

一、树型结构
1 二叉树
每个树结构都只有一个根节点。最下层,没有子节点的节点叫叶子节点。初根节点和叶子节点外的节点叫非叶子节点
1.1 二叉树特性
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的节点(因此,插入的时候一定是叶子节点)。
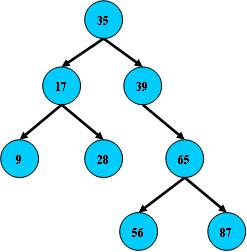
1.2 二叉树插入算法
首先执行查找算法,找出被插结点的父亲结点。判断被插结点是其父亲结点的左、右儿子。将被插结点作为叶子结点插入。 若二叉树为空。则首先单独生成根结点。 注意:新插入的结点总是叶子结点。


public class BinaryTreeDemo { public static void main(String[] args) throws Exception { BinarySearchTree tree=new BinarySearchTree(); tree.insertNode(6); tree.insertNode(1); tree.insertNode(9); System.out.println(tree); } } public class BinarySearchTree { public class Node { private Node root; private Node right; private Node left; private Integer value; public Node getRoot() { return root; } public void setRoot(Node root) { this.root = root; } public Node getRight() { return right; } public void setRight(Node right) { this.right = right; } public Node getLeft() { return left; } public void setLeft(Node left) { this.left = left; } public Integer getValue() { return value; } public void setValue(Integer value) { this.value = value; } public Node(Node left, Node right, Node root, Integer value) { this.left = left; this.right = right; this.root = root; this.value = value; } } /* * 插入节点: * 0、第一个插入的元素作为根节点 * 1、寻找插入节点的父节点 * 2、插入节点值和父节点比较 */ private Node rootNode=null; public void insertNode(Integer num) throws Exception { Node insertNode=new Node(null,null,null,num);//要插入节点 Node tmpNode=this.rootNode;//要插入节点的父节点 Node parentNode=null; //1、寻找插入节点的父节点 while(tmpNode!