 进程,每个 LXC 进程具有不同的 Namespace。由于支持嵌套 Namespace,因此可以方便地实现 Docker 中的 Docker(Docker in Docker)。
- Net Namespace:
- 有了 PID Namespace,每个 Namespace 中的进程能够相互隔离,但是网络端口仍然共享主机的端口。通过 Net Namespace 实现网络隔离,每个 Net Namespace 具有独立的网络设备、IP 地址、IP 路由表和 /proc/net 目录。这样,每个容器的网络就能够得到隔离。Docker 默认使用 veth(虚拟以太网)方式将容器中的虚拟网卡与主机上的 Docker 桥接器(docker0)连接起来。
- IPC Namespace:
- 容器中的进程仍然使用常见的 Linux 进程间通信(IPC)方法,包括信号量、消息队列和共享内存。然而,与虚拟机不同的是,容器中的进程实际上是在具有相同 PID Namespace 的主机进程之间进行通信,因此在申请 IPC 资源时需要加入 Namespace 信息,每个 IPC 资源都有一个唯一的 32 位 ID。
- MNT Namespace:
- 类似于 chroot,将进程限制在特定的目录下执行。MNT Namespace 允许不同 Namespace 的进程看到不同的文件结构,从而隔离了每个 Namespace 中进程所看到的文件目录。与 chroot 不同的是,每个 Namespace 中的容器在 /proc/mounts 中的信息仅包含所在 Namespace 的挂载点。
- UTS Namespace:
- UTS("UNIX Time-sharing System")Namespace 允许每个容器拥有独立的主机名和域名,使其在网络上可以被视为一个独立的节点,而不仅仅是主机上的一个进程。
- User Namespace:
- 每个容器可以具有不同的用户和组 ID,这意味着容器内部的程序可以使用容器内部的用户执行,而不是主机上的用户。
涉及到三个系统调用(system call)的 API:
- clone():用于创建新进程。与 fork() 创建新进程不同的是,clone() 创建进程时可以传递 CLONE_NEW* 类型的命名空间隔离参数,以控制子进程共享的内容。要了解更多信息,请查阅clone 手册。
- setns():用于将某个进程与指定的命名空间分离。通过 setns(),进程可以脱离一个特定的命名空间,使其不再与该命名空间中的其他进程共享资源。
- unshare():用于将某个进程加入到指定的命名空间中。通过 unshare(),进程可以加入到一个特定的命名空间,与该命名空间中的其他进程共享资源。
namespace 的操作
- 查看当前系统的 namespace
lsns –t <type>
- 查看某进程的 namespace
ls -la /proc/<pid>/ns/
- 进入某 namespace 运行命令
nsenter -t <pid> -n ip addr
Test:
# Linux命令行中,可以使用`unshare`命令结合`clone()`创建一个新的进程,并在其中使用命名空间隔离参数。
# 创建一个新的进程,并在其中使用命名空间隔离参数
unshare --pid --net -- sleep 600
ps -ef|grep sleep
root 37915 34572 0 08:53 pts/1 00:00:00 sudo unshare --pid --net -- sleep 600
root 37916 37915 0 08:53 pts/3 00:00:00 sudo unshare --pid --net -- sleep 600
root 37917 37916 0 08:53 pts/3 00:00:00 sleep 600
zhy 37919 37896 0 08:53 pts/2 00:00:00 grep --color=auto sleep
sudo lsns -t net
[sudo] password for zhy:
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 277 1 root unassigned /sbin/init
4026532656 net 1 37347 root 0 /run/docker/netns/c986b82be683 bash
4026532718 net 1 37917 root unassigned sleep 600
sudo nsenter -t 37917 -n ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
- docker 启动一个 ubuntu
docker run --rm -it docker.m.daocloud.io/ubuntu:22.10 bash
- 用另一个窗口 找到这个进程
ps -ef|grep ubuntu
# zhy 37247 34017 0 08:20 pts/0 00:00:00 docker run --rm -it docker.m.daocloud.io/ubuntu:22.10 bash
- 查看这个进程的 namespace
ls -la /proc/37247/ns/
total 0
dr-x--x--x 2 zhy zhy 0 May 27 08:24 .
dr-xr-xr-x 9 zhy zhy 0 May 27 08:23 ..
