
1、kafka结构
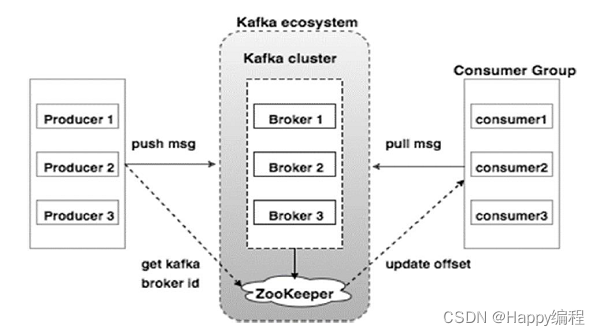
Broker(代理)
Kafka集群通常由多个代理组成以保持负载平衡。 Kafka代理是无状态的,所以他们使用ZooKeeper来维护它们的集群状态。 一个Kafka代理实例可以每秒处理数十万次读取和写入,每个Broker可以处理TB的消息,而没有性能影响。 Kafka经纪人领导选举可以由ZooKeeper完成。
ZooKeeper--ZooKeeper通过心跳机制检查每个节点的连接
ZooKeeper用于管理和协调Kafka代理。 ZooKeeper服务主要用于通知生产者和消费者Kafka系统中存在任何新代理或Kafka系统中代理失败。 根据Zookeeper接收到关于代理的存在或失败的通知,然后生产者和消费者采取决定并开始与某些其他代理协调他们的任务。
Producers(生产者)
生产者将数据推送给经纪人。 当新代理启动时,所有生产者搜索它并自动向该新代理发送消息。 Kafka生产者不等待来自代理的确认,并且发送消息的速度与代理可以处理的一样快。
Consumers(消费者)
因为Kafka代理是无状态的,这意味着消费者必须通过使用分区偏移来维护已经消耗了多少消息。 如果消费者确认特定的消息偏移,则意味着消费者已经消费了所有先前的消息。 消费者向代理发出异步拉取请求,以具有准备好消耗的字节缓冲区。 消费者可以简单地通过提供偏移值来快退或跳到分区中的任何点。 消费者偏移值由ZooKeeper通知。
kafka对外使用topic概念,生产者往topic写消息,消费者从topic读消息。为了做到水平扩展一个topic实际由多个partition组成,通过增加partition数量来进行横向扩容。kafka会为partition选出一个leader,之后所有该partition请求实际操作都是leader,然后再同步到其他follower,当一个broker歇菜后,所有leader在该broker上的partition都会重新选举,选出一个leader
消费偏移量保存:一个消费组消费partition,需要保存offset记录消费到哪,0.10之前offset保存在zk中,0.10之后offset保存在_consumeroffsets topic的topic中。写进消息的key由groupid、topic、partition组成,value是偏移量offset。每个key的offset都是缓存在内存中,查询时候不用遍历partition,如果没有缓存第一次会遍历partition建立缓存,然后查询返回。确定consumer group位移信息写入_consumers_offsets的那个partition计算公式:
__consumers_offsets partition =
Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount)
//groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,默认是50个分区。2、kafka多播消费

kafka同一个topic消息只能被同一个consumer group内其中一个consumer消费,而不能被所有消费者消费,故称为多播,但多个consumer group可同时消费这一消息。
对比rocketmq,同一个topic消息可以被同一个comsumer group内所有consumer消费(采用MessageModel.BROADCASTING方式)
对比rabbitmq,同一个queue内消息只能被一个消费实例消费;采用广播(fanout)方式exchange可以将消息广播到所有绑定的queue中。
kafka如果实现广播,只要每个consumer有一个独立的group即可;如果实现单播消费,只要所有consumer在同一个group里
3、kafka顺序消息
针对部分消息有序(message.key相同的message要保证消费顺序),可以在producer往kafka插入数据时控制,同一个key分发到同一个partition上,因为每个partition是固定分配给某个消费者线程进行消费的。所以对于同一个分区的消息来说是严格有序的;
消息producer在发送消息时,对于一个有着先后顺序的消息A、B,正常情况下应该是A先发送完成后再发送B,但是在异常情况下,在A发送失败的情况下,B发送成功,而A由于重试机制在B发送完成之后重试发送成功了,这时对于本身顺序为AB的消息顺序变成了BA。 为解决此问题,严格的消费需要支持参数:max.in.flight.requests.per.connection,该参数含义:在发送阻塞前对于每个连接,正在发送但是发送状态未知的最大消息数量。如果设置大于1,那么就有可能存在有发送失败的情况下,因为重试发送导致的消息乱序问题。所以我们应该将其设置为1,保证在后一条消息发送前,前一条的消息状态已经是可知的。
rocketmq支持顺序消费方式:message.key相同的message发往同一个queue上
rabbitmq支持顺序消费:exchange不采用广播方式,消息只发送到一条queue上
4、kafka事务
https://www.cnblogs.com/wangzhuxing/p/10125437.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号