

一、kafa搭建:
1、下载kafka:wget http://archive.apache.org/dist/kafka/0.10.1.1/kafka_2.11-0.10.1.1.tgz
2、解压 tar -xvzf kafka_2.11-0.10.1.1.tgz
3、在/usr/kafa/kafka_2.11-0.10.1.1/config目录下配置“zookeeper.properties”,修改dataDir和clientPort、dataLogDir
新增:
dataDir=/usr/kafa/kafka_2.11-0.10.1.1/zk/data
dataLogDir=/usr/kafa/kafka_2.11-0.10.1.1/zk/logs
clientPort=2181
4、配置kafka_2.11-1.1.0/config下的“server.properties”,修改log.dirs和zookeeper.connect。前者是日志存放文件夹,后者是zookeeper连接地址(端口和clientPort保 持一致)。
修改:
port=9092 #端口号
host.name=192.168.0.11 #服务器IP地址,修改为自己的服务器IP
zookeeper.connect=192.168.80.4:2181
5、开启kafka自带zookeeper
kafka_2.11-0.10.1.1目录下:nohup bin/zookeeper-server-start.sh config/zookeeper.properties > zookeeper-run.log 2>&1 &
或者bin/zookeeper-server-start.sh config/zookeeper.properties
6、开启kafka:
kafka_2.11-0.10.1.1目录下:nohup bin/kafka-server-start.sh config/server.properties > kafka-run.log 2>&1 &
或者bin/kafka-server-start.sh config/server.properties
7、验证zookeeper和kafka启动成功:jps
显示:[root@localhost bin]# jps
7797 Kafka
7564 QuorumPeerMain //QuorumPeerMain是zookeeper的守护进程
7、创建topic:
kafka_2.11-0.10.1.1目录下:bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test //注意这里2181是config目录中zookeeper.properties配置clientPort端口,replication-factor是每个partition的副本个数 --partitions是对应topic下分区数量
返回结果:Created topic "test"
显示topic:
kafka_2.11-0.10.1.1目录下:bin/kafka-topics.sh -list -zookeeper localhost:2181
8、创建消费者
kafka_2.11-0.10.1.1目录目录下:bin/kafka-console-consumer.sh --bootstrap-server 192.168.80.4:9092 --topic test --from-beginning
消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据

9、创建kafka生产者bin/kafka-console-producer.sh --broker-list 192.168.80.4:9092 --topic test //9092和192.168.80.4对应config目录中server.properties中配置port和host.name=192.168.80.4
在执行完毕后会进入的编辑器页面进行输入,然后在消费者中显示

二、kafka基础知识
1、kafka结构

broker:消息由producer发往consumer的载体,是kafka集群中一台或多台服务器
message:消息,通讯的基本单位,每个producer向一个topic发布消息,kafka中message是以topic为基本单位的,不同topic之间是相互独立的,每个topic又可分为多个partition,每个partition存储一部分,partition中每条Message包含以下三条属性:
| offset | long |
| MessageSize | int32 |
| data | messages的具体内容 |
kafka对外使用topic概念,生产者往topic写消息,消费者从topic读消息。为了做到水平扩展一个topic实际由多个partition组成,通过增加partition数量来进行横向扩容。kafka会为partition选出一个leader,之后所有该partition请求实际操作都是leader,然后再同步到其他follower,当一个broker歇菜后,所有leader在该broker上的partition都会重新选举,选出一个leader
leader选取:partition%Num(broker)作为leader
消费偏移量保存:一个消费组消费partition,需要保存offset记录消费到哪,0.10之前offset保存在zk中,0.10之后offset保存在_consumeroffsets topic的topic中。写进消息的key由groupid、topic、partition组成,value是偏移量offset。每个key的offset都是缓存在内存中,查询时候不用遍历partition,如果没有缓存第一次会遍历partition建立缓存,然后查询返回。确定consumer group位移信息写入_consumers_offsets的那个partition计算公式:
__consumers_offsets partition =
Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
//groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。2、kafka多播消费

