

软工实践寒假作业(2/2)
项目地址:https://github.com/Fzucaoxin/PersonalProject-Java.git
代码规范:https://github.com/Fzucaoxin/PersonalProject-Java/blob/main/221801112/example/codestyle.md
一、作业描述
| 作业课程 | 2021春软件工程实践|S班 (福州大学) |
|---|---|
| 作业要求 | 软工实践寒假作业(2/2) |
| 作业目标 | 阅读《构建之法》并进行思考。完成词频统计的开发, 测试。利用git管理项目。 |
| 其他参考文献 | 廖雪峰的git教程、源代码管理 、.gitignore配置语法完全版等 |
二、目录
三、任务一
3.1.《构建之法》思考与提问
-
.我阅读了 12章 用户体验的关于短期刺激和长期影响的内容:“在实验室里;大家心里想着,我要品尝饮料啦!漱口之后,品尝几口或一听饮料。反馈是:新产品甜味较大,口感很好,我喜欢!
在家里:美国消费者一次买一箱(24听),随意坐在沙发里,一边看电视一边喝。反馈是:新产品甜味较大,喝多了太腻味,喝不下去,再也不买了!”。思考:例如一个游戏(如农药,吃鸡等),当人们热衷于它时,能够获得短期的快感,游戏公司开发了防沉迷,是为了减低长期的负面影响。但对于某个不知名的游戏,不言而喻其短期刺激显然更为重要。所以我的疑惑是:短期刺激和长期影响是一个软件不同时期应该考虑的事,还是一开始就应该一起考虑?
-
我阅读了 8章 需求分析 关于获取和引导需求:“需求不仅来自外界,还可以来自软件企业本身。一个免费的互联网服务到达>.定规模后,企业就会考虑如何让这个服务带来收入。例如一个免费的互联网电子邮件服务会考虑对用户收费,支持几种不同等级的用户,在邮件中附带广告,或者在页面显示广告,等等。”
思考:现在一些小程序如嵌入至qq中的小程序,大多没有一定用户数量和规模,但程序内部依然包含大量的广告,这不是本末倒置了吗?用户需求都没有先得到满足,但是存在即合理。这些软件程序依靠什么在市场上能够继续生存?
-
我阅读了 8章需求分析(p158) 关于提高估计能力的招数:"实际花费取决于两个因素--多某件事的估计时间X,以及他做过类似开发工作的次数N:Y=X +/- X/N。当N等于1时,一项工作的估计的实际花费范围是[0,,2X]"。
思考:实际开发工作中时间不可能为0,此处去左边取闭区间,是否不妥?还是我没有理解其真正含义?
-
当出现不容易复现但又存在的bug时如何解决?我阅读了在阅读第一章第9页:“
不可见性( Invisibility )
软件工程师能直接看见源代码,但是源代码不是软件本身。软件以机器码的形式高速运行,还可能在几个CPU核上同时运行,工程师是“看”不到自己的源代码如何具体地在用户的机器上被执行的。商用软件出现了错误,工程师可以看到程序在出错的一瞬间留下的一些痕迹(错误代号、大致的目标代码位置、错误信息),但是几乎无法完整重现到底程序出现了什么问题。当工程师回过头来看源代码时,它们还是安静地排列在屏幕上。“
思考:回想起曾经的debug方法,输出查看日志,输出函数调用栈等。又通过网络查询到,例如bug间歇性随机出现时,可分析:
1:随机性数值导致。
2:特定的执行过程导致的特殊情况。
3:野指针导致的不稳定性问题。
想请问实际工作中出现这种不可见性时,如何解决?
-
如何判断”过早优化“?判断一个优化是否为当前必要的?我阅读了第三章53页,原文:”过早优化:既然软件 是“软”的,那它就有很大的可塑性,可以不断改进。放眼望去,一个复杂的软件似乎很多模块都可以变得更好。一个工程师在写程序的时候,经常容易在某一个局 部问题上陷进去,花大量时间对其进行优化;无视这个模块对全局的重要性,甚至还不知道这个“全局”是怎么样的。这个毛病早就被归纳 为“过早的优化是一切罪恶的根源”。
思考:编写程序时遇见这样的情况,事先不容易判断是否需要优化,如果当前不进行优化,最后发现程序 进 行这样的优化是必须的,而又不得不修改大量代码。这种情况如何判断“过早优化”?
