
一.参考论文以及项目源码
1.知乎网址:语音合成论文优选:Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
2.github项目源码:
二.移植模块具体代码
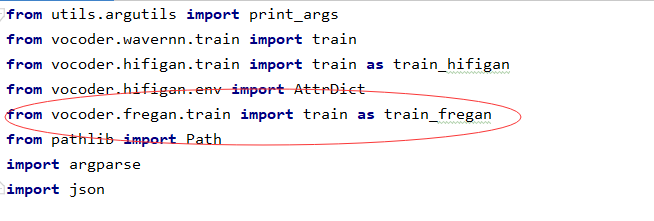
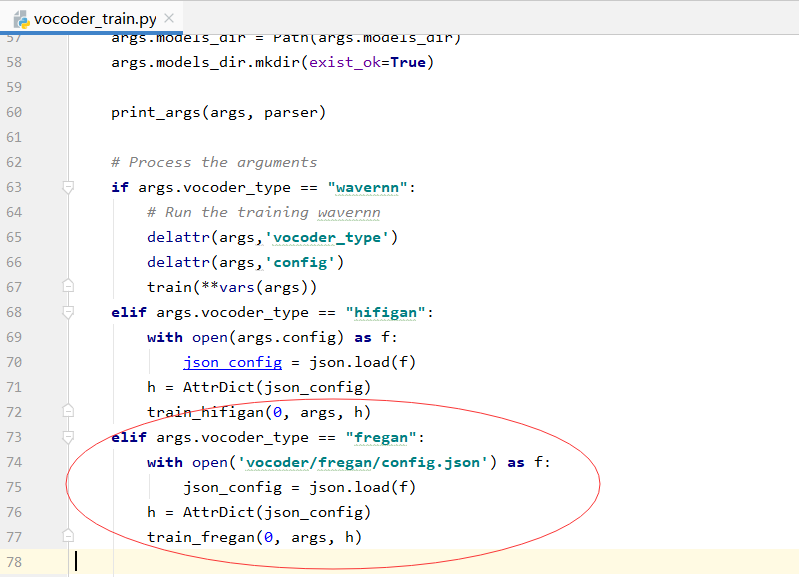
1.vocodr_train.py中:选择需要训练的预训练模型
2.fregan/train.py和meldataset中:
(1)导入文件作相应修改
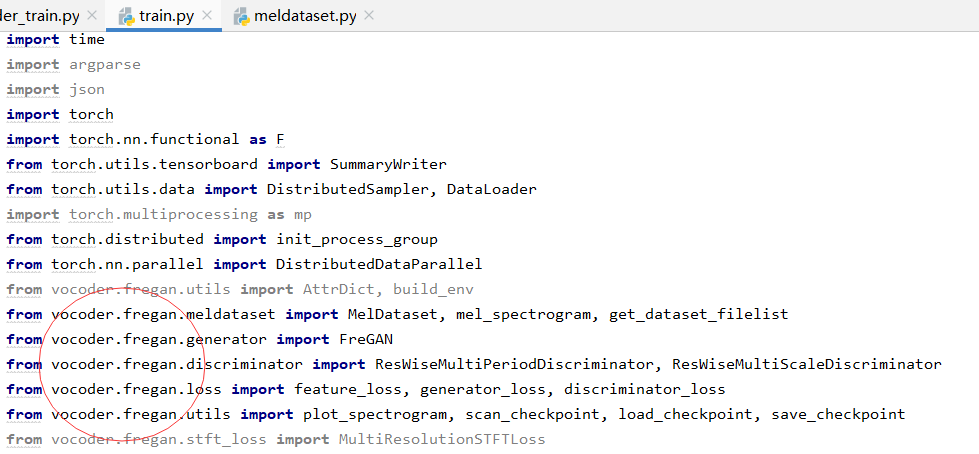
(2)对照hifigan中代码修改(添加#等)
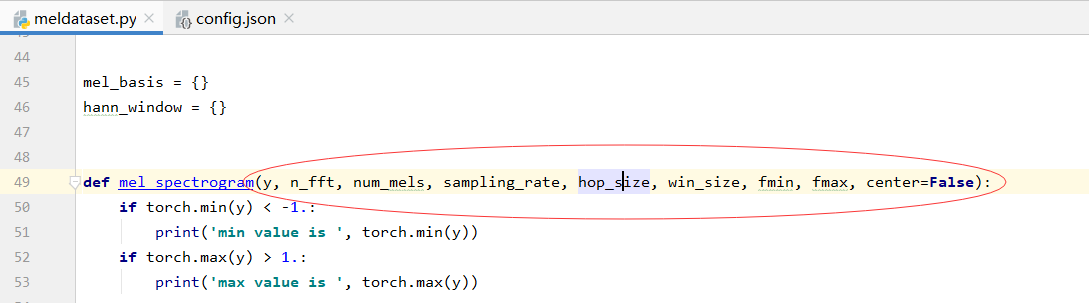
3.在config.json中对训练参数进行配置,重点关注对输入频谱的处理函数传入参数
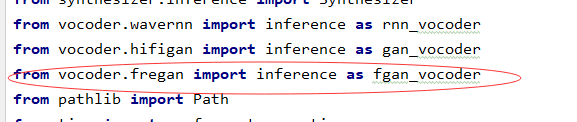
4.fregan文件夹下添加inference.py
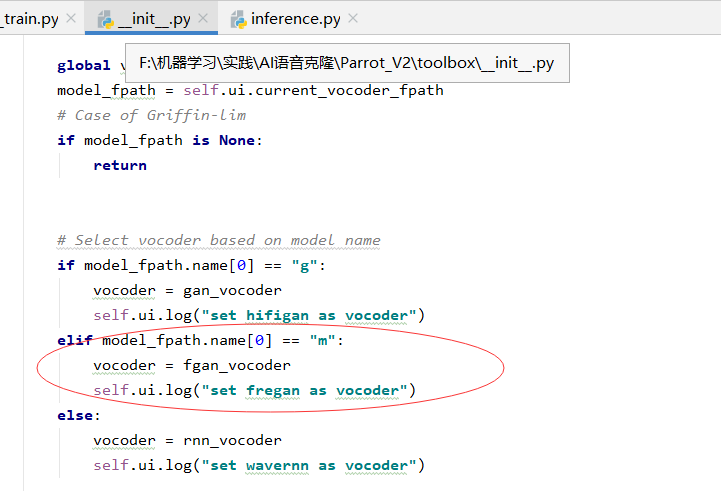
5.在ui界面中加载预训练的fregan模型
三.训练声码器模型
1.github作者教程

2.实际操作:
训练指令为:
hifigan:
预训练:python vocoder_preprocess.py F:\机器学习\实践\AI语音克隆\data -m F:\机器学习\实践\AI语音克隆\Parrot_V2\synthesizer\saved_models\fly_4_110k
python vocoder_train.py myvo F:\机器学习\实践\AI语音克隆\data hifigan
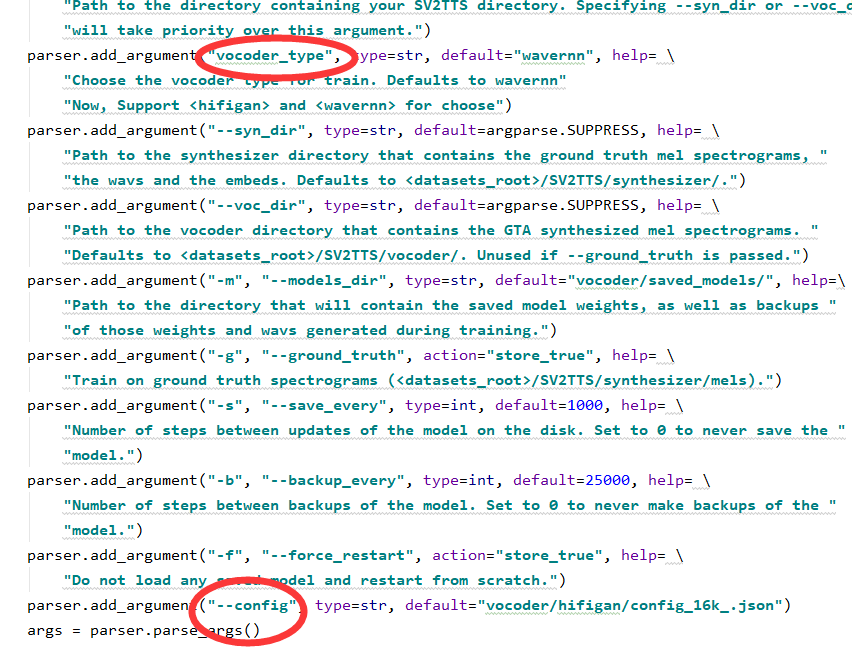
fregan:
python vocoder_train.py myvo F:\机器学习\实践\AI语音克隆\data --config config.json fregan
PS:本次Fre-GAN声码器的移植在训练时出现报错且已解决!
/data/cpf/Parrot_V3/vocoder/fregan/train.py:166: UserWarning: Using a target size (torch.Size([16, 80, 40])) that is different to the input size (torch.Size([16, 80, 32])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size.
loss_mel = F.l1_loss(y_mel, y_g_hat_mel) * 45
Traceback (most recent call last):
File "vocoder_train.py", line 77, in
train_fregan(0, args, h)
File "/data/cpf/Parrot_V3/vocoder/fregan/train.py", line 166, in train
loss_mel = F.l1_loss(y_mel, y_g_hat_mel) * 45
File "/home/llp/.conda/envs/pytorch/lib/python3.8/site-packages/torch/nn/functional.py", line 3080, in l1_loss
expanded_input, expanded_target = torch.broadcast_tensors(input, target)
File "/home/llp/.conda/envs/pytorch/lib/python3.8/site-packages/torch/functional.py", line 72, in broadcast_tensors
return _VF.broadcast_tensors(tensors) # type: ignore[attr-defined]
RuntimeError: The size of tensor a (32) must match the size of tensor b (40) at non-singleton dimension 2
大概意思应该是y_mel和y_g_hat_mel的张量维度不相同

 浙公网安备 33010602011771号
浙公网安备 33010602011771号