
1.Kafka 配置参数含义
①配置文件配置方式
spring:
kafka:
bootstrapServers: kafkaserver:port
schemaRegistry: kafkaSchemaRegisterWebSite
autoOffsetReset: earliest
security.protocol: SSL
topic: kafkatopic
groupId: groupId
listener:
type: batch
properties:
# Broker connection parameters
security.protocol: SSL
#Schema Registry Connection parameter
schema.registry.url: kafkaSchemaRegisterWebSite
specific.avro.reader: true
consumer:
security.protocol: SSL
auto-offset-reset: earliest
#key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
key-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer2
#value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
value-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer2
properties:
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializer
spring.deserializer.value.delegate.class: io.confluent.kafka.serializers.KafkaAvroDeserializer
②java类配置方式
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBootstrapServers);
config.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put("security.protocol", "SSL");
config.put("compression.type", "snappy");
config.put("acks", "all");
config.put("retries", 0);
config.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
①配置文件配置方式
spring:
kafka:
bootstrapServers: kafkaserver:port
schemaRegistry: kafkaSchemaRegisterWebSite
autoOffsetReset: earliest
security.protocol: SSL
topic: kafkatopic
groupId: groupId
listener:
type: batch
properties:
# Broker connection parameters
security.protocol: SSL
#Schema Registry Connection parameter
schema.registry.url: kafkaSchemaRegisterWebSite
specific.avro.reader: true
consumer:
security.protocol: SSL
auto-offset-reset: earliest
#key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
key-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer2
#value-deserializer: io.confluent.kafka.serializers.KafkaAvroDeserializer
value-deserializer: org.springframework.kafka.support.serializer.ErrorHandlingDeserializer2
properties:
spring.deserializer.key.delegate.class: org.apache.kafka.common.serialization.StringDeserializer
spring.deserializer.value.delegate.class: io.confluent.kafka.serializers.KafkaAvroDeserializer
②java类配置方式
consumer
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBootstrapServers);
config.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put("security.protocol", "SSL");
config.put("compression.type", "snappy");
config.put("acks", "all");
config.put("retries", 0);
config.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
producer
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServersMap.get(env));
props.put("schema.registry.url",schemaRegistryMap.get(env));
props.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
props.put("security.protocol", "SSL");
props.put("max.request.size", "10000000");
props.put("compression.type", "snappy");
props.put("acks", "all");
props.put("retries", 0);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName());
1.1bootstrapServer: 指定broker的地址清单
1.2(反)序列化器
key-deserializer/value-deserializer: kafka producer将java对象通过key-serializer/value-serializer转为字节格式发送到broker中,kafka consumer将字节通过key-deserializer/value-deserializer转为java对象。另外由于kafka消息是由key和value组成,所有有key-(de)serializer/value-(de)serializer
Key-deserializer(key反序列化器) :key为基本数据类型org.apache.kafka.common.serialization.StringDeserializer,ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型也都实现了。
value-deserializer(value反序列化器):value为基本数据类型org.apache.kafka.common.serialization.StringDeserializer,ByteArray、ByteBuffer、Bytes、Double、Integer、Long这几种类型也都实现了.value为特定schema类型:io.confluent.kafka.serializers.KafkaAvroDeserializer
(反)序列化框架:Avro, Thrift, Protobuf...
