一.合成器
1.合成器的文本输入被处理成512维的character embedding,具体如下图所示:
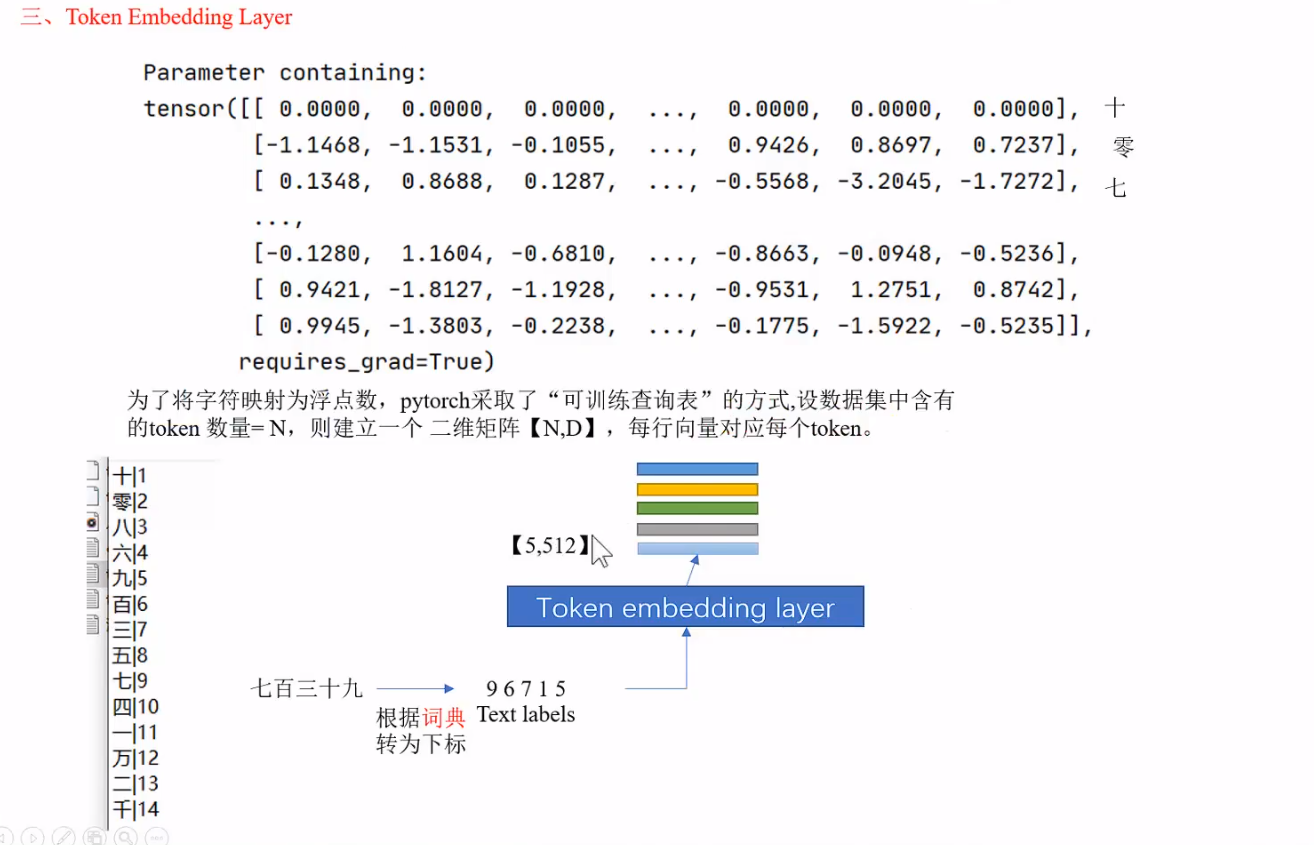
2.建议参考B站视频:语音合成超简洁训练代码框架
二.GSTs
1.由于原Tacotron的encoder输出为256维度,与说话人编码器的输出speaker embedding(也是256维)连接后变为512维,为了匹配文本编码器的维数,每个token嵌入为512维。
2.梅尔频谱经过reference encoder后输出256维的嵌入,该嵌入与speaker embedding拼接得到512维的reference embedding,最后将reference embedding输入style layer得到512维的输出style embedding。
3.参考CSDN文章:论文阅读 Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
 管理
管理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号