3.2有趣故事:
自由软件之父的Richard Matthew Stallman(简称 RMS),留着一头卷发和满满的胡子,演讲后的问答坐在台上脱下袜子,赤脚自在的回答提问。资工系的学生问他,目前业界都使用非自由软件,自由软件也没有商业模式,想生存下去该怎么办?Stallman回答,「你可以转行」。
跟Stallman接触过的人多少会感受到他的固执脾气,约访的时候,Stallman要求记者看完他列出的10个连结,并且要编辑及记者保证不犯两个错误。
第一,绝对不会把自由软件和开放源码(Open Source)两个概念混为一谈,以及要用「GNU/Linux」称呼操作系统,而非Linux。
专访的时候,Stallman一边卷着头发,一边徐徐回答记者的提问,他的思路清晰,回答直接、锐利,但他的态度平和,甚至担心记者跳题之后会忘了回来问问题。
问他网络科技产业的未来?
他耸耸肩说,「我不知道未来会怎样,我只想现在!我为自由而奋斗,而是否能够成功,取决于大家是否加入战斗。我所能做的就是鼓励人们聚焦在『自由』,而不是社会所鼓励人们选择的其他次要价值。」
启示:当一个人有了目标和追求时,并且向着这个目标不断前进时,这个人就会变得越来越强大,做人处事有自己的原则,而这些又反过来促进一个人的前进。RMS有对自由软件的追求,这些使得他获得成功,我们做一件事时也应该有自己的目标,这样才能把一件事完成的更好。
四、任务二:
4.1 项目地址:
项目地址:https://github.com/Fzucaoxin/PersonalProject-Java.git
4.2 PSP表格:
| PSP2.1 | 个人开发流程 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 410 | 840 |
| • Estimate | • 估计这个任务需要多少时间 | 410 | 840 |
| Development | 开发 | 350 | 720 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 20 | 40 |
| • Design Review | • 设计复审 | 20 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 20 | 40 |