kafka同一个topic消息只能被同一个consumer group内其中一个consumer消费,而不能被所有消费者消费,故称为多播,但多个consumer group可同时消费这一消息。
对比rocketmq,同一个topic消息可以被同一个comsumer group内所有consumer消费(采用MessageModel.BROADCASTING方式)
对比rabbitmq,同一个queue内消息只能被一个消费实例消费;采用广播(fanout)方式exchange可以将消息广播到所有绑定的queue中。
kafka如果实现广播,只要每个consumer有一个独立的group即可;如果实现单播消费,只要所有consumer在同一个group里
3、kafka顺序消息
针对部分消息有序(message.key相同的message要保证消费顺序),可以在producer往kafka插入数据时控制,同一个key分发到同一个partition上,因为每个partition是固定分配给某个消费者线程进行消费的。所以对于同一个分区的消息来说是严格有序的;
消息producer在发送消息时,对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了,这时对于本身顺序为AB的消息顺序变成了BA。 为解决此问题,严格的消费需要支持参数:max.in.flight.requests.per.connection,该参数含义:在发送阻塞前对于每个连接,正在发送但是发送状态未知的最大消息数量。如果设置大于1,那么就有可能存在有发送失败的情况下,因为重试发送导致的消息乱序问题。所以我们应该将其设置为1,保证在后一条消息发送前,前一条的消息状态已经是可知的。
rocketmq支持顺序消费方式:message.key相同的message发往同一个queue上
rabbitmq支持顺序消费:exchange不采用广播方式,消息只发送到一条queue上
4、Kafka 分区partition
4.1、生产者发送消息到topic,消费者订阅topic,topic下是partition,消息时存储在partition中的,所以事实上生产者发送消息到partition,消费者从partition读取消息。
4.2、topic的partition数设置
server.properties配置文件中可以指定一个全局的分区数设置,这是对每个主题下的分区数的默认设置,默认是1。
当然每个主题也可以自己设置分区数量,如果创建主题的时候没有指定分区数量,则会使用server.properties中的设置:
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my-topic --partitions 2 --replication-factor 1
在创建主题时候可以使用--partition指定topic的分区数量
4.3、生产者与partition
kafkaTemplate.send(topic, partition, key, data)
默认分区策略:
①如果发送消息时指定partition,则消息投递到指定分区
②如果没有指定partition,但key不是空,则基于key的hash值来选择一个分区
③如果没有指定partition,key也是空,则用轮询方式选择一个分区
4.4、partition与消费者
