

1、ThreadPoolExcutor参数:
ThreadPoolExecutor(int coresize,int maxPoolsize,long keepalivetime,Timeunit unit,BlockingQueue<Runnable>workqueue)
A:workcount:线程池中当前活动的线程数量,占ctl低29位
B:runstate:线程运行状态,占ctl高三位,有
Running:线程池会处理新任务,也会处理阻塞队列中任务
Shutdown:线程池不会处理新任务,但会处理阻塞队列中任务
Stop:线程池不会处理新任务也不会处理阻塞队列中任务,而且还会终止正在运行的任务
Tidying:所有任务都被终止,而且workCount=0;此状态还调用terminated()方法
Terminated:terminated()方法调用完后进入此状态
C:runStateOf():用于获取ctl高三位:运行状态
D:workCountOf():用于获取ctl低29位:活动线程数量
E:ctlOf(int rs,int wc):rs:runstate,wc:workState,根据runstate和workstate打包合成ctl
F: ctl代表了ThreadPoolExecutor中的控制状态
G:addwork():创建工作线程
H:corePoolSize:线程池核心线程数
I:workQueue:阻塞队列
阻塞队列种类:
| 种类 | 描述 |
| synchronousQueue | 无界;核心线程和最大线程都是0,任务都放入到队列中,每一个插入操作都要等待一个相应的删除操作。通常使用需要将maximumPoolSize的值设置很大,否则很容易触发拒绝策略;sychronousQueue队列是一进一出;它一种阻塞队列,其中每个 put 必须等待一个 take;是线程安全的 |
| ArrayBlockingQueue | 有界;任务大小通过入参 int capacity决定,当填满队列后才会创建大于corePoolSize的线程。 |
| LinkedBlockingQueue | 无界;线程个数最大为corePoolSize,如果任务过多,则不断扩充队列,直到内存资源耗尽。队列会一直从生产者获取数据,并存放在队列中,只有当队列缓冲区达到最大最大缓冲容量(LinkedBlockingQueue可以通过构造函数指定该值)时才会阻塞生产队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒.消费者亦然 |
| PriorityBlockingQueue | 优先任务队列:是一个无界的特殊队列,可以控制任务执行的先后顺序,而上边几个都是先进先出的策略。 |
J:maxmumPoolSize:线程池最大线程数
K:allowCoreThreadTimeOut:允许核心线程超时退出。如果为true,则超过keepAliveTime后,核心线程也会退出,直到workCount=0;如果allowCorePoolTimeOut为false,则超过keepAliveTime后,workCount=CorePoolSize
L:keepAliveTime:空闲时间超时时间,超过该事件后线程会退出
M:rejectPolicy:拒绝策略,分为
abortPolicy:丢弃任务,并且抛出rejectExecutionException


class MyRunnable implements Runnable { private String name; public MyRunnable(String name) { this.name = name; } @Override public void run() { try { System.out.println(this.name + " is running."); Thread.sleep(100); } catch (Exception e) { e.printStackTrace(); } } } public class AbortPolicyDemo { private static final int THREADS_SIZE = 1; private static final int CAPACITY = 1; public static void main(String[] args) throws Exception { // 创建线程池。线程池的"最大池大小"和"核心池大小"都为1(THREADS_SIZE),"线程池"的阻塞队列容量为1(CAPACITY)。 ThreadPoolExecutor pool = new ThreadPoolExecutor(THREADS_SIZE, THREADS_SIZE, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(CAPACITY)); // 设置线程池的拒绝策略为"抛出异常" pool.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy()); try { // 新建10个任务,并将它们添加到线程池中。 for (int i = 0; i < 10; i++) { Runnable myrun = new MyRunnable("task-"+i); pool.execute(myrun); } } catch (RejectedExecutionException e) { e.printStackTrace(); // 关闭线程池 pool.shutdown(); } } } 运行结果: java.util.concurrent.RejectedExecutionException at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:1774) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:768) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:656) at AbortPolicyDemo.main(AbortPolicyDemo.java:27) task-0 is running. task-1 is running.