| • Design | • 具体设计 | 70 | 140 |
| • Coding | • 具体编码 | 80 | 160 |
| • Code Review | • 代码复审 | 20 | 40 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 140 |
| Reporting | 报告 | 60 | 120 |
| • Test Repor | • 测试报告 | 20 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 40 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 20 | 40 |
| 合计 | 410 | 84 |
4.3 解题思路描述
需求是对文件内容进行统计,需要文件和流相关知识,起初通过简单的字节流读取文本,发现效率太低,又学习了缓冲流,提升了效率。在这过程中,又学习到了Java的NIO 读取文件内容方式,但在本项目实际效果并不如缓冲流,可能是使用的场景不适合吧,有待继续学习。
其次需要对字符串继续分析。统计单词频数,存在key和value的关系,此处可以使用map这个数据结构,对于字符串,起初使用。对于统计非空白字符的行,使用readline进行判断。起初,没有学习到JAVA Pattern和MAtcher结合正则表达式,处理字符串的高效,使用了太多分支,造成测试数据到达一定量(自己测试了字符数量:5*10^7),耗时格外的长。
4.4 代码规范制定链接
代码规范:https://github.com/Fzucaoxin/PersonalProject-Java/blob/main/221801112/example/codestyle.md
4.5计算模块接口的设计与实现过程
4.5.1 流程图
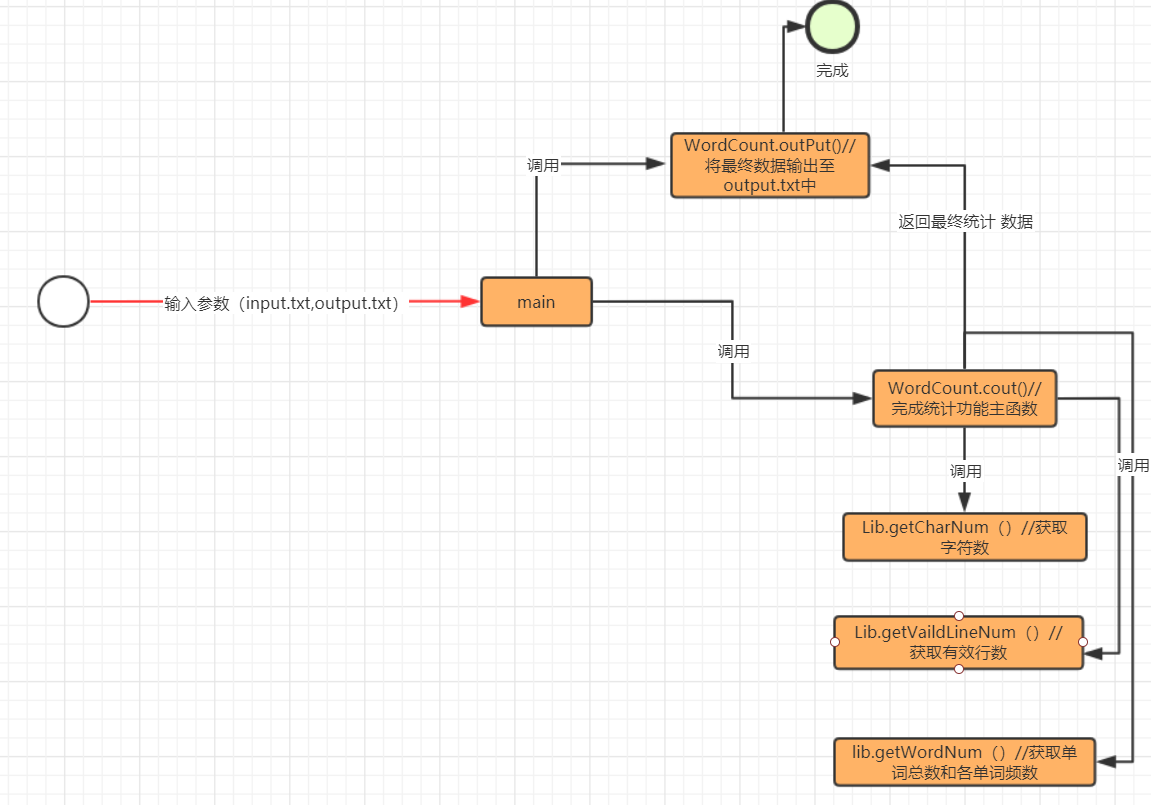
4.5.2 关键代码
- 统计字符数(Lib.getCharNum()):ASCII码与UTF-8编码,一个英文字母(不分大小写)占一个字节的空间(详情)。由于只对英文字符进行统计,故使用如下获得字节数(当前情况下即字符数):
"characters: " + String.valueOf(file.length()) + "\n";
