

文章转自:http://www.cnblogs.com/adslg/archive/2012/06/23/2559206.html 感谢作者的分享
摘要:本文对B树索引的结构、内部管理等方面做了一个全面的介绍。同时深入探讨了一些与B树索引有关的广为流传的说法,比如删除记录对索引的影响,定期重建索引能解决许多性能问题等。
1.B树索引的相关概念
索引与表一样,也属于段(segment)的一种。里面存放了用户的数据,跟表一样需要占用磁盘空间。只
不过,在索引里的数据存放形式与表里的数据存放形式非常的不一样。在理解索引时,可以想象一本书,其中书的内容就相当于表里的数据,而书前面的目录就相当于该表的索引。同时,通常情况下,索引所占用的磁盘空间要比表要小的多,其主要作用是为了加快对数据的搜索速度,也可以用来保证数据的唯一性。
但是,索引作为一种可选的数据结构,你可以选择为某个表里的创建索引,也可以不创建。这是因为一旦创建了索引,就意味着oracle对表进行DML(包括INSERT、UPDATE、DELETE)时,必须处理额外的工作量(也就是对索引结构的维护)以及存储方面的开销。所以创建索引时,需要考虑创建索引所带来的查询性能方面的提高,与引起的额外的开销相比,是否值得。
从物理上说,索引通常可以分为:分区和非分区索引、常规B树索引、位图(bitmap)索引、翻转(reverse)索引等。其中,B树索引属于最常见的索引,由于我们的这篇文章主要就是对B树索引所做的探讨,因此下面只要说到索引,都是指B树索引。
B树索引是一个典型的树结构,其包含的组件主要是:
1) 叶子节点(Leaf node):包含条目直接指向表里的数据行。
2) 分支节点(Branch node):包含的条目指向索引里其他的分支节点或者是叶子节点。
3) 根节点(Root node):一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。
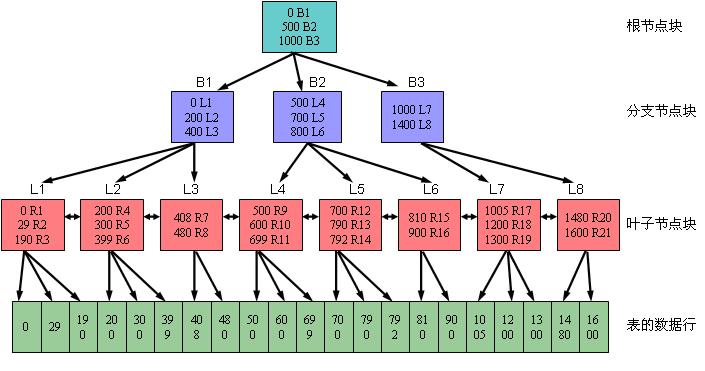
对于分支节点块(包括根节点块)来说,其所包含的索引条目都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)都具有两个字段。第一个字段表示当前该分支节点块下面所链接的索引块中所包含的最小键值;第二个字段为四个字节,表示所链接的索引块的地址,该地址指向下面一个索引块。在一个分支节点块中所能容纳的记录行数由数据块大小以及索引键值的长度决定。比如从上图一可以看到,对于根节点块来说,包含三条记录,分别为(0 B1)、(500 B2)、(1000 B3),它们指向三个分支节点块。其中的0、500和1000分别表示这三个分支节点块所链接的键值的最小值。而B1、B2和B3则表示所指向的三个分支节点块的地址。
对于叶子节点块来说,其所包含的索引条目与分支节点一样,都是按照顺序排列的(缺省是升序排列,也可以在创建索引时指定为降序排列)。每个索引条目(也可以叫做每条记录)也具有两个字段。第一个字段表示索引的键值,对于单列索引来说是一个值;而对于多列索引来说则是多个值组合在一起的。第二个字段表示键值所对应的记录行的ROWID,该ROWID是记录行在表里的物理地址。如果索引是创建在非分区表上或者索引是分区表上的本地索引的话,则该ROWID占用6个字节;如果索引是创建在分区表上的全局索引的话,则该ROWID占用10个字节。
知道这些信息以后,我们可以举个例子来说明如何估算每个索引能够包含多少条目,以及对于表来说,所产生的索引大约多大。对于每个索引块来说,缺省的PCTFREE为10%,也就是说最多只能使用其中的90%。同时9i以后,这90%中也不可能用尽,只能使用其中的87%左右。也就是说,8KB的数据块中能够实际用来存放索引数据的空间大约为6488(8192×90%×88%)个字节。
假设我们有一个非分区表,表名为warecountd,其数据行数为130万行。该表中有一个列,列名为goodid,其类型为char(8),那么也就是说该goodid的长度为固定值:8。同时在该列上创建了一个B树索引。
在叶子节点中,每个索引条目都会在数据块中占一行空间。每一行用2到3个字节作为行头,行头用来存放标记以及锁定类型等信息。同时,在第一个表示索引的键值的字段中,每一个索引列都有1个字节表示数据长度,后面则是该列具体的值。那么对于本例来说,在叶子节点中的一行所包含的数据大致如下图二所示:

从上图可以看到,在本例的叶子节点中,一个索引条目占18个字节。同时我们知道8KB的数据块中真正可以用来存放索引条目的空间为6488字节,那么在本例中,一个数据块中大约可以放360(6488/18)个索引条目。而对于我们表中的130万条记录来说,则需要大约3611(1300000/360)个叶子节点块。
而对于分支节点里的一个条目(一行)来说,由于它只需保存所链接的其他索引块的地址即可,而不需要保存具体的数据行在哪里,因此它所占用的空间要比叶子节点要少。分支节点的一行中所存放的所链接的最小键值所需空间与上面所描述的叶子节点相同;而存放的索引块的地址只需要4个字节,比叶子节点中所存放的ROWID少了2个字节,少的这2个字节也就是ROWID中用来描述在数据块中的行号所需的空间。因此,本例中在分支节点中的一行所包含的数据大致如下图三所示:

2. B树索引的内部结构
我们可以使用如下方式将B树索引转储成树状结构的形式而呈现出来:
alter session set events 'immediate trace name treedump level INDEX_OBJECT_ID';
比如,对于上面的例子来说,我们把创建在goodid上的名为idx_warecountd_goodid的索引转储出来。
SQL> select object_id from user_objects where object_name='IDX_WARECOUNTD_GOODID';
OBJECT_ID
----------
7378
SQL> alter session set events 'immediate trace name treedump level 7378';
打开转储出来的文件以后,我们可以看到类似下面的内容:
----- begin tree dump
branch: 0x180eb0a 25225994 (0: nrow: 9, level: 2)
branch: 0x180eca1 25226401 (-1: nrow: 405, level: 1)
leaf: 0x180eb0b 25225995 (-1: nrow: 359 rrow: 359)
leaf: 0x180eb0c 25225996 (0: nrow: 359 rrow: 359)
leaf: 0x180eb0d 25225997 (1: nrow: 359 rrow: 359)
leaf: 0x180eb0e 25225998 (2: nrow: 359 rrow: 359)
…………………
branch: 0x180ee38 25226808 (0: nrow: 406, level: 1)
leaf: 0x180eca0 25226400 (-1: nrow: 359 rrow: 359)
leaf: 0x180eca2 25226402 (0: nrow: 359 rrow: 359)
leaf: 0x180eca3 25226403 (1: nrow: 359 rrow: 359)
leaf: 0x180eca4 25226404 (2: nrow: 359 rrow: 359)
…………………
其中,每一行的第一列表示节点类型:branch表示分支节点(包括根节点),而leaf则表示叶子节点;第二列表示十六进制表示的节点的地址;第三列表示十进制表示的节点的地址;第四列表示相对于前一个节点的位置,根节点从0开始计算,其他分支节点和叶子节点从-1开始计算;第五列的nrow表示当前节点中所含有的索引条目的数量。比如我们可以看到根节点中含有的nrow为9,表示根节点中含有9个索引条目,分别指向9个分支节点;第六列中的level表示分支节点的层级,对于叶子节点来说level都是0。第六列中的rrow表示有效的索引条目(因为索引条目如果被删除,不会立即被清除出索引块中。所以nrow减rrow的数量就表示已经被删除的索引条目数量)的数量,比如对于第一个leaf来说,其rrow为359,也就是说该叶子节点中存放了359个可用索引条目,分别指向表warecountd的359条记录。
上面这种方式以树状形式转储整个索引。同时,我们可以转储一个索引节点来看看其中存放了些什么。转储的方式为:
alter system dump datafile file# block block#;
我们从上面转储结果中的第二行知道,索引的根节点的地址为25225994,因此我们先将其转换为文件号以及数据块号。
SQL> select dbms_utility.data_block_address_file(25225994),