discartPolicy:丢弃任务,不抛异常
public class DiscardPolicyDemo { private static final int THREADS_SIZE = 1; private static final int CAPACITY = 1; public static void main(String[] args) throws Exception { // 创建线程池。线程池的"最大池大小"和"核心池大小"都为1(THREADS_SIZE),"线程池"的阻塞队列容量为1(CAPACITY)。 ThreadPoolExecutor pool = new ThreadPoolExecutor(THREADS_SIZE, THREADS_SIZE, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(CAPACITY)); // 设置线程池的拒绝策略为"丢弃" pool.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardPolicy()); // 新建10个任务,并将它们添加到线程池中。 for (int i = 0; i < 10; i++) { Runnable myrun = new MyRunnable("task-"+i); pool.execute(myrun); } // 关闭线程池 pool.shutdown(); } }
discartOldestPolicy:丢弃队列最前任务,再重新执行任务
public class DiscardOldestPolicyDemo { private static final int THREADS_SIZE = 1; private static final int CAPACITY = 1; public static void main(String[] args) throws Exception { // 创建线程池。线程池的"最大池大小"和"核心池大小"都为1(THREADS_SIZE),"线程池"的阻塞队列容量为1(CAPACITY)。 ThreadPoolExecutor pool = new ThreadPoolExecutor(THREADS_SIZE, THREADS_SIZE, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(CAPACITY)); // 设置线程池的拒绝策略为"DiscardOldestPolicy" pool.setRejectedExecutionHandler(new ThreadPoolExecutor.DiscardOldestPolicy()); // 新建10个任务,并将它们添加到线程池中。 for (int i = 0; i < 10; i++) { Runnable myrun = new MyRunnable("task-"+i); pool.execute(myrun); } // 关闭线程池 pool.shutdown(); } } 运行结果: task-0 is running. task-9 is running.
callerRunPolicy:当有任务添加到线程池被拒绝后,该拒绝任务添加到正在执行的线程中执行
public class CallerRunsPolicyDemo { private static final int THREADS_SIZE = 1; private static final int CAPACITY = 1; public static void main(String[] args) throws Exception { // 创建线程池。线程池的"最大池大小"和"核心池大小"都为1(THREADS_SIZE),"线程池"的阻塞队列容量为1(CAPACITY)。 ThreadPoolExecutor pool = new ThreadPoolExecutor(THREADS_SIZE, THREADS_SIZE, 0, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(CAPACITY)); // 设置线程池的拒绝策略为"CallerRunsPolicy" pool.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 新建10个任务,并将它们添加到线程池中。 for (int i = 0; i < 10; i++) { Runnable myrun = new MyRunnable("task-"+i); pool.execute(myrun); } // 关闭线程池 pool.shutdown(); } }
ThreadPoolExecutor类中execute()方法执行流程
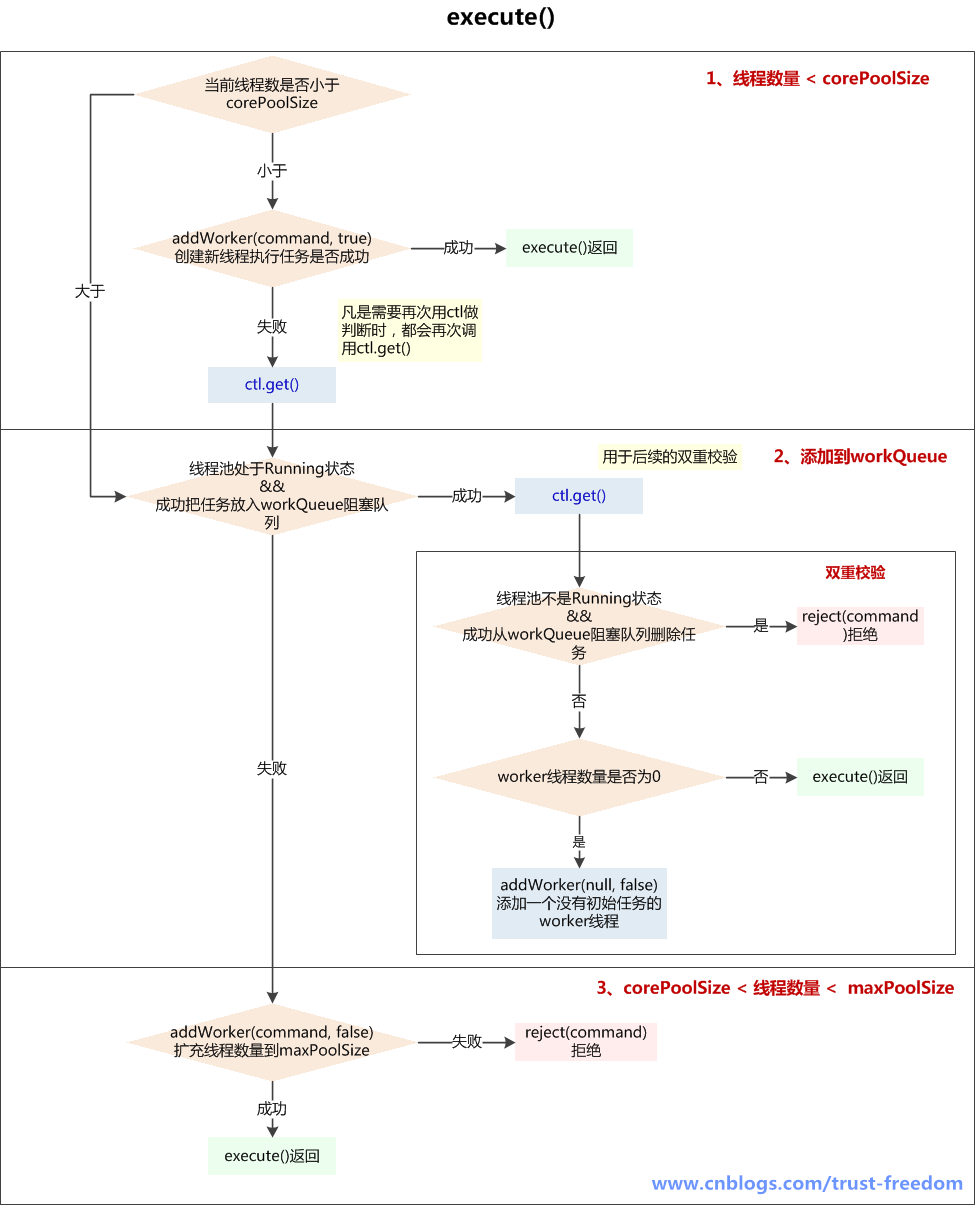
注:新线程的创建时在方法addWorker()中
addWorker创建新线程前提是线程池处于running
addWorker(a,b)方法中a如果不是null则创建一个线程,并且指定第一个任务为a;如果为null,则只是创建一个线程
b如果为Ture则表示占用核心线程,如果为false则表示占用最大线程