2.统计有效行数:一开始想使用
lineNumberReader.skip(fileLength);
int lines = lineNumberReader.getLineNumber();
但是这样却不能去除空白行。最后只能一行行判断:
FileReader fr = new FileReader(file);
//利用缓冲区提升读取性能
BufferedReader br = new BufferedReader(fr);
LineNumberReader lnr = new LineNumberReader(br);
String str;
while ((str = lnr.readLine()) != null)
{
//统计包含非空白字符的行
if (!(isBlankString(str)){
lineNum++;
}
-
单词总数与单词频数(根据数量和字典序排序)统计
存在key和value的关系,故使用map。忽略key的大小写敏感,可以使用TreeMap,构造函数传入String.CASE_INSENSITIVE_ORDER比较器。但是TreeMap效率没有hashMap 高,故综合考虑使用hashMap。此外利用Pattern,Matcher通过正则表达式,对字符串进行判断处理:
String[] strs = s.split("[^a-zA-Z0-9]"); Pattern pattern = Pattern.compile("^[a-z]{4}[a-z0-9]*"); for (String str : strs) { str = str.toLowerCase(); matcher = pattern.matcher(str); if (!str.isEmpty()&&matcher.find()) { cnt++; Integer t = map.get(str); if (t == null) t = 0; map.put(str,1+t); } }对map的排序这是先将其转为list,利用Collection.sort()进行排序
