
一.本次关于该项目的UI修改较为复杂,主要目的如下:
1.打开本地源音频时同时生成MFCC分析折线图和MFCC平均归一化热图,用的是创建子窗口并显示图片的方法
2.生成克隆音频时同时生成MFCC分析折线图和MFCC平均归一化热图,方法同上
二.MFCC生成源码
1.参考CSDN网址:MFCC python实现
三.在ui.py文件中添加槽函数
1.
#添加source_mfcc分析函数
def plot_mfcc(self, wav, sample_rate):
signal = wav
print(sample_rate, len(signal))
# 读取前3.5s 的数据
signal = signal[0:int(3.5 * sample_rate)]
print(signal)
# 预先处理
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
frame_size = 0.025
frame_stride = 0.1
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate
signal_length = len(emphasized_signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
num_frames = int(numpy.ceil(float(numpy.abs(signal_length - frame_length)) / frame_step))
pad_signal_length = num_frames * frame_step + frame_length
z = numpy.zeros((pad_signal_length - signal_length))
pad_signal = numpy.append(emphasized_signal, z)
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(
numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[numpy.mat(indices).astype(numpy.int32, copy=False)]
# 加上汉明窗
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # Explicit Implementation **
# 傅立叶变换和功率谱
NFFT = 512
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
# print(mag_frames.shape)
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum
low_freq_mel = 0
# 将频率转换为Mel
nfilt = 40
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700))
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10 ** (mel_points / 2595) - 1)) # Convert Mel to Hz
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
# 所得到的倒谱系数2-13被保留,其余的被丢弃
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1: (num_ceps + 1)]
