
机器学习部分
Q:什么是机器学习算法?
机器学习算法好比一个搜索过程,它从一组可能的函数中找到能够最好地解释数据集中不同特征之间关系的那个函数。
——John D.Kelleher
机器学习旨在开发和评估能够使计算机从数据集(一组样本)中提取(或学习)函数的算法。
要理解机器学习,必须要理解三个概念:数据集、算法和函数。
数据集
数据集最简单的形式就是一张表,其中每一行是对来自某个域的一个样本的描述,而每一列则是有关该域中的一个特征的信息。
算法
算法是计算机能够执行的过程(或程序,好比处方或食谱)。在机器学习中,算法定义了对数据集进行分析并从中发现重复出现模式的过程。
函数
函数给出了从一组输入值到一个或多个输出值之间的确定性映射。
过程
一般的机器学习过程分为两个阶段:训练和推断(现在一般会在训练过程中补充验证)
一个比较好的比喻是:训练好比学生学习,而验证是学生写作业,推断是学生考试。
老师给学生安排一个学习任务(知识点),学生通过学习来掌握这个知识点。而老师通过给学生发放作业,对学生完成作业的情况来调整当前教学方法,最后用考试来判断学生对知识点的泛化能力。
机器学习三大关键要素
-
数据(已知的一组样本)
-
函数集(算法从函数集中找出与数据最匹配的函数)
-
拟合度度量(衡量函数集中的每一个函数能够在多大程度上与数据相匹配,在深度学习模型中,一般用loss表示)
根据数据集的表示形式、候选函数和拟合度度量函数的定义,机器学习算法分为:有监督学习,无监督学习(还有半监督学习,一般是数据集部分有标签,部分没有)和强化学习。
有监督学习
在有监督学习中,数据集中的每一个样本都被标注好了相应的输出(目标)值。
常用于回归问题与聚类问题。
注:许多时候,要标注目标值可能会非常困难,或者成本非常高。一些情况下,不得不请专家为数据集中的每一个样本标注正确的目标值。
无监督学习
在无监督学习中,数据集是没有标签的。
常用于聚类和降维问题。
强化学习
强化学习是指机器以"试错"的方式进行学习,通过与环境进行交互获得的奖励来指导行为。
一个完整的过程:让计算机实现从一开始什么都不懂, 脑袋里没有一点想法, 通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法。
强化学习的目标是从环境中获取最大的奖励。
深度学习部分
通过从大量将复杂输入精确映射到好的决策结果的数据中发现和提取模式,深度学习实现了数据驱动的决策。
决定任何一种数据驱动过程能否成功的首要因素是搞清楚数据需要测量的是什么,以及应该如何测量。
——John D.Kelleher
一般传统的机器学习项目,大部分时间和资源可能都用在设计和准备数据上,有时候甚至要花去整个项目预算的80%之多。
对于特征设计任务,深度学习相比于传统机器学习具有显著优势。因为深度学习另辟蹊径,直接从原始数据中自动学习用于解决问题最有用的特征。(BMI就是推算出的特征往往比原始特征更好用的例子)
深度学习网络是受人脑结构启发而形成的数学模型(尽管这一说法并不是那么严谨)。因此,要理解深度学习,最好先对以下内容有所了解:什么是数学模型,如何设置模型的参数,如何组合(或构造)模型,以及如何从几何的角度理解模型处理信息的方法。
数学模型
数学模型是描述一个或多个输入变量与输出变量之间关系的方程。在这一意义下,数学模型等同于函数,即从输入到输出的映射。
设置模型参数
