
事情是这样的,最近领导给了一个新的需求,要求在一张订单表中统计每个人第一次和第二次购买的时间间隔,最后还需要按照间隔统计计数,求出中位数等数据。
- 由于MySQL不想Oracle那般支持行号、中位数等,所以怎么在表中统计处数据成为了关键
订单表结构,主要包含字段如下
- id、订单号、购买人id、下单时间、商品信息字段、购买人信息字段等
1.为了方便后续统计,我的想法是构建了一张中间表,只存储一些关键字段,如购买人id,下单时间,订单号,以及购买的第几次,结构如下图:

字段解释:fans_id:购买人id、order_time:下单时间、tid:订单号、series:商品系列、shop:店铺、times:第几次购买、sync_time:同步时间、effective:是否有效、failure_time:失效时间
2.写了一段代码,处理历史订单,把所有数据按照表中格式添加进去,方便统计,每次新订单进来时,更新一下这个表即可。
3.统计:
-- 统计购买次数最大和最小
select max(times) from 统计表 where effective = '有效'
-- 统计最大购买次数间隔、最小间隔以及平均间隔(中位数的话,由于MySQL没有中位数函数,所以可以利用子查询的SQL通过程序代码计算)
SELECT
max(date) as max,
min(date) as min,
sum( date * mans ) / count( mans ) as avg
FROM
(
SELECT
ifnull(datediff( a.order_time, ( SELECT order_time FROM 统计表 WHERE times = 次数1 AND effective = '有效' AND a.fans_id = fans_id ) ),0) AS date,
a.fans_id,
1 AS mans
FROM
统计表 a
WHERE
a.times = 次数2 AND effective = '有效'
) t
4.由于接收订单后,可能状态会变,无法确保次数准确,更新统计表中每个人的次数SQL如下:
UPDATE
(SELECT @rownum:=@rownum+1 as rn,id,fans_id,order_time from
(SELECT id,fans_id,order_time from
统计表 where fans_id = 购买人 and effective = '有效'
ORDER BY order_time asc) h,
(SELECT @rownum:=0) t) t1,
statistics_repurchase t2
set t2.times=t1.rn where t2.id=t1.id;
5.由于需求还需要支持按照商品系列查询,所以需要在该表基础之上建立临时表以作统计,满足MySQL在按照某个字段分组、排序加序号
第一版SQL如下:
SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
-- 按照购买人id,按照购买时间进行排序,并标记序号,加上创建表语句如下(建表时需加索引,方便后续查找):
CREATE TABLE 临时表名 (
id INT PRIMARY KEY AUTO_INCREMENT,
fans_id VARCHAR ( 32 ),
order_time datetime,
sync_time date,
times INT ( 6 ),
PRIMARY KEY ( id ),
INDEX mid_fans_id ( fans_id ) USING BTREE,
INDEX mid_order_time ( order_time ) USING BTREE,
INDEX mid_times ( times ) USING BTREE,
INDEX mid_sync_time ( sync_time ) USING BTREE
)
AS
(
SELECT
a.fans_id,
a.order_time,
a.sync_time,
count( * ) AS times
FROM
统计表 AS a,
统计表 AS b
WHERE
a.fans_id = b.fans_id
AND a.order_time >= b.order_time
AND a.effective = '有效'
AND b.effective = '有效'
AND a.series LIKE concat('%','系列','%')
AND b.series LIKE concat('%','系列','%')
GROUP BY
a.fans_id,
a.id
);
-- 由于数据库版本为5.4,所以建完临时表不支持一条sql多次查询,没办法,只能直接创建表
结果如图:
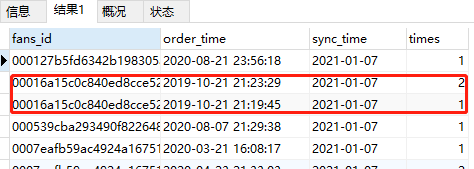
满足了排序,但是后来我发现有一些人是同时间下单的,以至于某些人的times是重复的,于是更新为下面的SQL
SELECT
a.fans_id,
a.order_time,
a.sync_time,
( @i := CASE WHEN @pre_keyword = fans_id THEN @i + 1 ELSE 1 END ) AS times,
@pre_keyword:=fans_id
FROM
( SELECT fans_id, order_time, sync_time FROM 统计表 WHERE effective = '有效' AND series LIKE concat('%','系列','%') ORDER BY fans_id,order_time ) a,
( SELECT @i := 0, @pre_keyword := '' ) AS b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号