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
cep_lifter = 22
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift # *
# filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
print(mfcc.shape)
# 创建新的figure
fig10 = plt.figure(figsize=(16,8))
# 绘制1x2两行两列共四个图,编号从1开始
ax = fig10.add_subplot(121)
plt.plot(mfcc)
ax = fig10.add_subplot(122)
# 平均归一化MFCC
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
plt.imshow(numpy.flipud(mfcc.T), cmap=plt.cm.jet, aspect=0.2,
extent=[0, mfcc.shape[0], 0, mfcc.shape[1]]) # 热力图
#将figure保存为png并显示在新创建的子窗口上
plt.savefig("fmcc.png")
dialog_fault = QDialog()
dialog_fault.setWindowTitle("源音频MFCC特征图及MFCC平均归一化热图") # 设置窗口名
pic = QPixmap("fmcc.png")
label_pic = QLabel("show", dialog_fault)
label_pic.setPixmap(pic)
label_pic.setGeometry(0,0,1500,800)
dialog_fault.exec_()
#添加result_mfcc分析函数
def plot_mfcc1(self, wav, sample_rate):
signal = wav
print(sample_rate, len(signal))
# 读取前3.5s 的数据
signal = signal[0:int(3.5 * sample_rate)]
print(signal)
# 预先处理
pre_emphasis = 0.97
emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1])
frame_size = 0.025
frame_stride = 0.1
frame_length, frame_step = frame_size * sample_rate, frame_stride * sample_rate
signal_length = len(emphasized_signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
num_frames = int(numpy.ceil(float(numpy.abs(signal_length - frame_length)) / frame_step))
pad_signal_length = num_frames * frame_step + frame_length
z = numpy.zeros((pad_signal_length - signal_length))
pad_signal = numpy.append(emphasized_signal, z)
indices = numpy.tile(numpy.arange(0, frame_length), (num_frames, 1)) + numpy.tile(