这里的模型参数是指权重,而机器学习所要做的就是利用数据找出模型的参数(或权重)值。
一般是通过特定算法取初始权重,后续根据别的算法(如梯度下降法或具体如SGD、Adam等)来迭代更新参数,使模型越来越好,与数据越来越匹配。
模型的组合
将一个模型的输出用作另一个模型的输入,我们就能通过组合这两个模型构建出第三个模型。这样一种通过组合较小、较简单的模型构建复杂模型的策略便是深度学习网络的核心思想。
模型几何意义
虽然数学模型可以用方程来表示,但是能理解模型背后的几何意义同样非常有用。
以一个简单的深度学习模型为例:
输入空间
将每个输入变量作为一个坐标轴,可以在相应坐标系中绘制出的坐标系空间就是输入空间。其中每一个点定义模型的一组可能的输入值组合。(以上图为例,输入变量共四个,即可绘制4维的输入空间)
权重空间
将模型的每一个权重作为一个坐标轴,在相应坐标系中画出模型的权重空间。其中每一个点定义了模型一组可能的权重组合。(以上图为例,输入层到第一个隐藏层共4 * 5个权重变量,第一个隐藏层到第二个隐藏层共5 * 3个权重变量,即分别可绘制20维和15维的权重空间)
激活空间
将一组输入值映射到新空间的一个点:将每个输入与一个权重相乘,再求这些乘积的和。这样的空间称为决策(或激活)空间,该空间的坐标轴对应相应的加权输入。即激活空间中的每一个点定义了一组加权输入。将决策规则应用在激活空间的每一个点,记录对应决策结果并画出边界,可得到决策边界。(以上图为例,第一个隐藏层有5个激活空间,每个激活空间都是4维空间)
决策边界的例图如下:
深层神经网络
神经网络
神经网络是一类受人脑结构启发而形成计算模型。
神经网络模型是由多层被称为神经元的简单信息处理程序组成。而深度学习是对这一类神经网络模型的统称。
人脑与神经网络计算模型间的相似处:
-
大脑由大量相互连接的称为神经元的简单单元组成
-
大脑的功能就是处理信息,这些信息被编码成或高或低的电信号或动作电位,散布于神经元构成的网络中
-
每一个神经元从与之相邻的神经元接收一组激励,并将这些输入映射成或大或小的输出值
神经网络结构
仍以该图为例:
一般的神经网络结构为:输入层、隐藏层(指既不是输入层也不是隐藏层的层)和输出层。
而深度学习网络是指含有很多个由神经元组成隐藏层的神经网络。一个神经网络要被称为深度学习网络就必须含有至少两个隐藏层,不过大部分深度学习网络含有的隐藏层数目远多于两个。
神经元信息处理
神经元实现的也是将多个输入映射为一个输出的两阶段信息处理方法:
-
计算神经元输入值的加权和
-
将加权和输入一个函数,该函数将加权和映射为神经元的最终输出值(显然我们回头看,这个函数就是激活函数咯)
加权和部分:
如上例图可知,网络中每个连接将两个神经元连起来,并且是有向连接,也就是说信息只沿一个方向传播。每个连接都关联着一个权重,虽然连接权重只是简单的数字,但它们非常重要,影响着神经元对沿着连接接收到的信息的处理方式。实际上,训练一个人工神经网络的本质就是在寻找最好(最优)的权重!
激活函数部分:
神经网络,特别是深度学习网络,往往被用于很复杂的关系建模,要准确建模,网络必须能学习和表示复杂的非线性映射。因此,为使神经网络能实现这样的非线性映射,网络神经元在处理信息时就必须包含非线性步骤(激活函数)
同时,大多激活函数有很好的数学性质,有利于神经网络的训练,因此神经网络研究中引入激活函数是非常普遍的!
