


1.大多考到了 计算机网络 tcpip 和 操作系统 多线程的知识 直接 懵逼
2. 考到了 递归的全排列
#include<iostream>
using namespace std;
void swap(int &a,int &b)
{
int temp ;
temp=a;
a=b;
b=temp;
}
void show(int a[],int n) //显示全部数组
{
for(int i=0;i<n;i++ )
{
cout<<a[i]<<" ";
}
cout<<endl;
}
void prim(int a[],int k, int n) //n是这个a[]中有多少个元素 ,k是a[]需要全排列的的坐下标
{
if(k==n-1)//不是只有一个元素 而是全排列到最后一个数字时 终止递归的条件
{
show(a,n);
}
else
{
for(int i=k;i<n;i++) //从k开始时保证交换和递归次数
{
swap(a[i],a[k]); //第一次 自己和自己交换即自己是最前单一前缀 交换单一前缀和后缀中的每一个元素 ,让每一个元素都可以做前缀
prim(a,k+1,n);
swap(a[i],a[k]); //回溯之后 仍然恢复交换以前的顺序
}
}
}
int main(int argc, char* argv[])
{
int a[3]={1,2,3};
prim(a,0,3);
system("PAUSE");
return 0;
}
如果 只有两个 [1,2]的话 我是看懂了
3.多态 继承 和 封装
http://blog.csdn.net/ruyue_ruyue/article/details/8211809
C++封装继承多态总结
面向对象的三个基本特征
面向对象的三个基本特征是:封装、继承、多态。其中,封装可以隐藏实现细节,使得代码模块化;继承可以扩展已存在的代码模块(类);它们的目的都是为了——代码重用。而多态则是为了实现另一个目的——接口重用!
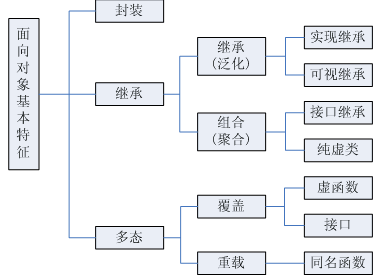
封装
什么是封装?
封装可以隐藏实现细节,使得代码模块化;封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封装的对象,这些对象通过一个受保护的接口访问其他对象。在面向对象编程上可理解为:把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
什么是继承?
继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。其继承的过程,就是从一般到特殊的过程。
通过继承创建的新类称为“子类”或“派生类”。被继承的类称为“基类”、“父类”或“超类”。要实现继承,可以通过“继承”(Inheritance)和“组合”(Composition)来实现。在某些 OOP 语言中,一个子类可以继承多个基类。但是一般情况下,一个子类只能有一个基类,要实现多重继承,可以通过多级继承来实现。
继承的实现方式?
继承概念的实现方式有三类:实现继承、接口继承和可视继承。
1. 实现继承是指使用基类的属性和方法而无需额外编码的能力;
2. 接口继承是指仅使用属性和方法的名称、但是子类必须提供实现的能力;
3. 可视继承是指子窗体(类)使用基窗体(类)的外观和实现代码的能力。
多态
什么是多态?
多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。简单的说,就是一句话:允许将子类类型的指针赋值给父类类型的指针。
例子:(2012某**软件公司笔试题)
请按顺序写出下面代码的输出结果:

答案:call child func
call ~child
call ~base
多态的实现方式分析?
实现多态,有二种方式,覆盖,重载。覆盖:是指子类重新定义父类的虚函数的做法。重载:是指允许存在多个同名函数,而这些函数的参数表不同(或许参数个数不同,或许参数类型不同,或许两者都不同)。
分析:
“重载”是指在同一个类中相同的返回类型和方法名,但是参数的个数和类型可以不同
“覆盖\重写”是在不同的类中。
其实,重载的概念并不属于“面向对象编程”,重载的实现是:编译器根据函数不同的参数表,对同名函数的名称做修饰,然后这些同名函数就成了不同的函数(至少对于编译器来说是这样的)。如,有两个同名函数:function func(p:integer):integer;和function func(p:string):integer;。那么编译器做过修饰后的函数名称可能是这样的:int_func、str_func。对于这两个函数的调用,在编译器间就已经确定了,是静态的(记住:是静态)。也就是说,它们的地址在编译期就绑定了(早绑定),因此,重载和多态无关!真正和多态相关的是“覆盖”。当子类重新定义了父类的虚函数后,父类指针根据赋给它的不同的子类指针,动态(记住:是动态!)的调用属于子类的该函数,这样的函数调用在编译期间是无法确定的(调用的子类的虚函数的地址无法给出)。因此,这样的函数地址是在运行期绑定的(晚邦定)。结论就是:重载只是一种语言特性,与多态无关,与面向对象也无关!引用一句Bruce Eckel的话:“不要犯傻,如果它不是晚邦定,它就不是多态。”
C++多态机制的实现:
该部分转自:http://blog.chinaunix.net/uid-7396260-id-2056657.html
1、c++实现多态的方法
面向对象有了一个重要的概念就是对象的实例,对象的实例代表一个具体的对象,故其肯定有一个数据结构保存这实例的数据,这一数据包括对象成员变量,如果对象有虚函数方法或存在虚继承的话,则还有相应的虚函数或虚表指针,其他函数指针不包括。
虚函数在c++中的实现机制就是用虚表和虚指针,但是具体是怎样的呢?从more effecive c++其中一篇文章里面可以知道:是每个类用了一个虚表,每个类的对象用了一个虚指针。要讲虚函数机制,必须讲继承,因为只有继承才有虚函数的动态绑定功能,先讲下c++继承对象实例内存分配基础知识:
从more effecive c++其中一篇文章里面可以知道:是每个类用了一个虚表,每个类的对象用了一个虚指针。具体的用法如下:
class A
{public:
virtual void f();
virtual void g();
private:
int a
};
class B : public A
{
public:
void g();
private:
int b;
};
//A,B的实现省略
因为A有virtual void f(),和g(),所以编译器为A类准备了一个虚表vtableA,内容如下:
|
A::f 的地址 |
|
A::g 的地址 |
B因为继承了A,所以编译器也为B准备了一个虚表vtableB,内容如下:
|
A::f 的地址 |
|
B::g 的地址 |
注意:因为B::g是重写了的,所以B的虚表的g放的是B::g的入口地址,但是f是从上面的A继承下来的,所以f的地址是A::f的入口地址。然后某处有语句 B bB;的时候,编译器分配空间时,除了A的int a,B的成员int b;以外,还分配了一个虚指针vptr,指向B的虚表vtableB,bB的布局如下:
|
vptr : 指向B的虚表vtableB |
|
int a: 继承A的成员 |
|
int b: B成员 |
当如下语句的时候:
A *pa = &bB;
pa的结构就是A的布局(就是说用pa只能访问的到bB对象的前两项,访问不到第三项int b)
那么pa->g()中,编译器知道的是,g是一个声明为virtual的成员函数,而且其入口地址放在表格(无论是vtalbeA表还是vtalbeB表)的第2项,那么编译器编译这条语句的时候就如是转换:call *(pa->vptr)[1](C语言的数组索引从0开始哈~)。
这一项放的是B::g()的入口地址,则就实现了多态。(注意bB的vptr指向的是B的虚表vtableB)
另外要注意的是,如上的实现并不是唯一的,C++标准只要求用这种机制实现多态,至于虚指针vptr到底放在一个对象布局的哪里,标准没有要求,每个编译器自己决定。我以上的结果是根据g++ 4.3.4经过反汇编分析出来的。
2、两种多态实现机制及其优缺点
除了c++的这种多态的实现机制之外,还有另外一种实现机制,也是查表,不过是按名称查表,是smalltalk等语言的实现机制。这两种方法的优缺点如下:
(1)、按照绝对位置查表,这种方法由于编译阶段已经做好了索引和表项(如上面的call *(pa->vptr[1]) ),所以运行速度比较快;缺点是:当A的virtual成员比较多(比如1000个),而B重写的成员比较少(比如2个),这种时候,B的vtableB的剩下的998个表项都是放A中的virtual成员函数的指针,如果这个派生体系比较大的时候,就浪费了很多的空间。
比如:GUI库,以MFC库为例,MFC有很多类,都是一个继承体系;而且很多时候每个类只是1、2个成员函数需要在派生类重写,如果用C++的虚函数机制,每个类有一个虚表,每个表里面有大量的重复,就会造成空间利用率不高。于是MFC的消息映射机制不用虚函数,而用第二种方法来实现多态,那就是:
(2)、按照函数名称查表,这种方案可以避免如上的问题;但是由于要比较名称,有时候要遍历所有的继承结构,时间效率性能不是很高。(关于MFC的消息映射的实现,看下一篇文章)
3、总结:
如果继承体系的基类的virtual成员不多,而且在派生类要重写的部分占了其中的大多数时候,用C++的虚函数机制是比较好的;但是如果继承体系的基类的virtual成员很多,或者是继承体系比较庞大的时候,而且派生类中需要重写的部分比较少,那就用名称查找表,这样效率会高一些,很多的GUI库都是这样的,比如MFC,QT
PS 其实,自从计算机出现之后,时间和空间就成了永恒的主题,因为两者在98%的情况下都无法协调,此长彼消;这个就是计算机科学中的根本瓶颈之所在。软件科学和算法的发展,就看能不能突破这对时空权衡了。呵呵
何止计算机科学如此,整个宇宙又何尝不是如此呢?最基本的宇宙之谜,还是时间和空间~
16进制 转 字符串数组 基本思路是这样子的,也考到了
#include<iostream>
using namespace std;
int strOne(char * dest, char *src){
int x,y;
dest[0] = '0';
dest[1] = 'x';
x = (int)src[0] / 16;
y = (int)src[0] % 16;
dest[2] = (x>=10)?('A'+x-10):('0'+ x);
dest[3] = (y>=10)?('X'+y-10):('0'+ y);
}
int main(int argc, char* argv[])
{
char ss[2]={0x11,0x22};
char pp[100] = {0};
strOne(pp,ss);
cout<<pp<<endl;
system("PAUSE");
return 0;
}
在日常工作中常常要进行字符串的复制工作,而strcpy是大家常用的字符串复制函数,现在要详细地说明这个函数可能带来的错误,并给我的使用心得。
首先,看看MSDN怎么说:
strcpy
原型:char *strcpy(char *dest,char *src);
用法:#include <string.h>
功能:把src所指由NULL结束的字符串复制到dest所指的数组中。
说明:src和dest所指内存区域不可以重叠且dest必须有足够的空间来容纳src的字符串。
返回指向dest的指针。
strcpy只是复制字符串,但不限制复制的数量。很容易造成缓冲溢出,也就是说,不过dest有没有足够的空间来容纳src的字符串,它都会把src指向的字符串全部复制到从dest开始的内存,举例说明:
容易造成的后果。

