
一、红黑树
红黑树特点:每个根节点只有两个子节点,且 右子节点key值>根节点key值>左子节点key值
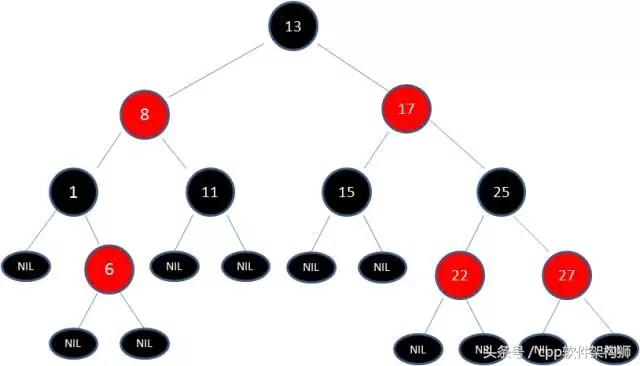
参考:https://www.cnblogs.com/mfrank/p/9227097.html
二、hashmap
HashMap基础概念:
size:hashmap存储k,v个数
capcity:容量,hashmap数组长度,默认为16,超过threashold后执行resize()方法会扩容,扩容就是指扩大capcity大小
loadFactor:加载因子,默认0.75,可以理解为hashmap存储密度
threashold:阈值,threashold=capicty*loadFactory
一、存储结构
1、jdk7
数组+链表
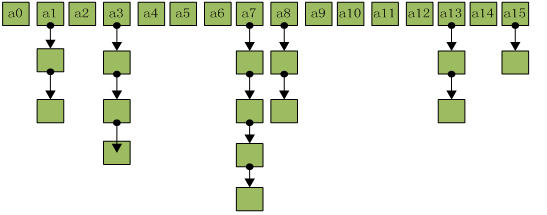
2、jdk8
数组+链表+红黑树
//链表结构 static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; } //红黑树结构 static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; // red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; // needed to unlink next upon deletion boolean red; }
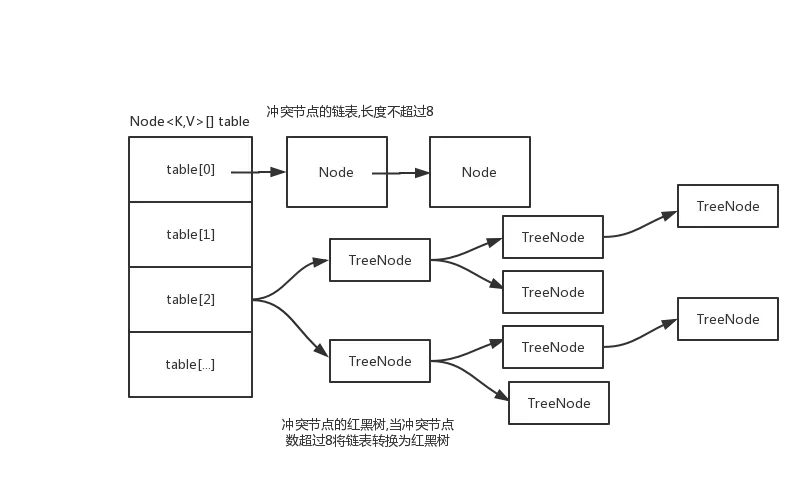
二、put方法
2.1 java7



public V put(K key, V value) { //判断当前Hashmap(底层是Entry数组)是否存值(是否为空数组) if (table == EMPTY_TABLE) { inflateTable(threshold);//如果为空,则初始化 } //判断key是否为空 if (key == null) return putForNullKey(value);//hashmap允许key为空 //计算当前key的哈希值 int hash = hash(key); //通过哈希值和当前数据长度,算出当前key值对应在数组中的存放位置 int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果计算的哈希位置有值(及hash冲突),且key值一样,则覆盖原值value,并返回原值value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //存放值的具体方法 addEntry(hash, key, value, i); //在hashmap tabel【i】创建entry return null; } put()方法中hashmap tabel【i】创建entry方法addEntry()中会判断是否需要resize void addEntry(int hash, K key, V value, int bucketIndex) { //1、判断当前个数是否大于等于阈值 //2、当前存放是否发生哈希碰撞 //如果上面两个条件否发生,那么就扩容 if ((size >= threshold) && (null != table[bucketIndex])) { //扩容,并且把原来数组中的元素重新放到新数组中 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
2.2 java8 putval-addnode-resize-treeifyBin-treeify
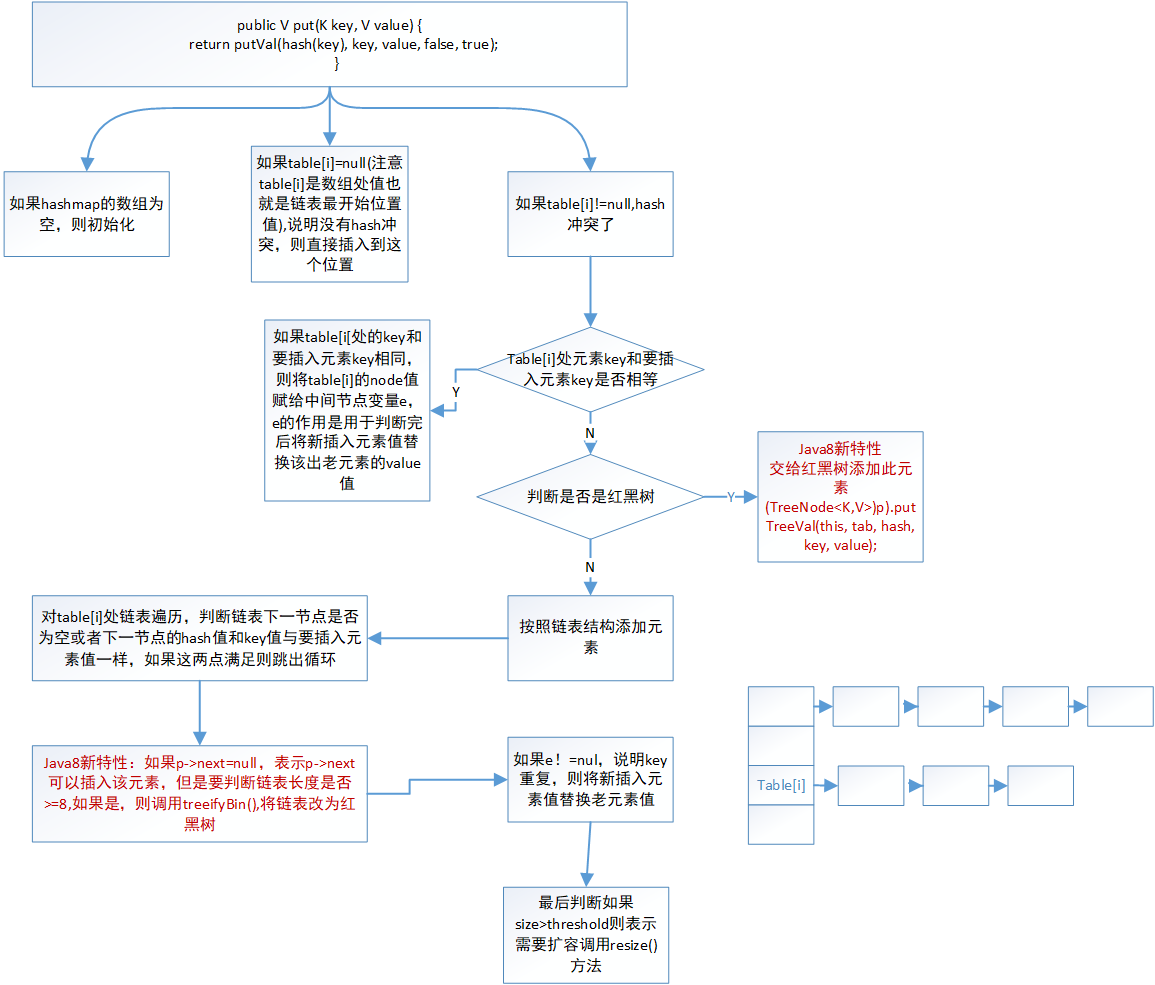
treeifyBin()方法流程:
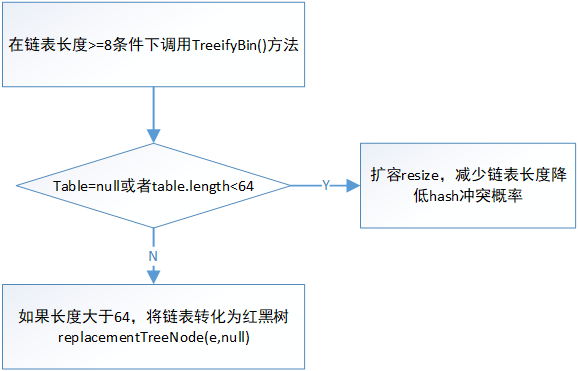
参考:https://blog.csdn.net/qq_38182963/article/details/78942764