在神经元处理信息中引入非线性是网络能学习输入和输出之间的非线性映射,这一点也是神经网络中神经元之间的交互引发网络总体行为的体现。
神经网络采用分而治之的策略解决问题:
网络中的每个神经元解决整个问题的一部分,而组合这些神经元的解就能得到整个问题的解。神经网络的一个重要能力是,在训练过程中,随着网络连接权重被设置,网络实际上就是在学习问题的分解,而单个神经元则是在学习如何解决分解后的问题,以及如何组合求得的解。
关于加权和函数的补充:
同一层神经元的加权和函数可以通过一次性矩阵乘法运算实现,这一点很重要---这意味着神经网络可以被看成一系列的矩阵运算,这使得我们可以使用专门对快速矩阵乘法进行优化的GPU硬件来加速网络的训练,这样的加速反过来又使得我们能够使用更大的神经网络。
一些本质问题(多个隐藏层:逐步抽象化)
在含有多个隐藏层的深度网络中,每一个后续隐藏层都可以看成在学习相对于前一层输出更加抽象化的表示。正是这种通过学习中间表示进行逐步抽象化的能力使深度网络能够学习由输入到输出的非常复杂的映射。
一些本质问题(调参侠?炼丹师?run了run了)
神经网络本质上是一组神经元的组合,这使得从非常基础的层面上理解神经网络的运行机制成为可能(通过以上内容可知哈)。然而,神经网络的组合本质也引起了有关如何组合出能解决特定问题的神经网络的一些新问题,比如:
-
网络中的神经元应该使用哪个激活函数?
-
网络应该含有多少层?
-
没一层应该含有多少神经元?
-
这些神经元应该怎样连接在一起?
遗憾的是,这些问题中的大部分没有原则上的最优答案。在机器学习中,为了区别模型参数,与这些问题相关的概念被称为超参(即网络中由数据科学家在训练之前手动设置的元素,或者指神经网络结构的参数)。神经网络的参数是连接边的权重,这些是通过大数据集上训练网络确定出来的。
超参需要模型的构建者利用启发式规则、直觉或试错法来设定。通常,创建深度学习网络的很多精力都花在了解决与超参有关的问题的实验上,而这一过程被称为调参。
后来想想,所谓深度学习没有确切具体的理论支撑,指的就是调参所遇到的问题吧(深夜炼丹是这样的)
训练
梯度下降
误差平方和函数(SSE)
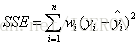
该函数将模型在一个含有n个样本的数据集上的误差累加起来,通过将数据集中给出的样本的正确目标值减去模型对样本目标值的预测值来计算数据集中每个样本的模型误差。
以一个权重的线性回归模型作出SSE图像

该模型仅有一个权重,线性模型的误差随着模型参数的变化而变化,由图像可知,该模型有且仅有在J值最小即权重为w时,模型的拟合效果最好
以两个权重的线性回归模型作出SSE图像
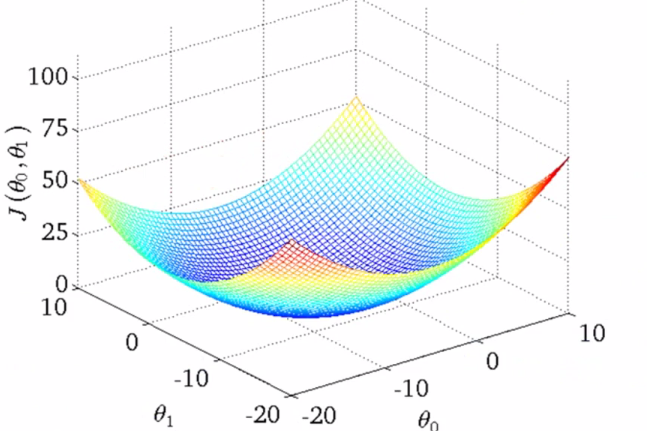
当模型的两个参数都在变化时,模型误差将会形成一个三维碗状凸曲面,称为误差曲面。
该误差曲面形状表明对于给定的数据集只有一个最优线性模型。凸的或碗状的误差曲面在学习能够对数据集进行建模的线性函数中非常有用,因为这意味着学习过程就是要找出误差曲面上的最低点。
而梯度下降算法正是寻找这样的最低点的标准算法。
梯度下降算法
算法首先使用随机选中的权重值创建一个初始模型,然后计算这个随机初始化模型的SSE。估计的权重值连同相应模型的SSE一起定义了误差曲面上的搜索起始点。初始化的模型大多是不好的模型,但不妨碍搜索开始后沿着误差曲面的梯度向下走直至到达误差曲面的底部,然后就能找到一组最优的权重值。因此该算法称为梯度下降:算法下降的梯度是模型的误差曲面相对于数据的梯度。