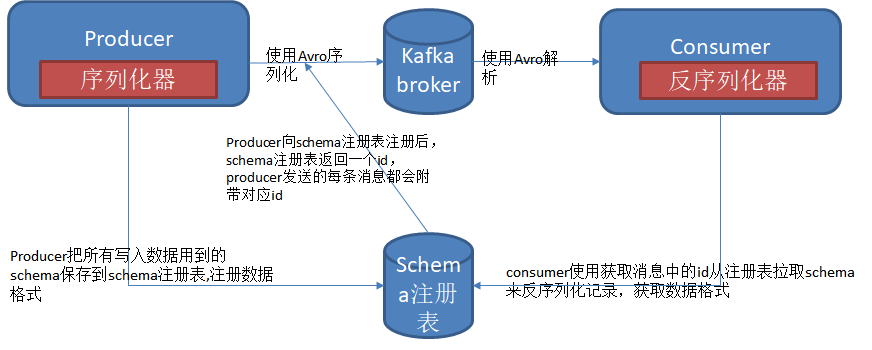
Avro序列化框架:producre发送消息时序列化消息中包含整个schema,consumer读取消息时需要找到schema,目前通用的设计模式是使用schema注册表达到这个目的,schema注册表是一个开源项目:https://github.com/confluentinc/schema-registry#quickstart-api-usage-examples
schemaRegister: 当kafka producer发送特定schema类型数据,consumer接收特定schema数据时,schemaRegister变的很重要。为了让Kafka支持Avro序列化,schemaRegister以topic为单位用来管理Avro schema。比如上边配置文件中 schema.registry.url: https://abc.net:9081/那么可以通过 curl -ks -XGET https://abc.net:9081/subject/kafkatopic-value/versions/查看对应这个topic已经注册的version有哪些,如果像删除version为1的,则可以用curl -ks -X DELETE https://abc.net:9081/subject/kafkatopic-value/version/1
序列化器用来处理schema的注册,发序列化器用来处理schema的拉取。如果序列化注册的schema和发序列化器拉取的schema不兼容,则会抛出异常,需要额外处理
schema.registry.url指向schema注册表的位置
1.3 autoOffsetReset(consumer)消费偏移量
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
1.4 max.request.size(producer)
能发送单个消息的最大值
1.5 ack (producer)
ack指定必须有多少个分区副本收到消息生产者才认为写入是成功的
ack=0:producer不会等待任何服务器的相应,会丢数据但吞吐量高
ack=1:主节点收到消息则producer会收到来自服务器成功的响应
ack=all:所有参与复制的节点全部收到消息时,producer才会收到一个来自服务器成功响应
demo:
private Properties getProducerConfigProperties() { Properties props = new Properties(); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaStreamsConfig.getBootstrapServers()); props.put("schema.registry.url", kafkaStreamsConfig.getSchemaRegistry()); props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer"); props.put("security.protocol", "SSL"); props.put("max.request.size", "10000000"); props.put("compression.type", "snappy"); props.put("acks", "1"); props.put("retries", 0); props.put("batch.size", 2048000); props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, KafkaAvroSerializer.class.getName()); log.info("props is {}", props.toString()); return props; } private void produce( Producer<String, SpecificRecordBase> producer, String topic, SpecificRecordBase recordBase) { ProducerRecord consumeRecord = new ProducerRecord<>(topic, Long.toString(System.currentTimeMillis()), recordBase); ProduceCallback callback = new ProduceCallback(); try { producer.send(consumeRecord, callback); } catch (Exception e) { log.error("kafka producer send message:{}, get error: {}", recordBase, e); } } private class ProduceCallback implements Callback { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e != null) { log.info("Error while producing message to topic : {}", recordMetadata); } else { String message = String.format( "Sent message to topic:%s partition:%s offset:%s", recordMetadata.topic(), recordMetadata.partition(), recordMetadata.offset()); log.info(message); } } }
1.6 compression.type (producer)开启压缩
开启压缩在发送传输中可以提高kafka消息吞吐量
(‘gzip’, ‘snappy’, ‘lz4’, ‘zstd’)
1.7 retries (producer)
生产者在收到服务器错误消息时重发消息的次数
1.8 fetch.min.bytes(consumer)
consumer从broker获取最小数据量,如果broker中可用数据量小于这个值他会等到足够的可用数据时才返回给consumer
1.9 fetch.max.wait.ms(Consumer)
consumer从broker获取消息时间间隔
2.0 enable.auto.commit(consumer)
指定consumer是否自动提交偏移量,默认ture
2.Kafka消费不同数据类型
创建不同containerFactory实现消费不同的kafka
创建消费String类型consumerListener


@KafkaListener(topics = "#{'${spring.kafka.topic}'}", groupId = "{'${spring.kafka.group-id}'}", containerFactory = "kafkaListenerContainerFactory", errorHandler = "validationErrorHandler")
public void stringBatchListener(ConsumerRecord<?, ?> data) {
log.info("-----string message consume start:offset:{},partition:{},value.size:{}-----", data.offset(), data.partition(), data.value().toString().length());