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) // 当前对象的数组是null 或者数组长度时0时,则需要初始化数组 n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) //tab[i = (n - 1) & hash] 等价于java7中indexFor方法,作用是获取插入元素在hashmap数组索引位置; 如果通过hash值计算出的下标的地方没有元素,则根据给定的key 和 value 创建一个元素 tab[i] = newNode(hash, key, value, null); //java7中是addEntry方法 else { //如果hash冲突了 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) //如果给定的hash和冲突下标中的 hash 值相等并且 (已有的key和给定的key相等(地址相同,或者equals相同)),说明该key和已有的key相同 e = p; // 那么就将已存在的值赋给上面定义的e变量 else if (p instanceof TreeNode) // 如果以存在的值是个树类型的,则将给定的键值对和该值关联。 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 循环,直到链表中的某个节点为null,或者某个节点hash值和给定的hash值一致且key也相同,则停止循环。 for (int binCount = 0; ; ++binCount) { // 如果next属性是空 if ((e = p.next) == null) { // 那么创建新的节点赋值给已有的next 属性 p.next = newNode(hash, key, value, null); // 如果树的阀值大于等于7,也就是,链表长度达到了8(从0开始)。 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st // 如果链表长度达到了8,且数组长度小于64,那么就重新散列,如果大于64,则创建红黑树 treeifyBin(tab, hash); // 结束循环 break; } // 如果hash值和next的hash值相同且(key也相同) if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) // 结束循环 break; // 如果给定的hash值不同或者key不同。 // 将next 值赋给 p,为下次循环做铺垫 p = e; } } // 通过上面的逻辑,如果e不是null,表示:该元素存在了(也就是他们呢key相等) if (e != null) { // existing mapping for key // 取出该元素的值 V oldValue = e.value; // 如果 onlyIfAbsent 是 true,就不要改变已有的值,这里我们是false。 // 如果是false,或者 value 是null if (!onlyIfAbsent || oldValue == null) // 将新的值替换老的值 e.value = value; // HashMap 中什么都不做 afterNodeAccess(e); // 返回之前的旧值 return oldValue; } } // 如果e== null,需要增加 modeCount 变量,为迭代器服务。 ++modCount; // 如果数组长度大于了阀值 if (++size > threshold) // 重新散列 resize(); // HashMap 中什么都不做 afterNodeInsertion(evict); // 返回null return null; }
treeifyBin()方法:功能是单向链表转化为双向链表;基本流程是先node节点——>TreeNode;然后将单向链表——>双向链表,方便遍历和移动;最后调用treeify()方法将链表树化