numpy.arange(0, num_frames * frame_step, frame_step), (frame_length, 1)).T
frames = pad_signal[numpy.mat(indices).astype(numpy.int32, copy=False)]
# 加上汉明窗
frames *= numpy.hamming(frame_length)
# frames *= 0.54 - 0.46 * numpy.cos((2 * numpy.pi * n) / (frame_length - 1)) # Explicit Implementation **
# 傅立叶变换和功率谱
NFFT = 512
mag_frames = numpy.absolute(numpy.fft.rfft(frames, NFFT)) # Magnitude of the FFT
# print(mag_frames.shape)
pow_frames = ((1.0 / NFFT) * ((mag_frames) ** 2)) # Power Spectrum
low_freq_mel = 0
# 将频率转换为Mel
nfilt = 40
high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700))
mel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scale
hz_points = (700 * (10 ** (mel_points / 2595) - 1)) # Convert Mel to Hz
bin = numpy.floor((NFFT + 1) * hz_points / sample_rate)
fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))
for m in range(1, nfilt + 1):
f_m_minus = int(bin[m - 1]) # left
f_m = int(bin[m]) # center
f_m_plus = int(bin[m + 1]) # right
for k in range(f_m_minus, f_m):
fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1])
for k in range(f_m, f_m_plus):
fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])
filter_banks = numpy.dot(pow_frames, fbank.T)
filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stability
filter_banks = 20 * numpy.log10(filter_banks) # dB
# 所得到的倒谱系数2-13被保留,其余的被丢弃
num_ceps = 12
mfcc = dct(filter_banks, type=2, axis=1, norm='ortho')[:, 1: (num_ceps + 1)]
(nframes, ncoeff) = mfcc.shape
n = numpy.arange(ncoeff)
cep_lifter = 22
lift = 1 + (cep_lifter / 2) * numpy.sin(numpy.pi * n / cep_lifter)
mfcc *= lift # *