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 mnt -> 'mnt:[4026531841]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 net -> 'net:[4026531840]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 time -> 'time:[4026531834]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 user -> 'user:[4026531837]'
lrwxrwxrwx 1 zhy zhy 0 May 27 08:24 uts -> 'uts:[4026531838]'
- 查看namespace
sudo lsns -t pid
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 275 1 root /sbin/init
4026532654 pid 1 37347 root bash
sudo lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 275 1 root unassigned /sbin/init
4026532656 net 1 37347 root 0 /run/docker/netns/c986b82be683 bash
为什么查出来执行 **bash** 的 pid 和 **ps -ef** 的不一样?
一个是docker run的进程 PID
一个是 容器内部 'bash' 进程的 PID 这个进程是由docker run的进程通过进程复制(process cloning)创建的子进程。
- 在 ubuntu 中执行
ip addr在主机执行nsenter -t <pid> -n ip addr
# 容器内
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 08:23 pts/0 00:00:00 bash
root 360 1 0 09:12 pts/0 00:00:00 ps -ef
# 主机
sudo nsenter -t 37347 -n -- ip addr # -n 进入网络namespace执行
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
sudo nsenter -t 37347 -a -- ps -ef # -a 进入所有namespace执行
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 08:23 pts/0 00:00:00 bash
root 359 0 0 09:12 ? 00:00:00 ps -ef
Cgroup
什么是 Cgroup
Linux cgroups 的全称是 Linux Control Groups,它是 Linux 内核的特性,主要作用是限制、记录和隔离进程组(process groups)使用的物理资源(cpu、memory、IO 等)。
为什么要使用Cgroup?
可以做到对 cpu,内存等资源实现精细化的控制,容器技术就使用了 cgroups 提供的资源限制能力来完成cpu,内存等部分的资源控制。
核心概念
- task:任务,对应于系统中运行的一个实体,一般是指进程
- subsystem:子系统,具体的资源控制器(resource class 或者 resource controller),控制某个特定的资源使用。比如 CPU 子系统可以控制 CPU 时间,memory 子系统可以控制内存使用量
- cgroup:控制组,一组任务和子系统的关联关系,表示对这些任务进行怎样的资源管理策略
- hierarchy:层级有一系列 cgroup 以一个树状结构排列而成,每个层级通过绑定对应的子系统进行资源控制。层级中的 cgroup 节点可以包含零个或多个子节点,子节点继承父节点挂载的子系统。一个操作系统中可以有多个层级。
subsystem
subsystem 是一组资源控制的模块,一般包含有:
- blkio 设置对块设备 (比如硬盘) 的输入输出的访问控制 (block/io)
- cpu 设置 cgroup 中的进程的 CPU 被调度的策略
- cpuacct 可以统计 cgroup 中的进程的 CPU 占用 (cpu account)