public void execute(Runnable command) { if (command == null) throw new NullPointerException(); /* * Proceed in 3 steps: * * 1. If fewer than corePoolSize threads are running, try to * start a new thread with the given command as its first * task. The call to addWorker atomically checks runState and * workerCount, and so prevents false alarms that would add * threads when it shouldn't, by returning false. * 如果运行的线程少于corePoolSize,尝试开启一个新线程去运行command,command作为这个线程的第一个任务 * * 2. If a task can be successfully queued, then we still need * to double-check whether we should have added a thread * (because existing ones died since last checking) or that * the pool shut down since entry into this method. So we * recheck state and if necessary roll back the enqueuing if * stopped, or start a new thread if there are none. * 如果任务成功放入队列,我们仍需要一个双重校验去确认是否应该新建一个线程(因为可能存在有些线程在我们上次检查后死了) 或者 从我们进入这个方法后,pool被关闭了 * 所以我们需要再次检查state,如果线程池停止了需要回滚入队列,如果池中没有线程了,新开启 一个线程 * * 3. If we cannot queue task, then we try to add a new * thread. If it fails, we know we are shut down or saturated * and so reject the task. * 如果无法将任务入队列(可能队列满了),需要新开区一个线程(自己:往maxPoolSize发展) * 如果失败了,说明线程池shutdown 或者 饱和了,所以我们拒绝任务 */ int c = ctl.get(); /** * 1、如果当前线程数少于corePoolSize(可能是由于addWorker()操作已经包含对线程池状态的判断,如此处没加,而入workQueue前加了) */ if (workerCountOf(c) < corePoolSize) { //addWorker()成功,返回 if (addWorker(command, true)) return; /** * 没有成功addWorker(),再次获取c(凡是需要再次用ctl做判断时,都会再次调用ctl.get()) * 失败的原因可能是: * 1、线程池已经shutdown,shutdown的线程池不再接收新任务 * 2、workerCountOf(c) < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount>=corePoolSize */ c = ctl.get(); } /** * 2、如果线程池RUNNING状态,且入队列成功 */ if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get();//再次校验位 /** * 再次校验放入workerQueue中的任务是否能被执行 * 1、如果线程池不是运行状态了,应该拒绝添加新任务,从workQueue中删除任务 * 2、如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),确保还有线程执行任务(只要有一个就够了) */ //如果再次校验过程中,线程池不是RUNNING状态,并且remove(command)--workQueue.remove()成功,拒绝当前command if (! isRunning(recheck) && remove(command)) reject(command); //如果当前worker数量为0,通过addWorker(null, false)创建一个线程,其任务为null //为什么只检查运行的worker数量是不是0呢?? 为什么不和corePoolSize比较呢?? //只保证有一个worker线程可以从queue中获取任务执行就行了?? //因为只要还有活动的worker线程,就可以消费workerQueue中的任务 else if (workerCountOf(recheck) == 0) addWorker(null, false); //第一个参数为null,说明只为新建一个worker线程,没有指定firstTask //第二个参数为true代表占用corePoolSize,false占用maxPoolSize } /** * 3、如果线程池不是running状态 或者 无法入队列 * 尝试开启新线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command */ else if (!addWorker(command, false)) reject(command); } addWorker(null, false) 放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去阻塞任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务