=null) { parentNode=tmpNode; if(tmpNode.value>insertNode.value) {//如果父节点值>要插入节点值,则取父节点左子节点 tmpNode=tmpNode.getLeft(); }else if(tmpNode.value<insertNode.value) { tmpNode=tmpNode.getRight(); }else { throw new Exception("存在一样的值"); } } //2、找到父节点后插入节点 if(parentNode!=null) { if(parentNode.value>insertNode.value) { parentNode.setLeft(insertNode); }else { parentNode.setRight(insertNode); } }else { //原来是空二叉树 rootNode=insertNode; } } }
2、B-树(B tree)
对于M层B-tree特性如下:
a: 任意非叶子节点至多有M个儿子
b: 根节点儿子个数[2, M]
c: 除根节点外非叶子节点儿子个数[M/2, M]
d: 每个节点存多个元素,元素个数[M/2-1, M-1],并且以升序排列
e: 所有叶子节点位于同一层
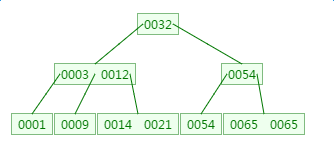
2.1 B-tree 查找
如下有一个3阶的B树,观察查找元素21的过程:
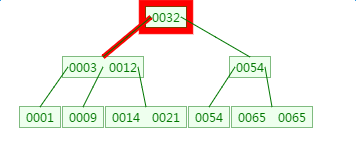
第1次磁盘IO:
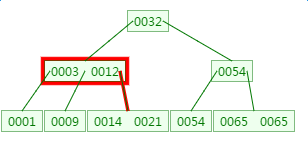
第2次磁盘IO:
这里有一次内存比对:分别跟3与12比对
第3次磁盘IO:
这里有一次内存比对,分别跟14与21比对
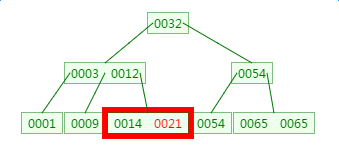
从查找过程中发现,B树的比对次数和磁盘IO的次数与二叉树相差不了多少,所以这样看来并没有什么优势。
但是仔细一看会发现,比对是在内存中完成中,不涉及到磁盘IO,耗时可以忽略不计。另外B树种一个节点中可以存放很多的key(个数由树阶决定)。
相同数量的key在B树中生成的节点要远远少于二叉树中的节点,相差的节点数量就等同于磁盘IO的次数。这样到达一定数量后,性能的差异就显现出来了。
2.2 B tree新增数据
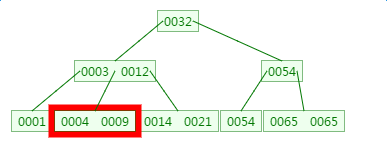
在2.1节基础上新增元素4,他应该在3和9之间
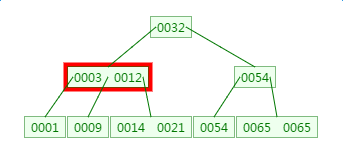
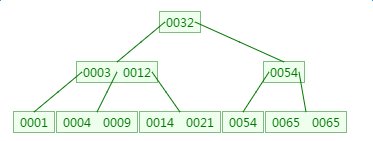
不能加在0003 0012中间是因为0009比0004大,不能作为0004 的左字节点;同样0004不能加在0001中是因为0001 0004都是00003的左子节点,里边元素都要比0003小;不能新建一个叶子节点是因为现在叶子节点个数已经是3个,不能再新增了
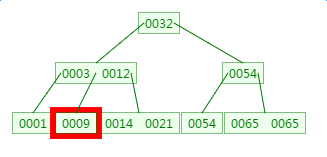
2.3 B tree删除
删除元素9
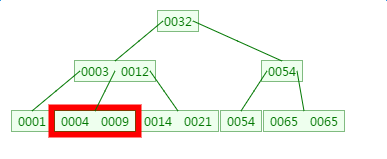