消费者以consumergroup名义订阅topic,consumergroup中有多个消费实例,同一个consumergroup下消费实例只能以单播方式消费topic下partition内容,每个消息分区 只能被同组的一个消费者进行消费
消费实例和partition对应关系如下:
4.4.1 range消费者分区分配策略
是kafka默认分配策略,限于主题,range分配策略是针对主题,①首先将主题a下partition按数字排序,然后用partition数除以consumergroup1下消费实例总数,如果除尽则平均分配,如果除不尽则位于排序前面的消费者多负责一个分区;②首先将主题a下partition按数字排序,然后用partition数除以consumergroup2下消费实例总数,如果除尽则平均分配,如果除不尽则位于排序前面的消费者多负责一个分区;①②类似,这样原因是kafka针对不同consumergroup是多播消费的;③将主题b进行步骤①、②相同操作
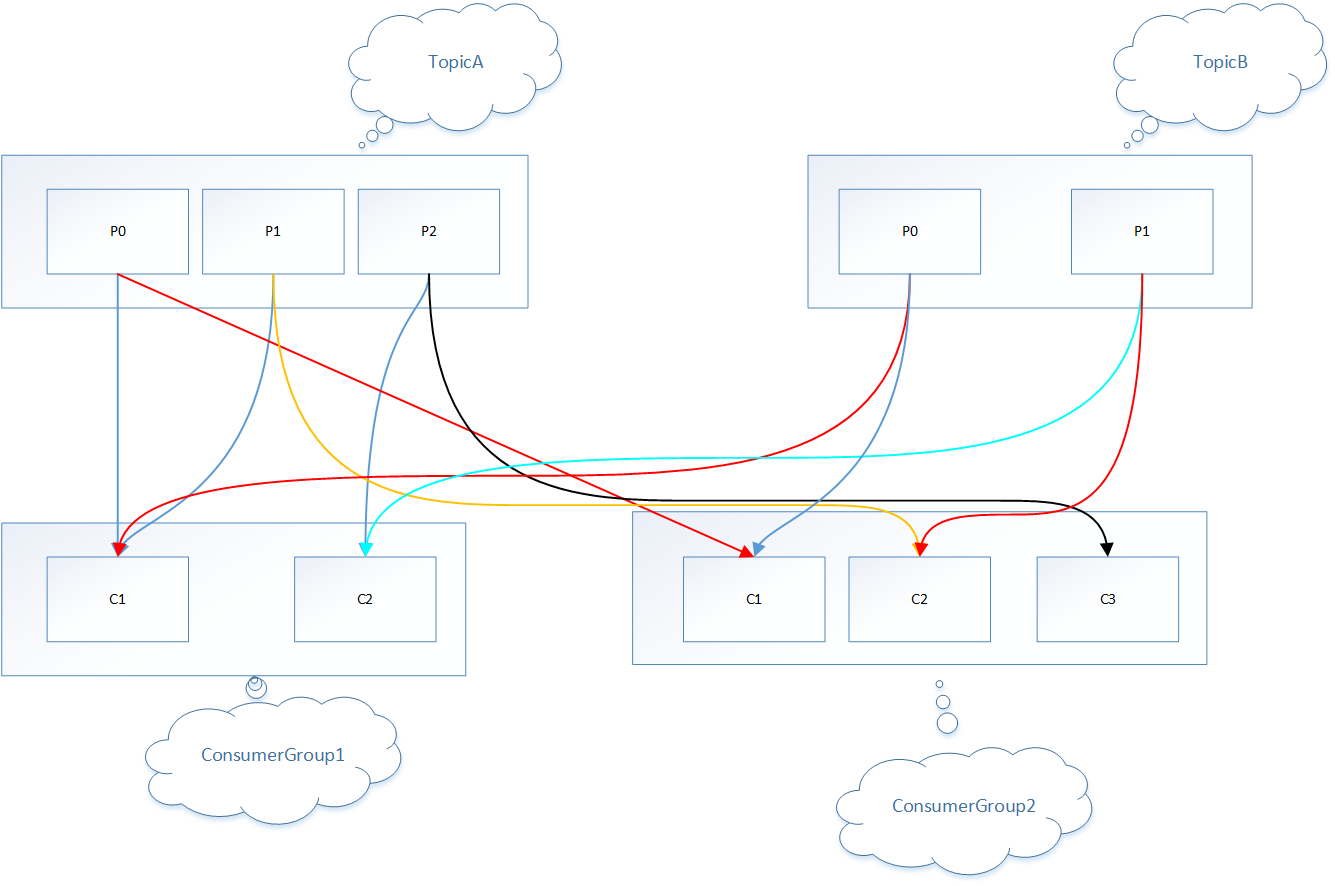
consumergroup1 :
c1:tAp0 tAp1 / tBp0
c2:tAp2 / tBp1
consumergroup2:
c1:tAp0 /tBp0
c2:tAp1 /tBp1
c3:tAp2
4.4.2 roundrobi(轮询)
与前面的range策略最大的不同就是它不再局限于某个主题
如果所有的消费者实例的订阅都是相同的,那么这样最好了,可用统一分配,均衡分配
例如,假设有两个消费者C0和C1,两个主题t0和t1,每个主题有3个分区,分别是t0p0,t0p1,t0p2,t1p0,t1p1,t1p2
那么,最终分配的结果是这样的:
C0: [t0p0, t0p2, t1p1]
C1: [t0p1, t1p0, t1p2]
5、zookeeper在kafka作用
5.1 Broker注册
Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点,每个Broker在启动时,都会到Zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0...N],Kafka使用了全局唯一的数字来指代每个Broker服务器,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。
Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
5.2 topci注册
kafka中,同一个topic信息会被分成多个分区,并将其分布在多个broker上,这些分区信息及broker对应关系是由zookeeper专门节点brokers/topics/[topic]维护的。broker启动后回到对应topic节点注册自己的broker ID并写入针对该topic分区总数,
如/brokers/topics/login/3->2:broker id为3的broker服务器,杜宇login这个topic消息提供2个分区。
这个节点是临时节点
5.3 生产者负载均衡
由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,使用Zookeeper进行负载均衡,由于每个Broker启动时,都会完成Broker注册过程,生产者会通过该节点的变化来动态地感知到Broker服务器列表的变更,这样就可以实现动态的负载均衡机制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号