2 dbms_utility.data_block_address_block(25225994) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
6 60170
于是,我们转储根节点的内容。
SQL> alter system dump datafile 6 block 60170;
打开转储出来的跟踪文件,我们可以看到如下的索引头部的内容:
header address 85594180=0x51a1044
kdxcolev 2
KDXCOLEV Flags = - - -
kdxcolok 0
kdxcoopc 0x80: pcode=0: iot flags=--- is converted=Y
kdxconco 2
kdxcosdc 0
kdxconro 8
kdxcofbo 44=0x2c
kdxcofeo 7918=0x1eee
kdxcoavs 7874
kdxbrlmc 25226401=0x180eca1
kdxbrsno 0
kdxbrbksz 8060
其中的kdxcolev表示索引层级号,这里由于我们转储的是根节点,所以其层级号为2。对叶子节点来说该值为0;kdxcolok表示该索引上是否正在发生修改块结构的事务;kdxcoopc表示内部操作代码;kdxconco表示索引条目中列的数量;kdxcosdc表示索引结构发生变化的数量,当你修改表里的某个索引键值时,该值增加;kdxconro表示当前索引节点中索引条目的数量,但是注意,不包括kdxbrlmc指针;kdxcofbo表示当前索引节点中可用空间的起始点相对当前块的位移量;kdxcofeo表示当前索引节点中可用空间的最尾端的相对当前块的位移量;kdxcoavs表示当前索引块中的可用空间总量,也就是用kdxcofeo减去kdxcofbo得到的。kdxbrlmc表示分支节点的地址,该分支节点存放了索引键值小于row#0(在转储文档后半部分显示)所含有的最小值的所有节点信息;kdxbrsno表示最后一个被修改的索引条目号,这里看到是0,表示该索引是新建的索引;kdxbrbksz表示可用数据块的空间大小。实际从这里已经可以看到,即便是PCTFREE设置为0,也不能用足8192字节。
再往下可以看到如下的内容。这部分内容就是在根节点中所记录的索引条目,总共是8个条目。再加上
row#0[8043] dba: 25226808=0x180ee38
col 0; len 8; (8): 31 30 30 30 30 33 39 32
col 1; len 3; (3): 01 40 1a
……
row#7[7918] dba: 25229599=0x180f91f
col 0; len 8; (8): 31 30 30 31 31 32 30 33
col 1; len 4; (4): 01 40 8f a5
kdxbrlmc所指向的第一个分支节点,我们知道该根节点中总共存放了9个分支节点的索引条目,而这正是我们在前面所指出的为了管理3611个叶子节点,我们需要9个分支节点。
每个索引条目都指向一个分支节点。其中col 1表示所链接的分支节点的地址,该值经过一定的转换以后实际就是row#所在行的dba的值。如果根节点下没有其他的分支节点,则col 1为TERM;col 0表示该分支节点所链接的最小键值。其转换方式非常复杂,比如对于row #0来说,col 0为31 30 30 30 30 30 30 33,则将其中每对值都使用函数to_number(NN,’XX’)的方式从十六进制转换为十进制,于是我们得到转换后的值:49,48,48,48,48,48,48,51,因为我们已经知道索引键值是char类型的,所以对每个值都运用chr函数就可以得到被索引键值为:10000003。实际上,对10000003运用dump函数得到的结果就是:49,48,48,48,48,48,48,51。所以我们也就知道,10000003就是dba为25226808的索引块所链接的最小键值。
SQL> select dump('10000003') from dual;
DUMP('10000003')
-------------------------------------
Typ=96 Len=8: 49,48,48,48,48,48,48,50
接下来,我们从根节点中随便找一个分支节点,假设就是row#0所描述的25226808。对其运用前面所介绍过的dbms_utility里的存储过程获得其文件号和数据块号,并对该数据块进行转储,其内容如下所示。可以