插入或者删除元素都会导致节点发生裂变反应,有时候会非常麻烦,但正因为如此才让B树能够始终保持多路平衡,这也是B树自身的一个优势:自平衡。B树主要应用于文件系统以及部分数据库索引,如MongoDB,大部分关系型数据库索引则是使用B+树实现。
4、B+树
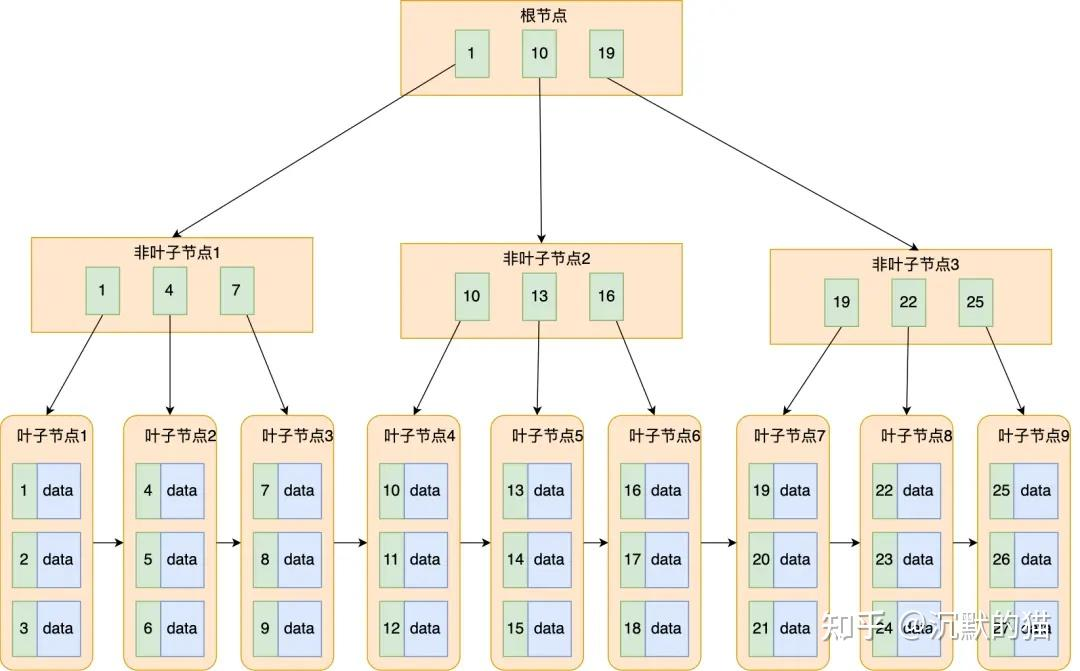
如下一个B+ tree,父节点的所有元素都会出现在子节点中,而且叶子节点包含所有元素
在B+ tree中,非叶子节点只存储索引信息,而数据信息存储在叶子节点中。所以在B+tree索引中,必须查找到叶子节点才能找到数据;而在B tree中每个节点都存储数据的详细信息,当在某个节点找到信息后就不会再往下找,B tree每个节点携带所有详细信息所以占用空间很大,而B+ tree非叶子节点只存储索引信息空间小,依次IO读取节点多。
B+tree每个叶子节点都带有指向下一个节点的指针,形成一个有序链表,这样对于范围查询效率比较高,比如查询语句select * from table where num < 5;查询时直接取5左边的数据即可,及大提高了效率
总结一下B+tree的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
B tree vs B+tree
- B+tree只有叶子节点存放实际的记录数据和索引,非叶子节点只存放索引;而B tree叶子节点和非叶子节点都会存放记录数据和索引;
- 由于B+tree父节点所有元素都会存在子节点中,所以B+tree所有的索引都会出现在叶子节点中,且叶子节点会构成一个有序链表
- 单点查询:B tree效率高
- 插入和删除效率:B+树的插入和删除节点的效率更高
- 范围查询:B+树的叶子节点之间形成了双线链表,对于范围查询很有帮助。而B树只能通过树遍历来完成范围查询
二、mysql索引采用数据结构
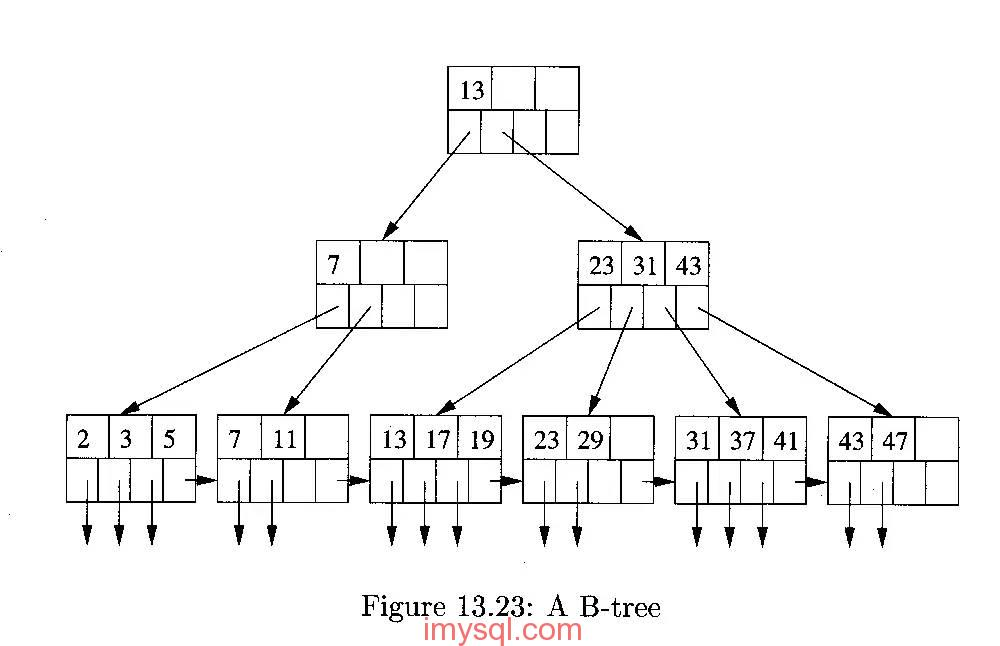
2.1 B+tree 索引
2.2 hash索引
hash索引类似hashmap结构,采用hash算法,把键值转换为新的hash值,不需要像b+tree索引一样必须从root开始逐层寻找,只需进行一次hash计算后找到对应位置,但是这种索引方法适用于等值查询(= in);但hash索引不支持模糊搜索(模糊搜索也是范围搜索一种)、范围搜索的,因为范围搜索经过hash计算后范围和原来范围是不一样的了;同样如果存在大量重复键值情况下也不适合hash索引,因为这容易产生hash碰撞。
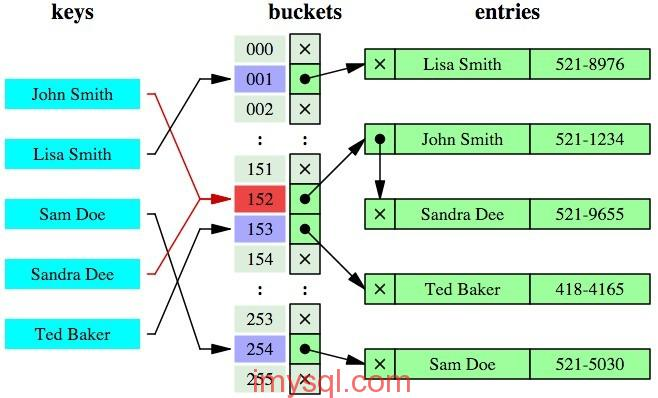
三、mysql数据库引擎
按照B+tree叶子节点存储内容不同分为聚簇索引和非聚簇索引;
聚簇索引查询速度更快,因为聚簇索引主键索引的叶子结点内容就是查询内容;而非聚簇索引主键索引叶子结点内容是查询内容所对应的地址,拿到这个地址后还需要进行二次查询获得所查询具体内容
3.1 myisam引擎的索引--非聚簇索引(B+tree索引)
实现 --叶子结点data区域存储的是数据的存储地址,即索引文件和数据文件是分离的
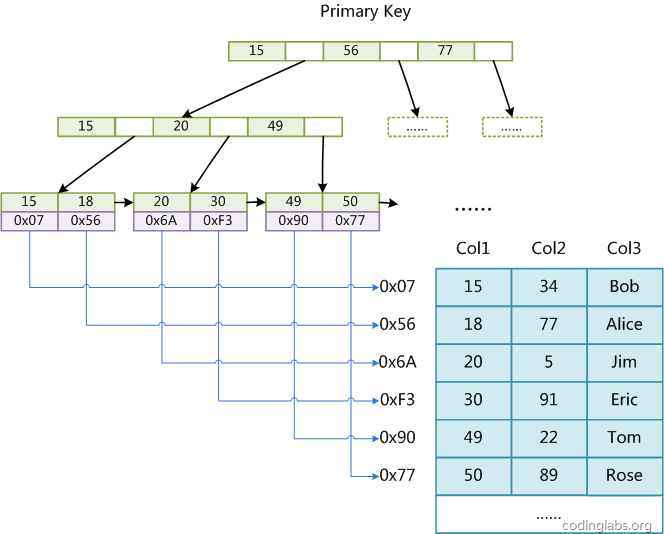
叶子结点包含数据的地址,---非聚簇索引
3.2 innodb引擎的索引实现 --聚簇索引(B+tree索引)