- cpuset 在多核机器上设置 cgroup 中的进程可以使用的 CPU 和内存 (此处内存仅使用于 NUMA 架构)
- devices 控制 cgroup 中进程对设备的访问
- freezer 用于挂起 (suspends) 和恢复 (resumes) cgroup 中的进程
- memory 用于控制 cgroup 中进程的内存占用
- net_cls 用于将 cgroup 中进程产生的网络包分类 (classify),以便 Linux 的 tc (traffic controller) (net_classify) 可以根据分类 (classid) 区分出来自某个 cgroup 的包并做限流或监控。
- net_prio 设置 cgroup 中进程产生的网络流量的优先级
- ns 这个 subsystem 比较特殊,它的作用是 cgroup 中进程在新的 namespace fork 新进程 (NEWNS) 时,创建出一个新的 cgroup,这个 cgroup 包含新的 namespace 中进程。
v2
Cgroup v2手册
是否加载了Cgroup v2内核模块
cat /sys/fs/cgroup/cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misc
test
Cpu
执行一段go代码
package main
func main() {
go func() { for{} }()
for {}
}
/*
执行 go run test.go
top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
39268 zhy 20 0 709572 868 584 R 200.0 0.0 2:12.27 test
可以看到使用了2个cpu 因为开个两个goroutine for阻塞
*/
限制cpu
sudo mkdir /sys/fs/cgroup/test
sudo echo "100000 100000" | sudo tee /sys/fs/cgroup/test/cpu.max >/dev/null
sudo echo "39268" | sudo tee /sys/fs/cgroup/test/cgroup.procs >/dev/null
# top
# PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
# 39268 zhy 20 0 709572 868 584 R 100.3 0.0 7:45.04 test
# 马上就只占用一个cpu了
Memory
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#define BLOCK_SIZE (100 * 1024 * 1024)
#define NUM_ALLOCATIONS 10
#define SLEEP_SECONDS 30
char* allocMemory(int size) {
char* out = (char*)malloc(size);
memset(out, 'A', size);
return out;
}
int main() {
int i;
for (i = 1; i <= NUM_ALLOCATIONS; i++) {
char* block = allocMemory(i * BLOCK_SIZE);
printf("Allocated memory block of size %dMB at address: %p\n", i * 100, block);
sleep(SLEEP_SECONDS);
}
return 0;
}
/*
ps -p 3243 -o rss=,unit=M,cmd=
M
308512 session-4.scope ./test2
*/
限制内存
sudo echo "300000000" |sudo tee /sys/fs/cgroup/test/memory.max >/dev/null
sudo echo "64417" | sudo tee /sys/fs/cgroup/test/cgroup.procs >/dev/null
#cat memory.current
#299839488
UnionFS
