
最近某项目用到了总结一下实现思路,算是独立自主设计的一个比较有难度的模块。这里简要介绍一下思路。
一、背景与需求
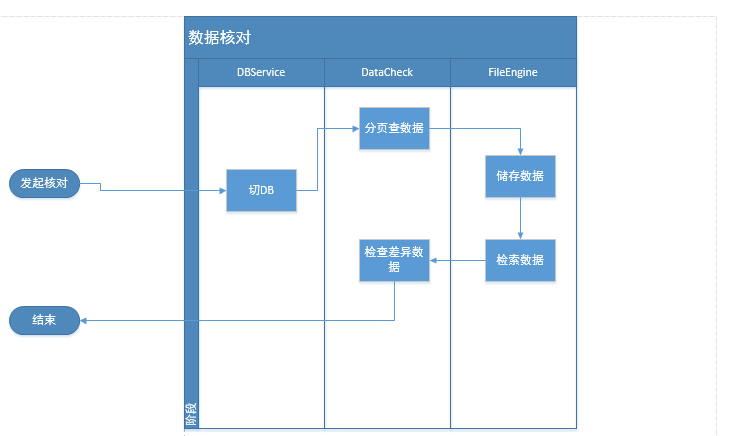
对比出不同数据库中相同表的数据差异。这里相同表指表的数据结构是一致的。比如A服务下面数据库DB_A中有表格tableA,B服务下面数据库DB_B中有表格tableB。现在有这样一个场景找出tableA与tableB的数据差异。
二、分析整个需求涉及到的技术点
1,因为涉及到对不同的数据库操作,需要动态切DB支持。
2,因为数据量比较庞大所以需要动态mapper分页的支持。
3,考虑到对内存的消耗以及及时释放DB连接,采用文件缓存数据,需要熟悉了解nio相关知识点。
比如tableA有10万条数据,我们如何找出这10万条数据与tableB中的差距呢?直接将两张表的数据全部查出来进行对比显然不靠谱,因为数据量过于庞大可能直接导致OOM。可能我们会考虑到分页查tableA表,再将A表的每条数据到B表中做查询,然后逐条比对。看起来除了相当耗时外感觉是可取的。但是这有一个致命的问题,为了tableA以及tableB是静态数据,同时不能影响其他业务使用也就不能锁表,我们需要对两个事务开启RR隔离级别事务控制,我们知道长事务一个致命的问题在于对数据库性能的影响,因为他在读的时候其他的修改要有正确的回滚日志(还好我们这里只是读,如果自己本身有修改,自己的修改还要产生回滚日志),所以我们需要让数据库尽快释放连接。所以采用文件缓存数据库数据似乎是一个不错的选择,并且基于文件对数据的操作也很灵活,可发挥的空间也更加大。
三、技术设计
由上面的分析我们知道,整个技术设计的核心必定是围绕着数据的文件存储与文件检索。
- 方案一:随机存储 + 随机检索
虽然随机读写从磁盘读写来看要慢于顺序读写。但是对于大文件而言,随机读写对内存消耗更低。一般对大文件的操作也是通过随机读写实现。
实现思路:
在从表tableA查数据的时候,我们将A的每条行数据生成一个数字摘要,比如digest = md5(row),在对数字摘要进行散列pos=hsh(diget),只要我们事先计算一下tableA中的数据量,然后进行hsh范围限定,如果散列算法足够优异,可以认为所有tableA的数据均匀分布在其对应文件中,但hsh冲突无法避免,肯定会浪费文件内存,可以预见其对应文件必定会膨胀,导致不必要的内存消耗。一旦table写的方式确定了tableB完全按照tableA中的方式生成响应的写行数据的pos,那么我们只需要将tableA对应文件的数据按块读出,然后解析出相关数据去tableB文件中查找即可(同样的方式生成pos)。
- 方案二:索引文件 + 数据文件
此方案受启发于数据库搜索引擎。先比对索引,然后通过索引去数据文件找出对应文件。这样写数据采用顺序流,读取数据文件采用随机读。
实现思路:
首先约定所有表中必须要有主键。索引 = 主键 + 行数据的数字摘要+数据文件offset。索引需要满足定长,方便后续对索引文件的操作,块内存加载批量解析。由于是定长,我们假设主键8字节+ 16字节数据摘要+ 8字节offset = 一个索引占用内存32字节,1千行数据占用内存约3.2KB。两个文件也才6.4KB,这意味着同时对比1000条数据会吃内存6.4KB,这个是我们能接受的范围。接下来在查出一条数据后,我们需要的操作是先为其生成索引,然后写入索引文件,数据写入数据文件。文件写好后,接下来就是比对索引文件索引存在区别的索引,然后通过索引去对应数据文件找出数据即可。
- 方案确定
从吞吐量以及性能来看:方案一因为读写都是随机模式,完全依赖于散列算法,所以文件检索性能上优于方案二。方案二因为采用的数据索引的方式所以内存可控,吞吐量可控,可由不同的机器动态配置。
从磁盘占用来看:方案一因为散列算法自身的原因可能导致文件膨胀,可能造成不必要的磁盘消耗。方案二可以保证磁盘文件大小与数据表数据大小完全对等。
从实现难度来看:方案一难度大于方案二,方案一难点体现在散列算法的设计以及文件的块检索上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号