迭代更新规则
为实现在误差曲面上向下搜索,我们需要定义一个优化迭代的规则(即我们如何向下走)
以上图两个权重的线性回归模型为例,我们可以计算出初始化位置附近所有的SSE值,借此来判断最优值是否可行?显然可以但不可行,我们既然设计算法来做优化,就不是来暴力遍历的!这个时候我们通过图形找到了一点思路!高数下学过的梯度!通过计算SSE在该点处的梯度值,可以找到最优的下降方向!这时我们解决了三维图形(三维,但是这里指二权重)的梯度下降问题,那么再推而广之出现问题了,四维怎么办?我们无法将其可视化。
我们在求三维图像的梯度时,其实是用到了偏导数的方法,将一个权重当做自变量,其他权重当做常量,这本身就是二维的外推,那么所有维度不是同理嘛?接下来需要一点空间想象能力,所谓三维误差曲面,本质是由多条曲线组成,因此我们能由此升维,那降维也就不难了。组成曲面的每条曲线的梯度(这里说导数/斜率更好理解?)各不相同,这很重要,它使得算法能够通过独立更新每个权重来沿着与该权重对应的误差曲线向下移动,进而实现沿着由多条误差曲线组成的误差曲面向下移动。曲线最优拼接起来就是曲面最优了(这里不考虑局部最优的情况)。
上述权重更新规则表明梯度下降算法可以用于训练单个神经元,但对于直接训练有着多个隐藏层的深度神经网络是不可能的。但反向传播提供了一种解决方案。
反向传播
完整的反向传播过程包含两部分:
-
前向传播:该阶段将输入模式送进网络,得到的神经元激活值在网络中向前传播直至得到输出值,这个过程中会保存每个神经元的输入加权和以及激活值(后续反向传播会使用)
-
反向传播:该阶段首先计算输出层每个神经元的误差梯度(指该神经元的加权和相较于计算结果的变化率),将误差梯度反向传播,得到网络中每个神经元的误差梯度(指网络相对于网络权重变化的误差梯度),使用之前得到的误差梯度和某种权重更新算法,如梯度下降,计算权重的误差梯度,并据此更新网络权重。
了解了过程后我们需要知道的是,梯度误差是如何反向传播的?
答案是:复合函数的链式法则
本质上就是求出隐藏层中神经元的加权和相较于输出层神经元加权和的敏感性,更通俗来说,就是该隐藏层中神经元权重对最终输出的影响程度。
这里很重要的一个概念是敏感性,这里引用John D.Kelleher的话来强调其意义
对网络每个权重的更新应该与网络总体误差相对于该权重变化的敏感性成正比,这是反向传播算法调整网络权重的基本原则
网络误差对单个权重变化的敏感度用网络误差相对于该权重的变化率来衡量。
因此我们可以说,反向传播通过链式法则求导,得出一个敏感性,通过敏感性能反馈给当前隐藏层神经元一个label(即最终的label与敏感性的乘积),label有了,加权和也有了,那么通过梯度下降,一个合适的权重就能计算出来。
其实讲到这里还是不能很好地理解BP算法,因此还是引入一些博客与视频资料来辅助理解:
以上内容为初学深度学习留下笔记,大部分内容来自书籍《人人可懂的深度学习》——Jhon D.Kelleher,少部分来自网络
对于本文有不足的细节部分可找来该书查看(小白可懂,非常好的一本入门书籍)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号