联合文件系统(UnionFS)是一种分层、轻量级并且高性能的文件系统,它支持对文件系统的修改作为一次提交来一层层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下 (unite several directories into a single virtual filesystem)。
联合文件系统是 Docker 镜像的基础。镜像可以通过分层来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。
另外,不同 Docker 容器就可以共享一些基础的文件系统层,同时再加上自己独有的改动层,大大提高了存储的效率。
最新版 Docker 使用的是 overlay2。
overlay2
现在主流基本都是 overlayFS
OverlayFS 属于文件级的存储驱动,包含了最初的 Overlay 和更新更稳定的 overlay2。
Overlay 只有两层:upper 层和 lower 层,Lower 层代表镜像层,upper 层代表容器可写层。
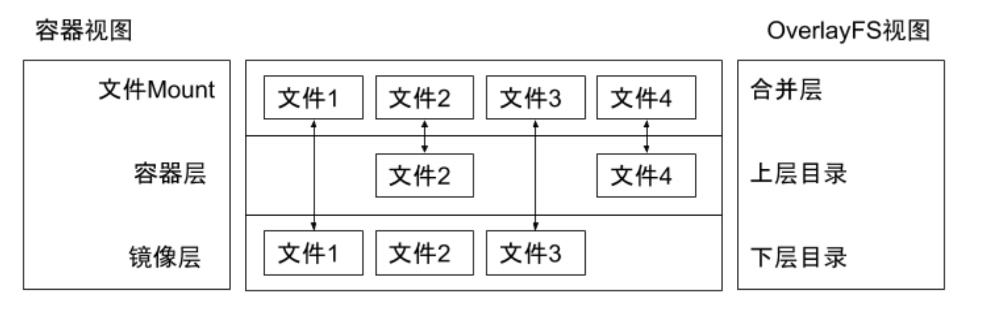
test
mkdir test && cd test
mkdir upper lower merged work
echo "file1 from lower" > lower/file1.txt
echo "file2 from lowerr" > lower/file2.txt
echo "file3 from lower" > lower/file3.txt
echo "file2 from upper" > upper/file2.txt
echo "file4 from upper" > upper/file4.txt
current_dir=$(pwd)
sudo mount -t overlay -o lowerdir="$current_dir/lower",upperdir="$current_dir/upper",workdir="$current_dir/work" overlay "$current_dir/merged"
cat merged/file1.txt
file1 from lower
cat merged/file2.txt
file2 from upper
cat merged/file3.txt
file3 from lower
cat merged/file4.txt
file4 from upper
docker image
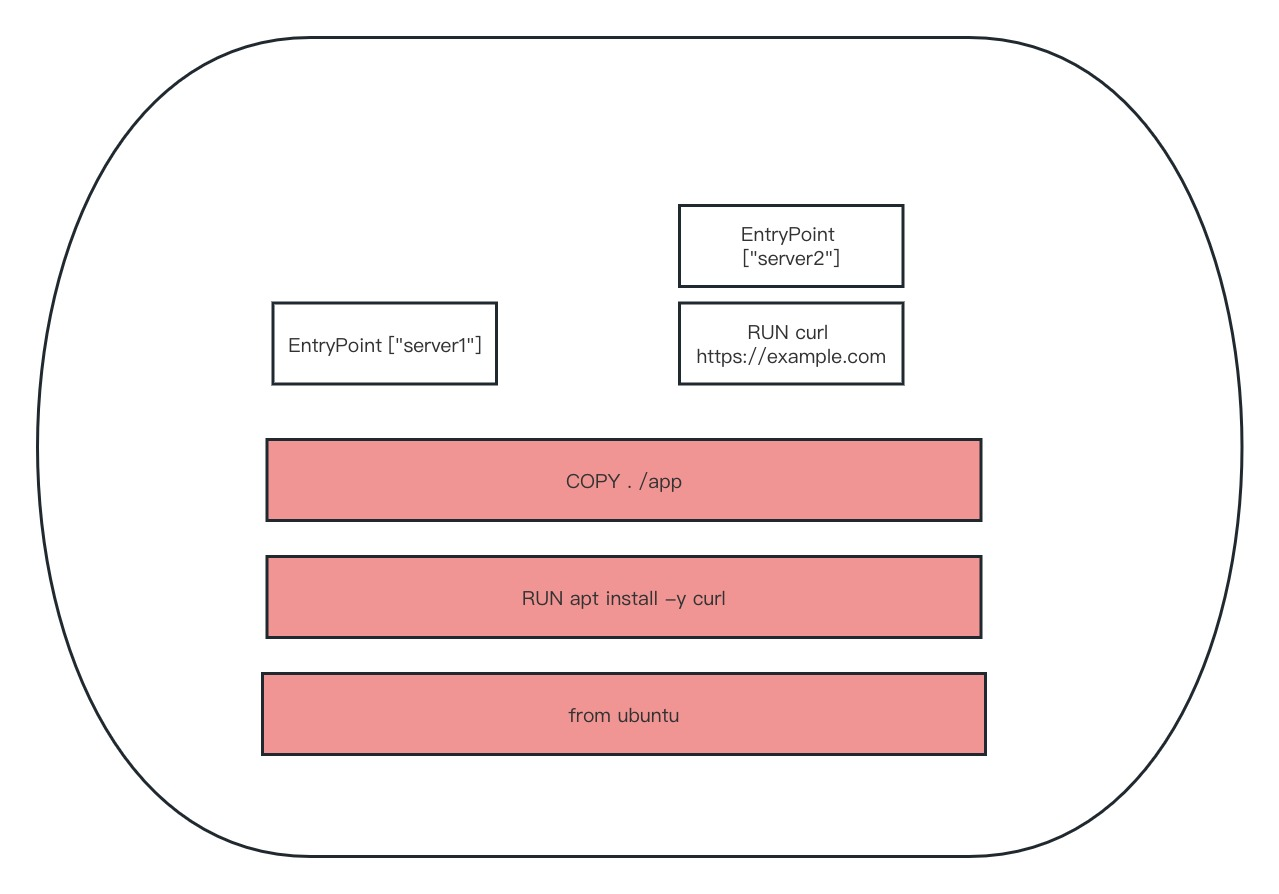
每一条指令是一层, 下层可以共用
Docker 的文件系统
典型的Linux文件系统组成如下:
- Bootfs(引导文件系统)
- Bootloader(引导加载程序):负责加载内核。
- Kernel(内核):一旦内核加载到内存中,就会卸载bootfs。
- Rootfs(根文件系统)
- /dev、/proc、/bin、/etc等标准目录和文件。
- 对于不同的Linux发行版,bootfs基本上是一致的,但rootfs会有所差异。
Docker 启动
Linux
- 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查,然后将其切换为 “readwrite” 供用户使用。
Docker 启动
- 初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个 readwrite 文件系统挂载在 readonly 的 rootfs 之上;
- 并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加。 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态,每一个 FS 被称作一个 FS 层。
写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖存储驱动提供的写时复制和用时分配机制,以此来 支持对容器可写层的修改,进而提高对存储和内存资源的利用率。
- 写时复制 即 Copy-on-Write。
- 一个镜像可以被多个容器使用,但是不需要在内存和磁盘上做多个拷贝。
- 在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统 进行修改,而镜像里面的文件不会改变。
- 不同容器对文件的修改都相互独立、互不影响。
- 用时分配
- 按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号