
Kubernetes网络之Calico
https://www.projectcalico.org/
故障:
Warning Unhealthy 4m36s kubelet Readiness probe failed: 2021-05-06 06:23:16.868 [INFO][135] confd/health.go 180: Number of node(s) with BGP peering established = 0 calico/node is not ready: BIRD is not ready: BGP not established with 172.21.130.168,172.28.17.85 Warning Unhealthy 4m26s kubelet Readiness probe failed: 2021-05-06 06:23:26.885 [INFO][174] confd/health.go 180: Number of node(s) with BGP peering established = 0
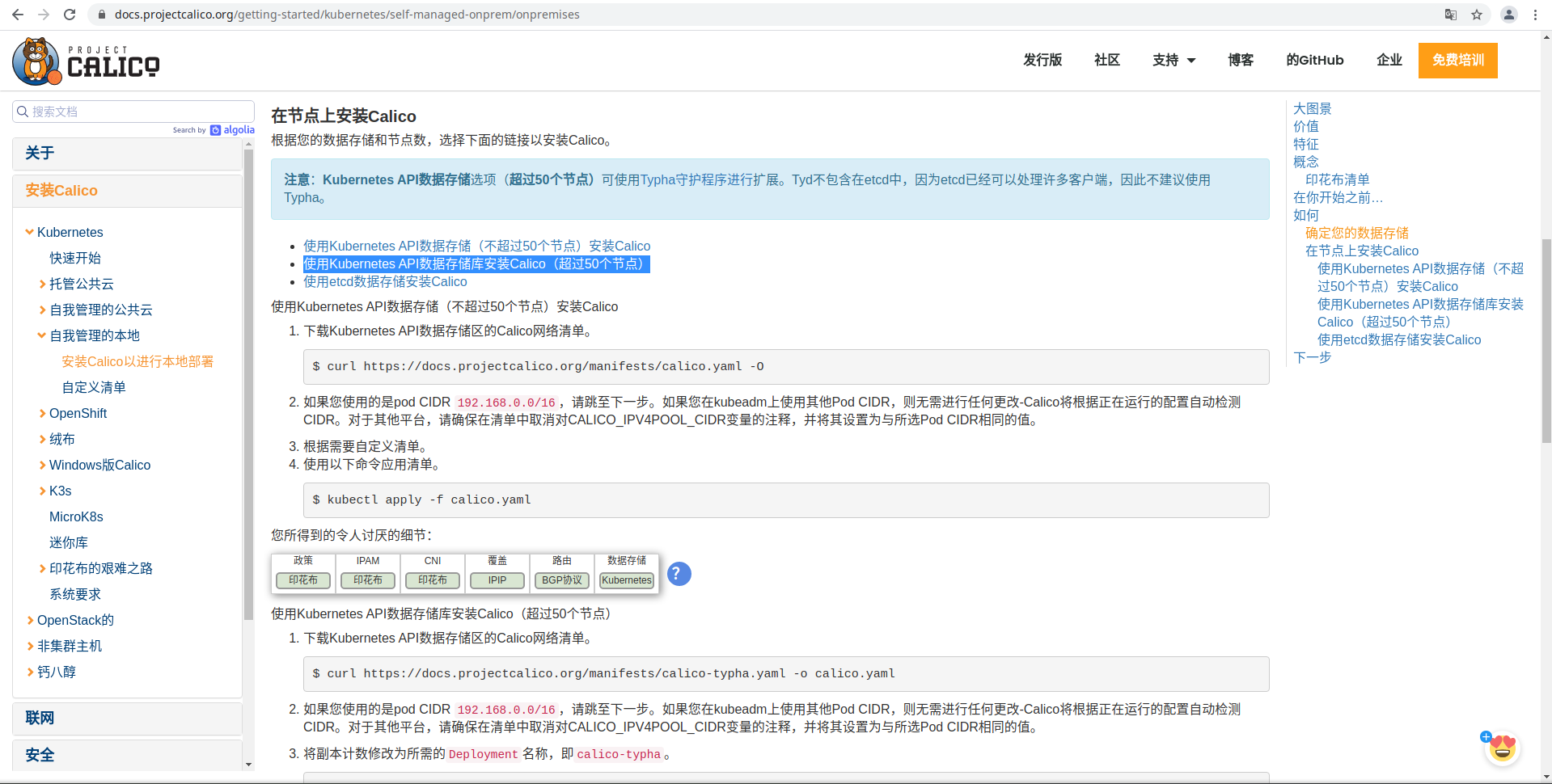
查看节点calico状态
calicoctl node status
修改calico的yaml文件,添加配置项
- name: IP_AUTODETECTION_METHOD value: ""
IP_AUTODETECTION_METHOD 配置项默认为first-found,这种模式中calico会使用第一获取到的有效网卡,虽然会排除docker网络,localhost,但是在复杂网络环境下还是有出错的可能。在这次异常中master上的calico选择了一个非主网卡。
为了解决这种情况,IP_AUTODETECTION_METHOD还提供了两种配置can-reach=DESTINATION,interface=INTERFACE-REGEX。
can-reach=DESTINATION 配置可以理解为calico会从部署节点路由中获取到达目的ip或者域名的源ip地址。
interface=INTERFACE-REGEX 配置可以指定calico使用匹配的网卡上的第一个IP地址。列出网卡和IP地址的顺序取决于系统。匹配支持goalong的正则语法。
cat >> /etc/sysctl.d/k8s.conf < EOF
/etc/sysctl.d/k8s.conf vm.swappiness = 0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
初始化:
kubeadm init \
--apiserver-advertise-address=172.21.130.169 \
--image-repository=registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.5 \
--pod-network-cidr=10.244.0.0/16 \
--service-cidr=10.96.0.0/12 \
--ignore-preflight-errors=all
初始化过程说明:
- [preflight] kubeadm 执行初始化前的检查。
- [kubelet-start] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
- [certificates] 生成相关的各种token和证书
- [kubeconfig] 生成 KubeConfig 文件,kubelet 需要这个文件与 Master 通信
- [control-plane] 安装 Master 组件,会从指定的 Registry 下载组件的 Docker 镜像。
- [bootstraptoken] 生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
- [addons] 安装附加组件 kube-proxy 和 kube-dns。
- Kubernetes Master 初始化成功,提示如何配置常规用户使用kubectl访问集群。
- 提示如何安装 Pod 网络。
- 提示如何注册其他节点到 Cluster。
镜像加速:
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors": ["https://qpu51nc6.mirror.aliyuncs.com"]
}
EOF
故障:

swapoff -a && kubeadm reset && systemctl daemon-reload && systemctl restart kubelet && iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
高可用初始化失败原因之一:
[root@master1 docker]# kubeadm join 172.21.130.200:6443 --token abcdef.0123456789abcdef \ > --discovery-token-ca-cert-hash sha256:299a76c8350a5333f322101230be1aad673822a840eaea7788975ce002c56452 \ > --control-plane --certificate-key 3359262ac1063c05c30aff1b2fb602fb73300871909222538e14ec4345bc3ea5 [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [preflight] Running pre-flight checks before initializing the new control plane instance [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master master1 master2 node1 node2] and IPs [10.0.0.1 172.28.17.85 172.21.130.200 172.21.130.169 172.21.130.168 172.28.17.86 172.28.17.87] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [172.28.17.85 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [172.28.17.85 127.0.0.1 ::1] [certs] Valid certificates and keys now exist in "/etc/kubernetes/pki" [certs] Using the existing "sa" key [kubeconfig] Generating kubeconfig files [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [check-etcd] Checking that the etcd cluster is healthy [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... [kubelet-check] Initial timeout of 40s passed. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused. ^C
如果docker 改了cgroup为systemd,并且Kubernetes利用它作了初始化。那么后加入的节点docker的cgroup一定也要是system,不然就会出上面的问题(cgroup资源限制/资源隔离)不一致导致