row#0[8043] dba: 25226402=0x180eca2
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 3; (3): 01 40 2e
………
row#404[853] dba: 25226806=0x180ee36
col 0; len 8; (8): 31 30 30 30 31 36 34 30
col 1; len 3; (3): 01 40 09
----- end of branch block dump -----
发现内容与根节点完全类似,只不过该索引块中所包含的索引条目(指向叶子节点)的数量更多了,为405个。这也与我们前面所说的一个分支索引块可以存放大约405(6488/16)个索引条目完全一致。
然后,我们从中随便挑一个叶子节点,对其进行转储。假设就选row#0行所指向的叶子节点,根据dba的值:25226402可以知道,文件号为6,数据块号为60578。将其转储以后,其内容如下所示,我只显示与分支节点不同的部分。
………
kdxlespl 0
kdxlende 0
kdxlenxt 25226403=0x180eca3
kdxleprv 25226400=0x180eca0
kdxledsz 0
kdxlebksz 8036
其中的kdxlespl表示当叶子节点被拆分时未提交的事务数量;kdxlende表示被删除的索引条目的数量;kdxlenxt表示当前叶子节点的下一个叶子节点的地址;kdxlprv表示当前叶子节点的上一个叶子节点的地址;kdxledsz表示可用空间,目前是0。
转储文件中接下来的部分就是索引条目部分,每个条目包含一个ROWID,指向一个表里的数据行。如下所示。其中flag表示标记,比如删除标记等;而lock表示锁定信息。col 0表示索引键值,其算法与我们在前面介绍分支节点时所说的算法一致。col 1表示ROWID。我们同样可以看到,该叶子节点中包含了359个索引条目,与我们前面所估计的一个叶子节点中大约可以放360个索引条目也是基本一致的。
row#0[8018] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 6; (6): 01 40 2e 93 00 16
row#1[8000] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 33
col 1; len 6; (6): 01 40 2e e7 00 0e
…………
row#358[1574] flag: -----, lock: 0
col 0; len 8; (8): 31 30 30 30 30 33 39 37
col 1; len 6; (6): 01 40 18 ba 00 1f
----- end of leaf block dump -----
3. B树索引的访问
我们已经知道了B树索引的体系结构,那么当oracle需要访问索引里的某个索引条目时,oracle是如何找
到该索引条目所在的数据块的呢?
当oracle进程需要访问数据文件里的数据块时,oracle会有两种类型的I/O操作方式:
1) 随机访问,每次读取一个数据块(通过等待事件“db file sequential read”体现出来)。
2) 顺序访问,每次读取多个数据块(通过等待事件“db file scattered read”体现出来)。
第一种方式则是访问索引里的数据块,而第二种方式的I/O操作属于全表扫描。这里顺带有一个问题,为
何随机访问会对应到db file sequential read等待事件,而顺序访问则会对应到db file scattered read等待事件呢?这似乎反过来了,随机访问才应该是分散(scattered)的,而顺序访问才应该是顺序(sequential)的。其实,等待事件主要根据实际获取物理I/O块的方式来命名的,而不是根据其在I/O子系统的逻辑方式来命名的。下面对于如何获取索引数据块的方式中会对此进行说明。
我们看到前面对B树索引的体系结构的描述,可以知道其为一个树状的立体结构。其对应到数据文件里的
排列当然还是一个平面的形式,也就是像下面这样。因此,当oracle需要访问某个索引块的时候,势必会在这个结构上跳跃的移动。
/根/分支/分支/叶子/…/叶子/分支/叶子/叶子/…/叶子/分支/叶子/叶子/…/叶子/分支/.....
