


简介
实例基本流程:
数据载入->数据可视化与预处理->模型创建->全数据用于模型训练->模型评估
数据分离可以用于模型评估
对全数据进行数据分离,部分用于训练,部分用于新数据的结果预测!
通常来说分为3步:
- 把数据分成两部分:训练集、测试集
- 使用训练集数据进行模型训练
- 使用测试集数据进行预测,更有效地评估模型对于新数据的预测表现
这里的训练集和测试集的比例可以灵活调整, 参考:训练集占70%,测试集占30%;也可能训练集占80%,测试集占20%。
混淆矩阵
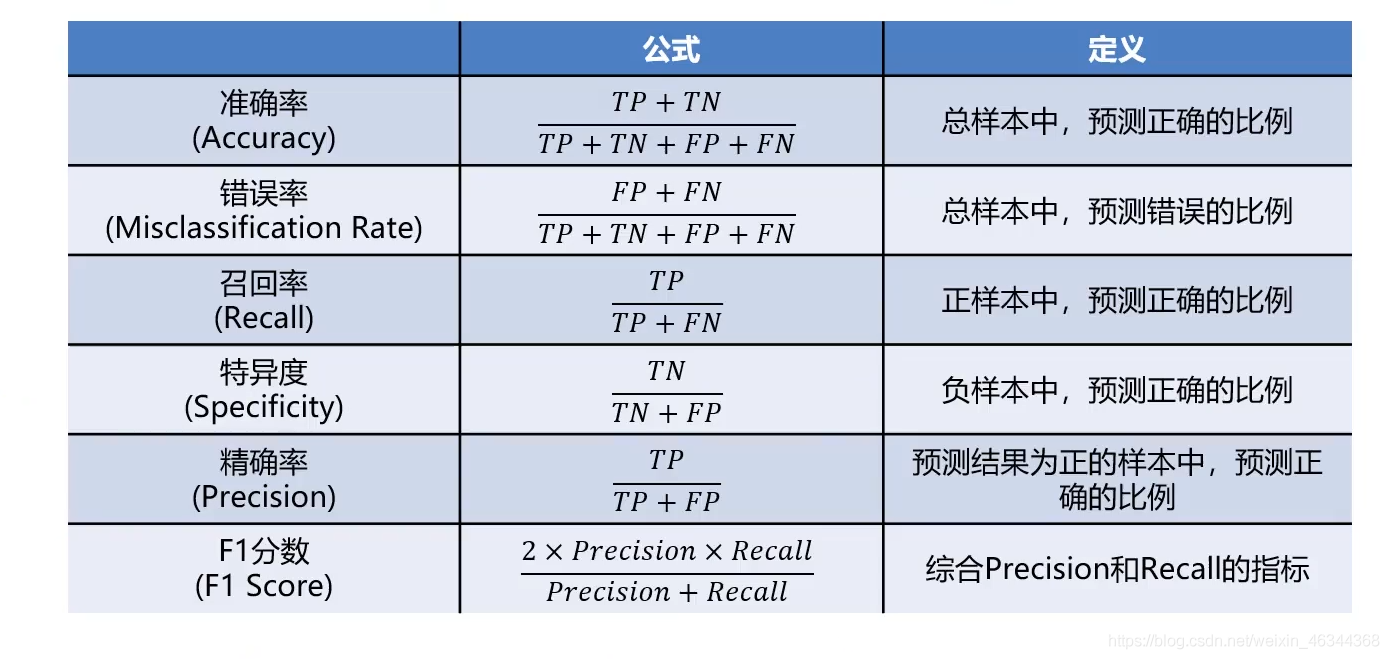
在我们前面的分类任务中,都是计算测试数据集预测准确率以评估模型表现,但如果只用accuracy会有很大的局限性,无法真实反映模型针对各个分类的预测准确度
准确率(accuracy):没有体现数据预测的实际分布情况(0,1本身的分布比例), 没有体现模型错误预测的类型

TP: T预测准确,P实际为正样本
TN: T预测准确,N实际为负样本
FP: F预测错误,P实际为负样本
FN: F预测错误,N实际为正样本
可以计算更丰富的模型评估指标
参考链接
https://blog.csdn.net/weixin_46344368/article/details/106845649?spm=1001.2014.3001.5502
---------------------------我的天空里没有太阳,总是黑夜,但并不暗,因为有东西代替了太阳。虽然没有太阳那么明亮,但对我来说已经足够。凭借着这份光,我便能把黑夜当成白天。我从来就没有太阳,所以不怕失去。
--------《白夜行》


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2016-04-25 记录每天 做了什么