

空间数据是由图形和属性组成的,它们是怎么被组织到一起的,空间索引、属性索引是怎么实现的,记录排列的顺序有什么讲究,图形按什么策略读取的,又是怎么被渲染的,空间查询、空间分析是怎么实现的,图形编辑又如何?带着这样的疑问,首先让大家有一个框架流程上的认识,有了这样的一个框架,后面才能就框架里的每个环节逐一详细研究,这里我们重点讨论GIS矢量数据。
空间数据一般是分图层的,类型和属性相似的图元被组织到一个图层里,一个图层对应一张表,一个图元就是其中的一条记录,这张表里的所有图元(记录)具有相同的属性字段,每张表通常由属性字段和图形字段组成。

图元的坐标数据存储在Geometry字段中,其实有的底层Geometry也是单独管理的,这里只存储图形和属性关联的索引信息,即图形文件中此图元坐标序列的文件起始地址(数据库最底层也是通过文件磁盘管理实现的),而在图形文件中也存储了相应属性记录的索引位置。在这张表里,对某个字段查询,通常需要建立这个字段的索引,以加快查询的效率,根据各个字段数据类型的不同,所采用的索引方式也不一样。比如,对Int类型的字段建索引,最简单的方式是建立一个二分查找树索引;对Geometry字段,建立空间索引(R树、四叉树、网格等)。
“聚簇”这个词大家都很熟悉,在数据库原理和文件系统中经常见到,也就是记录按某个字段索引物理排序,主要的目的就是为了按这个字段检索时,在物理层面保证高的读取效率,“聚簇”使得索引顺序靠得近的记录,物理存储的时候也靠近存储,这样,范围查找时,用更少的I/O就能连续地读取到所需的记录,所以,记录的排列顺序往往显得非常重要,但一张表只能按一个字段索引进行物理排序。图形数据往往涉及到的空间范围查询,地图显示的时候,就是显示一块空间上靠得很近的图元,需要对Geometry字段进行“聚簇”,问题是“二维空间的聚簇,无法作到百分百的聚簇,不同于一维索引”,目前,可以采用Hilbert填充曲线的排列顺序来近似地对二维图形进行聚簇,以提高空间数据物理读取的性能。
图形数据读取流程与属性数据类似,如图:
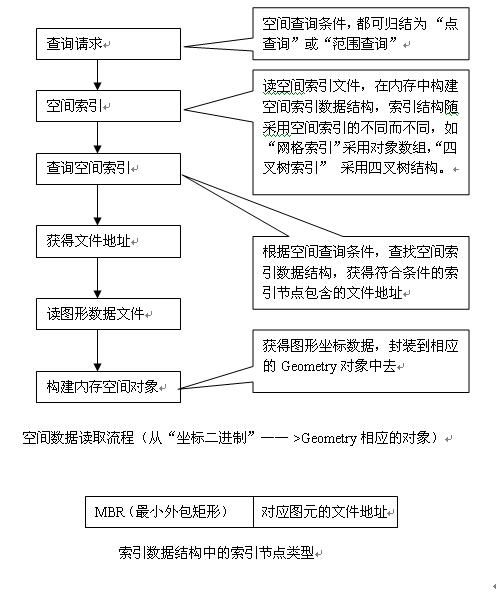
在空间数据量较小、硬件内存比较大的情况下,可以把空间数据全部装载进内存;如果空间数据量比较大,或内存较小的时候,应采用“按需读取,适当缓存”的策略,即当前不需要的空间数据,不读进内存,只读当前需要的,同时,采用对象缓存池策略,建立对象缓存池数据结构,该数据结构与空间索引数据结构相同,即不立即淘汰暂时不用的数据,先放到缓存池中,如果下次再需要,就不需要再读文件,直接从缓存池中取,提高了效率,设定缓存池上限,当缓存池超过上限的时候,采用空间距离淘汰策略进行对象淘汰,即把离当前窗口最远的对象给释放掉(这是基于“距离当前窗口远的图元被再次访问的概率较低”这个假设)。
空间数据读入内存之后,在内存中形成各种空间对象,下一步如何对空间对象进行图形渲染?

空间查询、空间分析大多是基于图形运算来实现的,首先需要通过索引快速获取到需要参与运算的图形或构建拓扑数据,然后通过一定算法实现空间查询和分析,比如,多边形叠置分析,就是通过多边形之间求交、并、补实现的,并把相应的属性信息进行融合;路径规划,是建立在节点与弧度拓扑关系的基础上,对“图”进行搜索的过程。