当oracle需要获得一个索引块时,首先从根节点开始,根据所要查找的键值,从而知道其所在的下一层的分支节点,然后访问下一层的分支节点,再次同样根据键值访问再下一层的分支节点,如此这般,最终访问到最底层的叶子节点。可以看出,其获得物理I/O块时,是一个接着一个,按照顺序,串行进行的。在获得最终物理块的过程中,我们不能同时读取多个块,因为我们在没有获得当前块的时候是不知道接下来应该访问哪个块的。因此,在索引上访问数据块时,会对应到db file sequential read等待事件,其根源在于我们是按照顺序从一个索引块跳到另一个索引块,从而找到最终的索引块的。
那么对于全表扫描来说,则不存在访问下一个块之前需要先访问上一个块的情况。全表扫描时,oracle知道要访问所有的数据块,因此唯一的问题就是尽可能高效的访问这些数据块。因此,这时oracle可以采用同步的方式,分几批,同时获取多个数据块。这几批的数据块在物理上可能是分散在表里的,因此其对应到db file scattered read等待事件。
4. B树索引的管理机制
4.1 B树索引的对于插入(INSERT)的管理
对于B树索引的插入情况的描述,可以分为两种情况:一种是在一个已经充满了数据的表上创建索引时,
索引是怎么管理的;另一种则是当一行接着一行向表里插入或更新或删除数据时,索引是怎么管理的。
对于第一种情况来说,比较简单。当在一个充满了数据的表上创建索引(create index命令)时,oracle会先扫描表里的数据并对其进行排序,然后生成叶子节点。生成所有的叶子节点以后,根据叶子节点的数量生成若干层级的分支节点,最后生成根节点。这个过程是很清晰的。
但是对于第二种情况来说,会复杂很多。我们结合一个例子来说明。为了方便起见,我们在一个数据块为2KB的表空间上创建一个测试表,并为该表创建一个索引,该索引同样位于2KB的表空间上。
SQL> create table index_test(id char(150)) tablespace tbs_2k;
SQL> create index idx_test on index_test(id) tablespace tbs_2k;
当一开始在一个空的表上创建索引的时候,该索引没有根节点,只有一个叶子节点。我们以树状形式转储上面的索引idx_test。
SQL> select object_id from user_objects where object_name='IDX_TEST';
OBJECT_ID
----------
7390
SQL> alter session set events 'immediate trace name treedump level 7390';
从转储文件可以看到,该索引中只有一个叶子节点(leaf)。
----- begin tree dump
leaf: 0x1c001a2 29360546 (0: nrow: 0 rrow: 0)
----- end tree dump
随着数据不断被插入表里,该叶子节点中的索引条目也不断增加,当该叶子节点充满了索引条目而不能再放下新的索引条目时,该索引就必须扩张,必须再获取一个可用的叶子节点。这时,索引就包含了两个叶子节点,但是两个叶子节点不可能单独存在的,这时它们两必须有一个上级的分支节点,其实这也就是根节点了。于是,现在,我们的索引应该具有3个索引块,一个根节点,两个叶子节点。
我们来做个试验看看这个过程。我们先试着插入插入10条记录。注意,对于2KB的索引块同时PCTFREE为缺省的10%来说,只能使用其中大约1623字节(2048×90%×88%)。对于表index_test来说,叶子节点中的每个索引条目所占的空间大约为161个字节(3个字节行头+1个字节列长+150个字节列本身+1个字节列长+6个字节ROWID),那么当我们插入将10条记录以后,将消耗掉大约1610个字节。
SQL> begin
2 for i in 1..10 loop
3 insert into index_test values (rpad(to_char(i*2),150,'a'));
4 end loop;
5 end;
6 /
SQL> commit;
SQL> select file_id,block_id,blocks from dba_extents where segment_name='IDX_TEST';
FILE_ID BLOCK_ID BLOCKS
---------- ---------- ----------
7 417 32
