
Spark是一种基于内存的快捷、通用、可扩展的大数据分析引擎
1. Spark模块
Spark Core: Spark核心模块,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等
Spark SQL:用于处理结构化数据的一个模块,提供了2个编程抽象:DataFrame DataSet,并且作为分布式SQL查询引擎的作用。他将Hive SQL转化为MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序复杂性
Spark Streaming:提供对实时数据进行流式计算的组件,提供了用来操作数据流的API
MLlib:提供常见机器学习功能的程序库。包括分类、回归、聚类、协同过滤等
Graphx:用于图计算的API,能在海量数据上自如运行复杂图算法
2. Spark与MapReduce区别
①spark把运算的中间数据(shuffle阶段产生的数据)放在内存,减少磁盘交互,迭代计算效率高;mapreduce的中间结果需要落地,保存到磁盘
②spark容错性高,Spark通过弹性分布式数据集RDD来实现高效容错,某一部分丢失或者出错可以通过整个数据集计算流程的血缘关系来重新构建,但Mapreduce只能重新计算
③计算模型不同,mapreduce框架的hadoop分为map 和reduce两个阶段,两阶段完成了就结束,所以一个job能做的处理有限;而Spark计算模型是基于内存的迭代式计算模型,可以分为n个阶段,根据用户编写的RDD算子和程序,在处理完一个阶段后继续往下处理很多阶段,所以Spark较mapreduce计算模型更加灵活,可以提供更强大功能
Spark就是为了解决mapreduce数据保存到磁盘导致效率地下而产生的,spark原理还是mapreduce,只是shuffle放在内存中计算,所以效率很高
2.1 Spark与Mapreduce的shuffle区别
shuffle本质:就是将Map端获取的数据使用分区机制进行划分,并将数据发送给对应的reducer的过程
相同点:都是将mapper(Spark里是ShuffleMapTask)的输出进行partition,不同的partition送到不同的reducer
不同点:Mapreduce默认是排序,Spark默认不排序
2.2 Spark效率比MapReduce高
①Spark基于内存计算,减少低效的磁盘交互
②高效的调度算法,基于DAG
③容错机制Linage
3 RDD
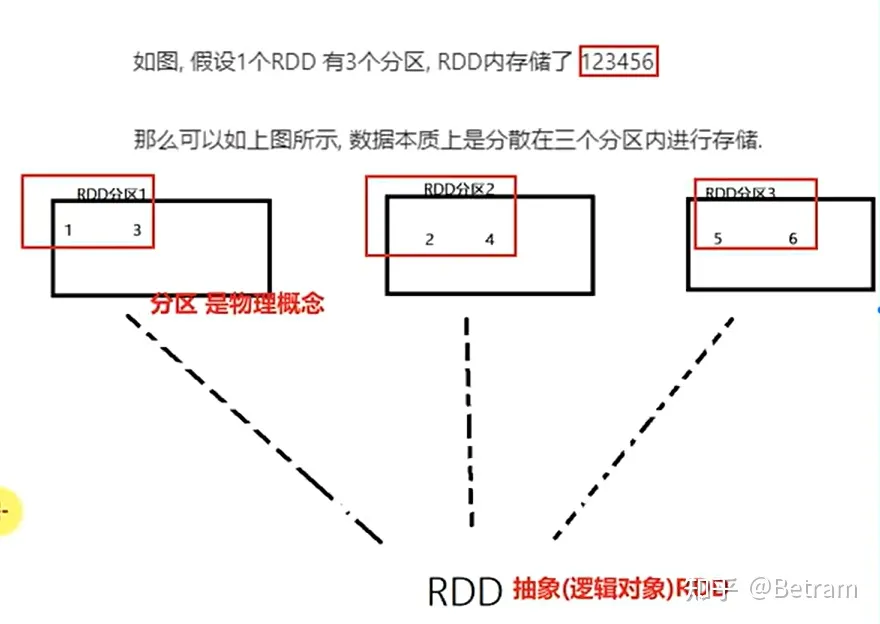
RDD是弹性分布数据集,是spark基本数据结构。它是一个不可变、分区、里边元素并行计算的集合
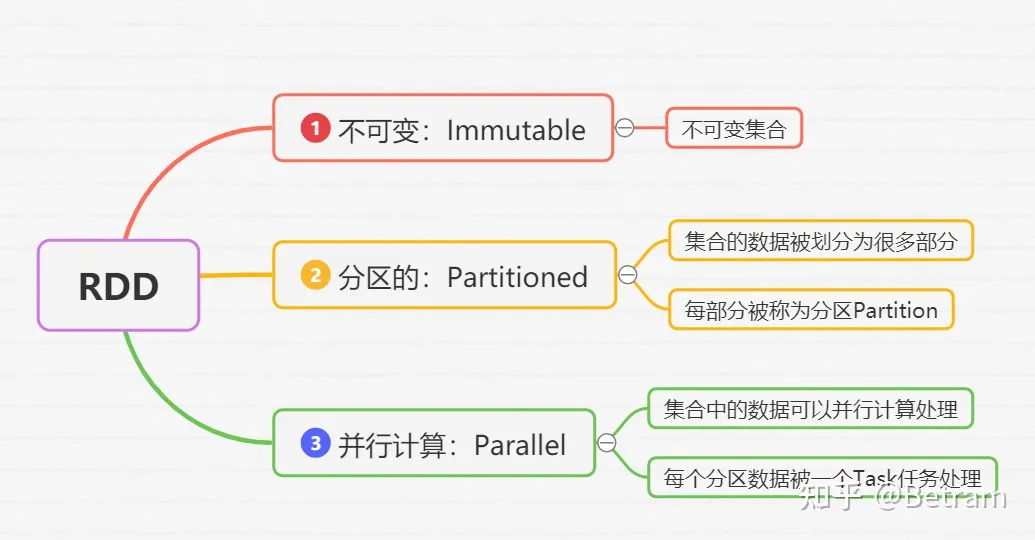
3.1 RDD五大属性
①RDD是有分区的,分区时RDD数据存储的最小单位,一份RDD数据本质上分割成多个分区
②计算方法作用到每个分区上
③RDD之间时有相互依赖关系的(血缘关系)
④KV型RDD可以有分区器,默认分区器:hash分区规则
⑤RDD分区规划会尽量靠近数据所在服务器
4. DAG
DAG指的是数据转换执行的过程,有方向无闭环
4.1 DAG为什么要划分Stage
为了并行计算。将一个DAG划分为多个Stage,同一个Stage中有多个算子操作,可以形成一个pipline流水线,流水线内的多个平行的分区可以并行执行
4.2 DAG的Stage如何划分
DAG叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系不同将DAG划分成不同的stage。