# filter_banks -= (numpy.mean(filter_banks, axis=0) + 1e-8)
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
print(mfcc.shape)
# 创建新的figure
fig11 = plt.figure(figsize=(16,8)) #设置figure尺寸
# 绘制1x2两行两列共四个图,编号从1开始
ax = fig11.add_subplot(121)
plt.plot(mfcc)
ax = fig11.add_subplot(122)
# 平均归一化MFCC
mfcc -= (numpy.mean(mfcc, axis=0) + 1e-8)
plt.imshow(numpy.flipud(mfcc.T), cmap=plt.cm.jet, aspect=0.2,
extent=[0, mfcc.shape[0], 0, mfcc.shape[1]]) # 热力图
#将figure保存为png并显示在新创建的子窗口上
plt.savefig("fmcc1.png")
dialog_fault1 = QDialog()
dialog_fault1.setWindowTitle("合成音频MFCC特征图及MFCC平均归一化热图") # 设置窗口名
pic = QPixmap("fmcc1.png")
label_pic = QLabel("show", dialog_fault1)
label_pic.setPixmap(pic)
label_pic.setGeometry(0,0,1500,800) #设置子窗口尺寸
dialog_fault1.exec_()
四.在__init__.py文件中添加信号与槽连接的函数
1.
#添加source_mfcc分析槽
func = lambda: self.ui.plot_mfcc(self.ui.selected_utterance.wav, Synthesizer.sample_rate)
self.ui.browser_browse_button.clicked.connect(func)
# 添加result_mfcc分析槽,该槽要在语音合成之后
func = lambda: self.ui.plot_mfcc1(self.current_wav, Synthesizer.sample_rate)
self.ui.generate_button.clicked.connect(func)
五.修改效果
1.打开源音频后:
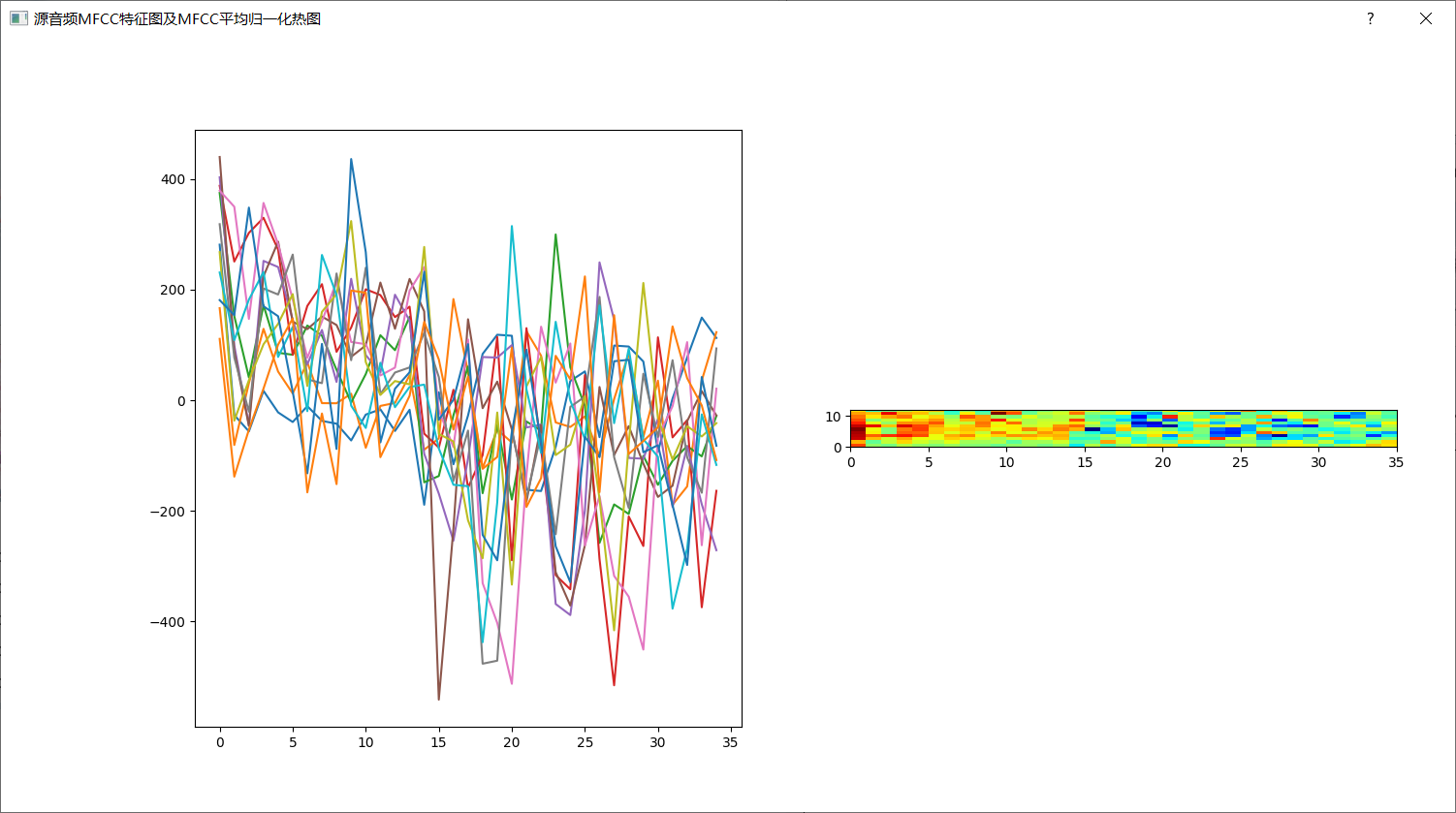
2.合成音频后:
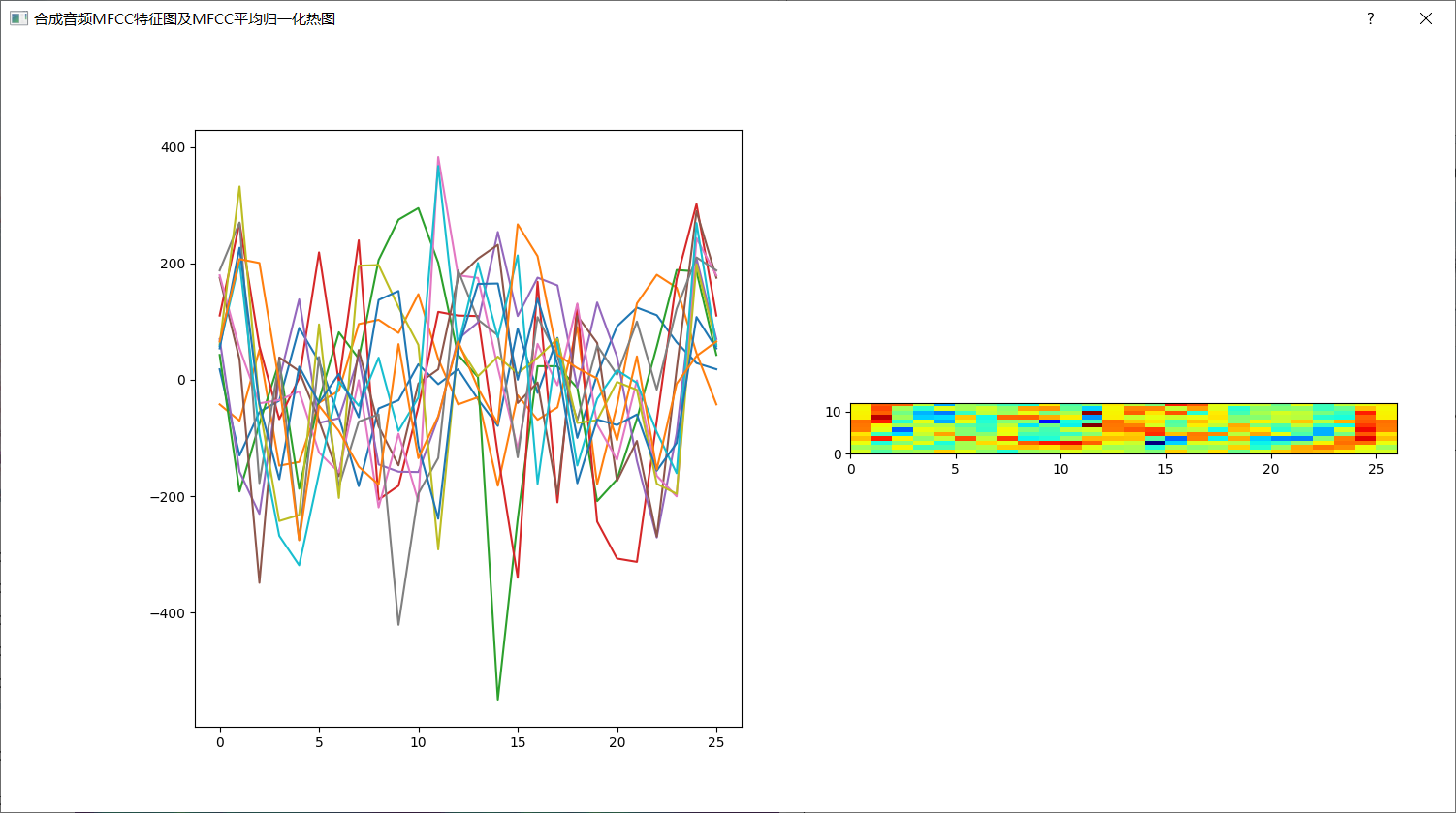
六.小结
1.首先关键要找到源音频和合成音频对应的变量名,在此分别是self.ui.selected_utterance.wav和self.current_wav
2.按照变量名等关键字,找到类似控件的函数,比如Play和Replay,照葫芦画瓢创建槽函数以及信号-槽连接函数
3.根据报错来import MFCC所需要的包
4.python代码是顺序执行的,因此result_mfcc分析槽,该槽要在语音合成槽self.synthesize之后
5.pyqt5中不能通过按键触发plt.show()函数,因此我另辟蹊径找到创建子窗口,先保存figure为图片,并显示图片的方法。
csdn参考地址:https://blog.csdn.net/huoxingrenhdh/article/details/116646582

 浙公网安备 33010602011771号
浙公网安备 33010602011771号