---一般来说,主键作为聚簇索引的索引列,叶子结点data区域存储的是真实的数据,数据本身就是索引树的叶节点,data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
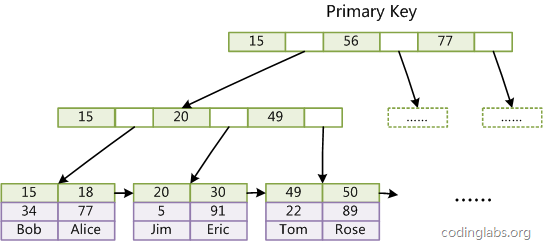
InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。
四、mysql创建索引
4.1 单列索引 唯一索引
where条件的字段设置索
4.2 联合索引
为了提高索引命中率,把where语句中使用最频繁、识别度最高的放在最左边。这是因为mysql索引查询遵循最左匹配原则,检索数据时会从联合索引最左边开始匹配,当我们创建一个联合索引的时候,如(key1,key2,key3),相当于创建了(key1)、(key1,key2)和(key1,key2,key3), (key1, key3)几个索引,这就是最左匹配原则
联合索引遇到范围查询(>、<、between、like)就停止匹配
例子:tableA :a b c d e三列,其中创建联合索引(a,b,c) 那么
select a,b from tableA where a =1 and b like '%cd' and c=1 ;---只会走索引a
select a,b from tableA where a =1 and b like 'cd%' and c=1 ;--会走索引a、b 、c 这两条sql中%放的不同位置影响索引的现象称为前缀索引
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
五、索引下推
mysql5.6之后引入索引下推优化,通过SET optimizer_switch = 'index_condition_pushdown=off';可以将其关闭。
例子:TableA:a、b、c、d、e五列,创建联合索引(a,b)
select * from TableA where a like 'm%' and b>30;
没有采用索引下推,上边sql执行过程:查询a字段以m开头的索引,然后回表查询所有所有满足的数据,然后再过滤掉b>30的数据
采用索引下推,查询a字段以m开头的索引,然后在此基础上过滤b>30的索引,然后回表查询所有满足的数据
可一件采用索引下推可以减少回表查询数据量
非索引下推流程 过滤出满足a的索引——>回表查询满足条件的数据——>j将这些查询出数据过滤掉b的数据
索引下推流程 过滤出满足a的索引——>过滤出满足b的索引——>回表查询满足条件数据
六、数据库隔离级别
隔离级别:串行化、可重复读、读已提交、读未提交
可重复读:在一个事务内,先后读取结果是一样的;
读已提交:事务提交后,修改或添加内容才对外可见。但是读已提交不能避免不可重复读(不可重复读:在一个事务中,先后读取内容不一样),这造成原因是,在事务a执行过程中,事务b update了,事务a中再次读取时候可能和开始读取结果不一样。读已提交隔离级别中为了避免不可重复读,采用乐观锁来解决
参考文献: https://www.cnblogs.com/qixinbo/p/11048269.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号