//将hashMap转化为list List<Map.Entry<String,Integer>> list = new ArrayList<>(map.entrySet()); //进行排序 Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if (o1.getValue() == o2.getValue()) { return o1.getKey().compareTo(o2.getKey()); } return o2.getValue().compareTo(o1.getValue()); } });最后再利用循环,对map 中的值进行统计即可得到答案。
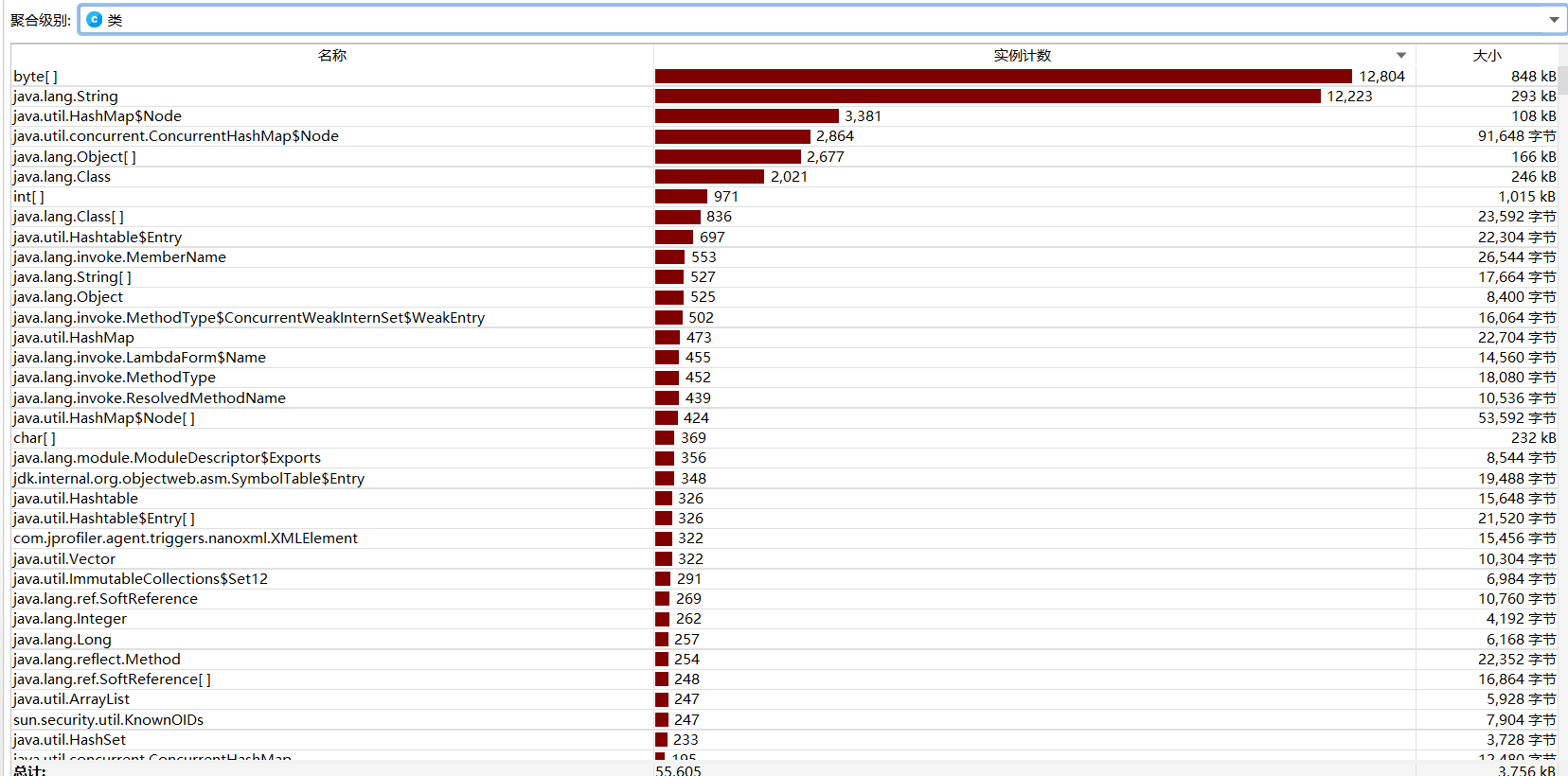
4.6 计算模块接口部分的性能改进。
改进程序前的所有对象的实时内存:
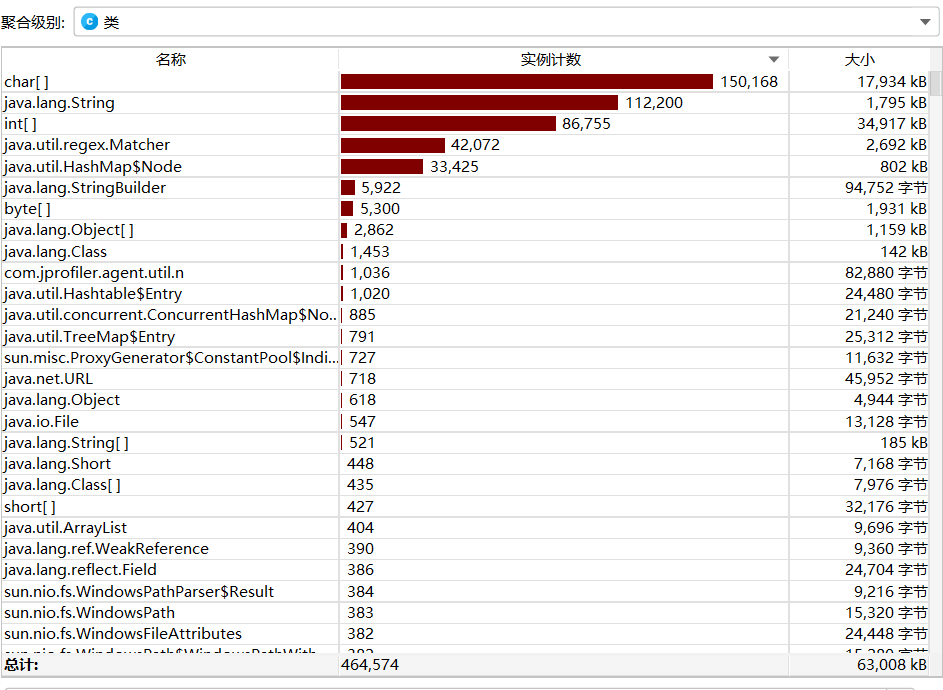
改进后所有对象的实时内存:
改进前耗时:
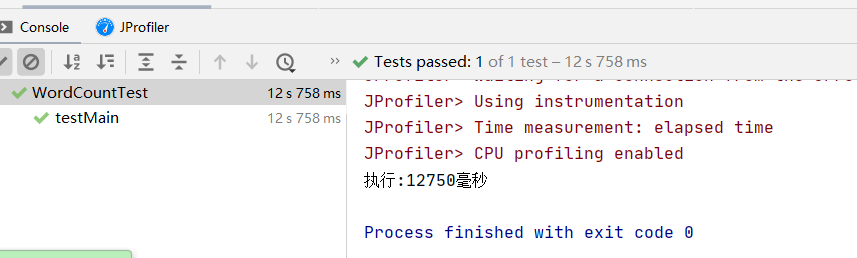
改进后耗时:
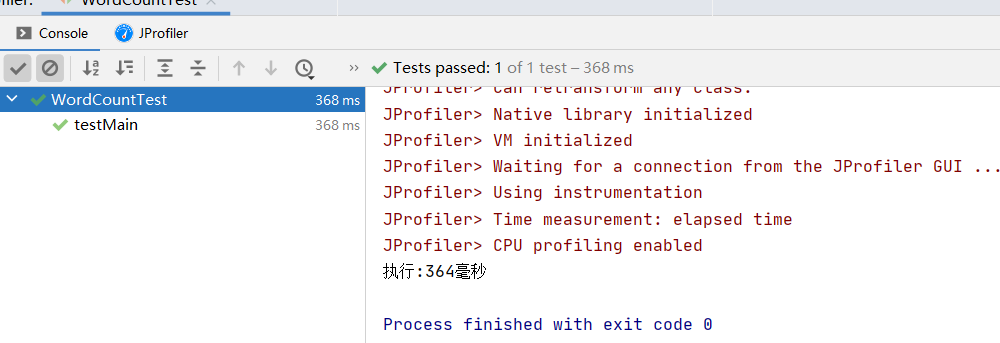
由以上对比知改进后消耗了更多的内存空间,但是执行时间得到了大幅缩短。
改进思路:
1.利用BufferReader读取文件,增加读取速度。
2.利用正则表达式(java Pattern和MAtcher),取代原来多个if else 分支对字符串的判断与处理。
3.用StringBuilder代替String,加快字符串拼接的速度。
4.7 计算模块部分单元测试展示。
4.7.1 单元测试代码
循环调用进行11次测试(10份测试数据,一份测试找不到文件异常)。
for (int i=0;i<11;i++)
if (i==0)
testCount("testData/answer.txt","testData/output.txt","testData/input.txt");
else
testCount("testData/answer"+i+".txt","testData/output"+i+".txt","testData/input"+i +".txt");
将程序得到的结果与期望结果answeri.txt的进行一行行比对,给出结果不一样的行:
for (int i=0;(str2=buf2.readLine())!=null;i++)
{
//读取的内容