[root@master1 docker]# kubeadm reset [reset] Reading configuration from the cluster... [reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' W0510 22:41:17.209172 18233 reset.go:99] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get node registration: failed to get corresponding node: nodes "master1" not found [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted. [reset] Are you sure you want to proceed? [y/N]: y [preflight] Running pre-flight checks W0510 22:41:18.170829 18233 removeetcdmember.go:79] [reset] No kubeadm config, using etcd pod spec to get data directory [reset] No etcd config found. Assuming external etcd [reset] Please, manually reset etcd to prevent further issues [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" [reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki] [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful directories: [/var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni] The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you must do so manually by using the "iptables" command. If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset your system's IPVS tables. The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the contents of the $HOME/.kube/config file. [root@master1 docker]# cat > /etc/docker/daemon.json <<EOF > { > "exec-opts": ["native.cgroupdriver=systemd"], > "log-driver": "json-file", > "log-opts": { > "max-size": "100m" > }, > "storage-driver": "overlay2", > "registry-mirrors":[ > "https://kfwkfulq.mirror.aliyuncs.com", > "https://2lqq34jg.mirror.aliyuncs.com", > "https://pee6w651.mirror.aliyuncs.com", > "http://hub-mirror.c.163.com", > "https://docker.mirrors.ustc.edu.cn", > "https://registry.docker-cn.com" > ] > } > EOF [root@master1 docker]# [root@master1 docker]# [root@master1 docker]# # Restart docker. [root@master1 docker]# systemctl daemon-reload [root@master1 docker]# systemctl restart docker [root@master1 docker]# kubeadm join 172.21.130.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:299a76c8350a5333f322101230be1aad673822a840eaea7788975ce002c56452 --control-plane --certificate-key 3359262ac1063c05c30aff1b2fb602fb73300871909222538e14ec4345bc3ea5 [preflight] Running pre-flight checks [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [preflight] Running pre-flight checks before initializing the new control plane instance [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [download-certs] Downloading the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master master1 master2 node1 node2] and IPs [10.0.0.1 172.28.17.85 172.21.130.200 172.21.130.169 172.21.130.168 172.28.17.86 172.28.17.87] [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost master1] and IPs [172.28.17.85 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost master1] and IPs [172.28.17.85 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Valid certificates and keys now exist in "/etc/kubernetes/pki" [certs] Using the existing "sa" key [kubeconfig] Generating kubeconfig files [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [check-etcd] Checking that the etcd cluster is healthy [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... [etcd] Announced new etcd member joining to the existing etcd cluster [etcd] Creating static Pod manifest for "etcd" [etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [mark-control-plane] Marking the node master1 as control-plane by adding the labels "node-role.kubernetes.io/master=''" and "node-role.kubernetes.io/control-plane='' (deprecated)" [mark-control-plane] Marking the node master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] This node has joined the cluster and a new control plane instance was created: * Certificate signing request was sent to apiserver and approval was received. * The Kubelet was informed of the new secure connection details. * Control plane (master) label and taint were applied to the new node. * The Kubernetes control plane instances scaled up. * A new etcd member was added to the local/stacked etcd cluster. To start administering your cluster from this node, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Run 'kubectl get nodes' to see this node join the cluster.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号