对于“窄依赖",partition的转换处理在stage中完成计算,不划分。
对于“宽依赖”,由于shuffle的存在,只能在父RDD处理完成后,才能开始接下来的计算,也就是说需要划分stage。且"宽依赖"是划分stage的依据。
5.算子类
5.1 Transformation算子
transformation算子:用来将rdd进行转化,构建rdd血缘关系
(1) map:对RDD中所有元素施加一个函数映射,返回一个新RDD,该RDD有原RDD中的每个元素经过function转换后组成。 特点:输入一条,输出一条;
(2) filter:过滤符合条件的记录数,true保留,false过滤掉;
(3) flatmap:通过传入函数进行映射,对每一个元素进行处理。先map,后flat,与map相似,每个输入项可映射0到多个输出项;
(4) repartition:增加或减少分区,会产生shuffle (多分区到一个分区不会产生shuffle);
(5) MapPartitions:每次处理一个分区的数据,这个分区的数据处理完后,原RDD中分区数据才能释放,但是数据量大时会导致oom;
(6) MapPartitionsWithIndex:与MapPartition相似,除此之外还会带分区索引值;
(7) foreache:循环遍历数据集中每个元素,并运行相应的逻辑;
(8) sample:随机抽样算子,对传进去的数按比例放回或不放回的抽样;
(9) GroupByKey:对数据会按照key进行分组,key相同会在同一个分区里;
(10) ReduceByKey:将相同的key,将按照相应的逻辑进行处理。先进行本地聚合(分区聚合),在进行全局聚合;
(11) sortbykey:如果源RDD包含源类型(k,v)对,其中k可排序,则返回新RDD包含(k,v)对,并按照k排序;
(12) union:返回源数据集合参数数据的并集;
(13) distinct:返回对源数据集对元素去重后的新数据集;
还有intersection、aggregateBykey、join、cogroup、cartesian、pipe、coalesce、repartition、Repartition and SortWithPartition等算子。
5.2 Action算子
action算子会触发Spark提交作业(job),将数据输出spark系统
action算子会触发Spark提交作业(job),并将数据输出spark系统。
(1) reduce: 根据聚合逻辑聚合数据集中每个元素;
(2) take(n): 返回一个数据集包含前n个元素的集合;
(3) first: first=take(1)意思是返回数据集中的第1个元素;
(4) count: 返回数据集中元素的个数。会在结果计算完成后回收到Driver端;
(5) collect:将计算结果回收到Driver端;
(6) foreach: 循环遍历数据中每个元素,运行相应的逻辑;
(7) foreachPartition:遍历每个partition里边的数据;
还有takeSample、saveAsTextfile、takeOrdered、Save As SequenceFile、SaveAsObjectFile、countByKey等算子。
参考文献
https://blog.csdn.net/index_test/article/details/126709956
https://blog.csdn.net/qq_43496675/article/details/120172616

 浙公网安备 33010602011771号
浙公网安备 33010602011771号