str1=buf1.readLine();
Assert.assertEquals("第"+(i+1)+"行没有获得预期的结果",str1,str2);
}
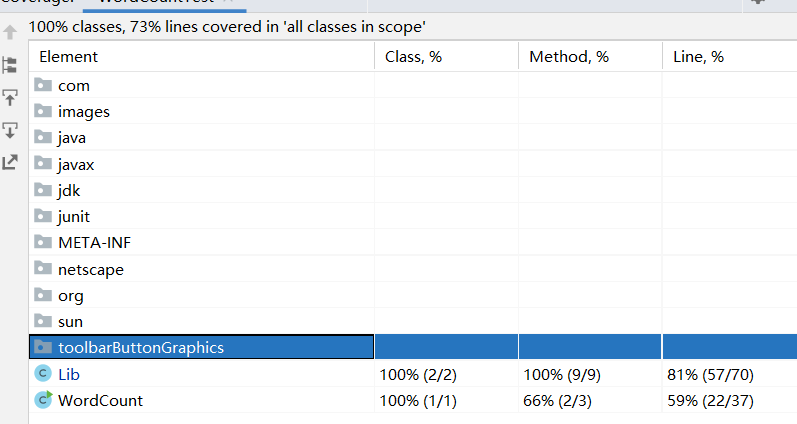
4.7.2 测试覆盖率截图
4.7.3 构造测试数据的思路
1.检验单词输出顺序:
windows95,windows98 windows2000 windows20002.
2.区别file123 和123file以及aaa是否为单词。
3.插入空白行。
4.单词分隔符不仅仅加入空格,还有其他如;,:等字符。
5.使用程序产生10^7量级的数据进行测试。
4.8 计算模块部分异常处理说明。
-
FileNotFoundException异常,不存在该或找不到文件。
单元测试样例:如4.4.1。 -
IOException 异常。可能出现与权限不够或者读取文件时,文件被删除等。
4.9 心路历程与收获
-
git 学习:在git学习的过程中,了解到git的源于Linus与版本控制系统BitKeeper东家BitMover公司的一段往事,Linus随即花费两周时间写了一个分布式管理系统--git。历史是我们未来发展的参照物,我们不一定要成为像Linus这样的人物,但是我们可以以此勉励自己。在本次项目版本的多次commit 过程中,一开始以为只需要add,commit,push,然后意外发生了,我发现中间某一次commit不符合要求,于是我又去学习相关git知识,终于解决了问题,或许学习就是这样反反复复的过程。
-
作业完成:在对作业分析的过程中,一开始感觉要求很多不知道如何下手,后面多次阅读了作业要求,选择一部分一部分的完成作业的要求,在对照其他自己忽略的要求,完善作业。在项目的编写过程中,一开始觉得项目需求不是很难,后面逐渐发现有很多重要的东西自己平时编写程序时没有注意的,自己也花费很多时间完善这方面的知识和进行实际,如:编程规范(自定义注释等),自动化测试(编写程序生成测试数据,单元测试等),性能测试(通过分析内存占用,函数调用树等优化代码)。
-
其他:自己在完成项目后,发现估计的时间和花费的时间差距明显。后面又再次阅读《构建之法》工作量估计的内容,公式法,扑克牌法等。以后需要更多的将这些方法运用于实践,来增加自身的估计能力。