final void treeifyBin(Node<K,V>[] tab, int hash) { //在putval()方法中tab=table,即tab就是原来hashmap的table int n, index; Node<K,V> e; if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { //e代表tab[i]处node节点,即tab[i]处最开始处链表 TreeNode<K,V> hd = null, tl = null; do { TreeNode<K,V> p = replacementTreeNode(e, null);//将节点替换为treenode if (tl == null) hd = p; //hd指向头节点 else { p.prev = tl; //将单链表转为双向链表,t1位p的前驱,每次循环更新指向双链表的最后一个元素,用来和p相连,p是当前节点 tl.next = p; } tl = p; } while ((e = e.next) != null); if ((tab[index] = hd) != null) hd.treeify(tab); ////将链表进行树化
} }
treeify()方法功能是将双向链表转化为红黑树:基本逻辑是遍历当前树,找到该节点可以插入的位置,依次遍历节点,比他大的和它右子节点比较,比他小的和它的左子节点比较,直到找到左子节点为null或者右子节点为null的位置插入
final void treeify(Node<K,V>[] tab) { //树的根节点 TreeNode<K,V> root = null; //x是当前节点,next是后继 for (TreeNode<K,V> x = this, next; x != null; x = next) { next = (TreeNode<K,V>)x.next; x.left = x.right = null; //如果根节点为null,把当前节点设置为根节点 if (root == null) { x.parent = null; x.red = false; root = x; } else { K k = x.key; int h = x.hash; Class<?> kc = null; //这里循环遍历,进行二叉搜索树的插入 for (TreeNode<K,V> p = root;;) { //p指向遍历中的当前节点,x为待插入节点,k是x的key,h是x的hash值,ph是p的hash值,dir用来指示x节点与p的比较,-1表示比p小,1表示比p大,不存在相等情况,因为HashMap中是不存在两个key完全一致的情况。 int dir, ph; K pk = p.key; if ((ph = p.hash) > h) dir = -1; else if (ph < h) dir = 1; //如果hash值相等,那么判断k是否实现了comparable接口,如果实现了comparable接口就使用compareTo进行进行比较,如果仍旧相等或者没有实现comparable接口,则在tieBreakOrder中比较 else if ((kc == null && (kc = comparableClassFor(k)) == null) || (dir = compareComparables(kc, k, pk)) == 0) dir = tieBreakOrder(k, pk); TreeNode<K,V> xp = p; if ((p = (dir <= 0) ? p.left : p.right) == null) { x.parent = xp; if (dir <= 0) xp.left = x; else xp.right = x; //进行插入平衡处理 root = balanceInsertion(root, x); break; } } } } //确保给定节点是桶中的第一个元素 moveRootToFront(tab, root); } //这里不是为了整体排序,而是为了在插入中保持一致的顺序 static int tieBreakOrder(Object a, Object b) { int d; //用两者的类名进行比较,如果相同则使用对象默认的hashcode进行比较 if (a == null || b == null || (d = a.getClass().getName(). compareTo(b.getClass().getName())) == 0) d = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1); return d; }
三、扩容方法(扩容是将数组扩容)
扩容触发条件:
①hashmap存储键值对大于阈值:size>threashold ②发生hash冲突:table[i]!=null
具体代码:
public V put(K key, V value) { //判断当前Hashmap(底层是Entry数组)是否存值(是否为空数组) if (table == EMPTY_TABLE) { inflateTable(threshold);//如果为空,则初始化 } //判断key是否为空 if (key == null) return putForNullKey(value);//hashmap允许key为空 //计算当前key的哈希值 int hash = hash(key); //通过哈希值和当前数据长度,算出当前key值对应在数组中的存放位置 int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果计算的哈希位置有值(及hash冲突),且key值一样,则覆盖原值value,并返回原值value if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; //存放值的具体方法 addEntry(hash, key, value, i); //在hashmap tabel【i】创建entry return null; } put()方法中hashmap tabel【i】创建entry方法addEntry()中会判断是否需要resize void addEntry(int hash, K key, V value, int bucketIndex) { //1、判断当前个数是否大于等于阈值 //2、当前存放是否发生哈希碰撞 //如果上面两个条件否发生,那么就扩容 if ((size >= threshold) && (null != table[bucketIndex])) { //扩容,并且把原来数组中的元素重新放到新数组中 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
2.1 java7

void resize(int newCapacity) { //传入新的容量 Entry[] oldTable = table; //引用扩容前的Entry数组 int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了 return; } Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组 transfer(newTable); //!!将数据转移到新的Entry数组里 table = newTable; //HashMap的table属性引用新的Entry数组 threshold = (int) (newCapacity * loadFactor);//修改阈值 } void transfer(Entry[] newTable) { Entry[] src = table; //src引用了旧的Entry数组 int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组 Entry<K, V> e = src[j]; //取得旧Entry数组的每个元素 if (e != null) { src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象) do { //do...while循环中是针对链表遍历操作,上边for循环是针对链表的遍历 Entry<K, V> next = e.next; int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置 e.next = newTable[i]; //标记[1] newTable[i] = e; //将元素放在数组上 e = next; //访问下一个Entry链上的元素 } while (e != null); } } }
static int indexFor(int h, int length) { //indexFor方法得到hash(key)在数组中位置
return h & (length-1);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号