workerCountOf(recheck) == 0:如果workCountof(recheck)是0的话说明不存在活动线程,此时任务都放到阻塞队列中,如果活动线程不等于0,
说明存在活动的线程,这种情况下阻塞队列中不存在任务(活动的线程会被占用去执行阻塞队列中任务,在存在活动线程的条件下阻塞队列中必然没有任务了)
| 入参方式 | |
| addWorker(firstTask, true) | 程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false |
| addWorker(firstTask, false) | 当阻塞队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false |
| addWorker(null, false) | 放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去阻塞任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务 |
| addWorker(null, true) |
这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行 |
2、几种常用线程池
①newCachedThreadPool的核心线程数是0,最大线程是Interge最大值,采用阻塞队列是synchronousQueue
创建可缓存线程池,线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
创建方式:
ExecutorService cacheThreadPool=Executors.newCachedThreadPool(); public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
②newFixedThreadPool的核心线程数=最大线程数=设置线程数,采用阻塞队列是LinkedBlockingQueue
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待
创建方式:
ExecutorService fixedThreadPool=Executors.newFixedThreadPool(5); public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
③newSingledThreadPool的核心线程数=最大线程数=1,采用阻塞队列是LinkedBlockingQueue
保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
创建方式:
ExecutorService singleThreadPool=Executors.newSingleThreadExecutor(); public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
使用nexfixedThreadPool虽然只会创建一个线程来执行任务,但相对于同步执行和直接使用单线程好处:
a)newFixedThreadPool异步执行,避免主线程阻塞;
b)newFixedThreadPool线程复用,当任务2执行时,任务 1执行结束,任务2可以复用任务1线程
c)newFixedThreadPool有阻塞队列,可以累计任务
d)newFixedThreadPool可以使用Future获取异步任务以及异常处理
④newScheduleThreadPool的核心线程=设置线程,最大线程=Integer.max,阻塞队列是delayedworkQueue,delayedWorkQueue作用是按照延时时间做一个排序,延时时间少的任务会优先执行
定时执行任务
创建一个定长线程池,支持定时及周期性任务执行。
创建方式:
ExecutorService scheduleThreadPool=Executors.newScheduledThreadPool(5); public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS, new DelayedWorkQueue()); }
3.newfixedThreadpool核心线程数选择
IO密集型:处理业务逻辑比较简单,但处理数据很多,每条数据都要插入到数据库,和db交互很多。IO密集型核心线程数=2*CPU核数,最大线程数=2*CPU核数+1
CPU密集型(计算密集型):可以理解为处理繁杂算法操作,和db交互较少。CPU密集型核心线程数设置成和CPU核数一样,最大线程数=CPU核数+1
4. 线程池中线程异常后可用性分析
异常被捕获: 异常被捕获的情况下,会终止当前任务,线程返回线程池继续可用
异常未被捕获:submit 提交到线程池的方式,如果执行中抛出异常,并且没有catch,不会抛出异常,不会创建新的线程。
execute 提交到线程池的方式,如果执行中抛出异常,并且没有在执行逻辑中catch,那么会抛出异常,并且移除抛出异常的线程,创建新的线程放入到线程池中。
参考:https://www.cnblogs.com/trust-freedom/p/6681948.html#label_3_2
https://blog.csdn.net/mayongzhan_csdn/article/details/80790966

 浙公网安备 33010602011771号
浙公网安备 33010602011771号