log.info(MEASUREMENT_MARKER, "{\"keyword\":\"KafkaString\",\"partition\":\"" + data.partition() + "\",\"offset\":\""+data.offset()+"\",\"size\":\""+data.value().toString().length()+"\"}");
if (null != data.value())
kafkaService.valueProcess(data.value().toString());
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
log.info("------ipvrawdata groupid:{}",groupId);
Map<String, Object> config = new HashMap<>();
config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBootstrapServers);
config.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
config.put("security.protocol", "SSL");
config.put("max.request.size", "10000000");
config.put("compression.type", "snappy");
config.put("acks", "all");
config.put("retries", 0);
config.put(ConsumerConfig.GROUP_ID_CONFIG,groupId);
config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
return new DefaultKafkaConsumerFactory<>(config);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory();
factory.setConsumerFactory(consumerFactory());
return factory;
}
创建消费特定schema类型consumerListener
@Bean public ConsumerFactory<String, DataTable> consumerFactory() { log.info("------ipvrawdata groupid:{}",groupId); Map<String, Object> config = new HashMap<>(); config.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBootstrapServers); config.put(ConsumerConfig.GROUP_ID_CONFIG, groupId); config.put(KafkaAvroDeserializerConfig.SCHEMA_REGISTRY_URL_CONFIG,"") config.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); config.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, KafkaAvroDeserializer.class); config.put("security.protocol", "SSL"); config.put("max.request.size", "10000000"); config.put("compression.type", "snappy"); config.put("acks", "all"); config.put("retries", 0); config.put(ConsumerConfig.GROUP_ID_CONFIG,groupId); config.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest"); return new DefaultKafkaConsumerFactory<>(config); } @Bean public ConcurrentKafkaListenerContainerFactory<String, DataTable> kafkaListenerContainerFactory() { ConcurrentKafkaListenerContainerFactory<String, DataTable> factory = new ConcurrentKafkaListenerContainerFactory(); factory.setConsumerFactory(consumerFactory()); return factory; }
3. kafka处理单条超大信息解决办法
3.1 kafka producer端压缩
使用 compression.type配置对发送消息进行压缩,压缩算法有sanppy gzip等
3.2 大消息数据切片
将发送消息切分多个部分,然后使用分区主键确保一个大消息的所有部分被发送到同一个kafka分区(这样每一部分的拆分顺序得以保留),如此在消费端消费这些消息时重新还原为原来的消息
3.3 不通过kafka发送这些大消息
可以使用https方式,共享文件(如sftp方式将大文件存到某个server路径下)等方式传达这些消息
3.4 kafka设置如下参数
broker配置
message.max.bytes (默认1000000)
broker能接收消息的最大字节数,这个值应该比消费端的fetch.message.max.bytes更小,比producer max.request.size更大才对,否则broker就会因为消费端无法使用这个消息而挂起
producer配置
max.request.size:生产者发送消息最大值,这个值小于等于broke端 message.max.bytes
consumer配置
fetch.message.max.bytes消费者能读取的最大消息,这个值要大于等于boker端message.max.bytes
4 kafka吞吐量为什么比RocketMQ高
| Kafka | RocketMQ | |
| 结构 |
Kafka在存储结构上采用分区机制(Partition),每个Topic可拆分为多个分区, 每个分区对应一个独立的日志文件,写入时按分区路由(如轮询、hash key、业务自定义分区键)决定写入哪个分区。 由于各分区独立,Kafka支持多线程并行写入 |
RocketMQ则采用全局单一CommitLog文件,所有Topic和Queue的消息统一串行写入, 通过内存队列映射逻辑队列位置,写入需加锁或通过GroupCommit批量控制,写入并发度远低于Kafka |
|
数据复制和一致性机制 |
使用了一个简化的复制机制,通过 "leader-follower" 模型来同步数据。 所有写入操作都先在 leader 上执行,然后异步复制到 follower。 |
使用类似的复制机制,但其更复杂的消息路由和存储机制可能增加了额外的开销 |
|
批量处理机制 |
生产者端:累积消息形成批次发送(默认16KB),降低网络请求次数45 消费者端:批量拉取消息(默认1MB),减少RPC调用开销 |
|
| 零拷贝(Zero-Copy)技术 |
|
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号