SQL> alter system dump datafile 7 block 418; --因为第一个块为块头,不含数据,所以转储第二个块。
打开跟踪文件以后,如下所示,可以发现418块仍然是一个叶子节点,包含10个索引条目,该索引块还没有被拆分。注意其中的kdxcoavs为226,说明可用空间还剩226个字节,说明还可以插入一条记录。之所以与前面计算出来的只能放10条记录有出入,是因为可用的1623字节只是一个估计值。
……
kdxcoavs 226
……
row#0[1087] flag: -----, lock: 0
col 0; len 150; (150):
31 30 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
col 1; len 6; (6): 01 c0 01 82 00 04
row#1[926] flag: -----, lock: 0
……
接下来,我们再次插入一条记录,以便基本充满该叶子节点,使得剩下的可用空间不足以再插入一条新的条目。如下所示。
SQL> insert into index_test values(rpad(to_char(11*2),150,'a'));
这个时候我们再次转储418块以后会发现与前面转储的内容基本一致,只是又增加了一个索引条目。而这个时候,如果向表里再次插入一条新的记录的话,该叶子节点(418块)必须进行拆分。
SQL> insert into index_test values(rpad(to_char(12*2),150,'a'));
SQL> alter system dump datafile 7 block 418;
转储出418块以后,我们会发现,该索引块从叶子节点变成了根节点(kdxcolev为1,同时row#0部分的col 1为TERM表示根节点下没有其他分支节点)。这也就说明,当第一个叶子节点充满以后,进行分裂时,先获得两个可用的索引块作为新的叶子节点,然后将当前该叶子节点里所有的索引条目拷贝到这两个新获得的叶子节点,最后将原来的叶子节点改变为根节点。
……
kdxcolev 1
……
kdxbrlmc 29360547=0x1c001a3
……
row#0[1909] dba: 29360548=0x1c001a4
col 0; len 1; (1): 34
col 1; TERM
----- end of branch block dump -----
同时,从上面的kdxbrlmc和row#0中的dba可以知道,该根节点分别指向29360547和29360548两个叶子节点。我们分别对这两个叶子节点进行转储看看里面放了些什么。
SQL> select dbms_utility.data_block_address_file(29360547),
2 dbms_utility.data_block_address_block(29360547) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
7 419
SQL> select dbms_utility.data_block_address_file(29360548),
2 dbms_utility.data_block_address_block(29360548) from dual;
DBMS_UTILITY.DATA_BLOCK_ADDRES DBMS_UTILITY.DATA_BLOCK_ADDRES
------------------------------ ------------------------------
7 420
SQL> alter system dump datafile 7 block 419;
SQL> alter system dump datafile 7 block 420;
在打开跟踪文件之前,我们先来看看表index_test里存放了哪些数据。
SQL> select substr(id,1,2) from index_test order by substr(id,1,2);
SUBSTR(ID,1,2)
--------------
10
12
14
16
18
20
22
24
2a
4a
6a
8a
打开419块的跟踪文件可以发现,里面存放了10、12、14、16、18、20、22、24和2a;而420块的跟踪文件中记录了4a、6a和8a。也就是说,由于最后我们插入24的缘故,导致整个叶子节点发生分裂,从而将10、12、14、16、18、20、22、和2a放到419块里,而4a、6a和8a则放入420块里。然后,再将新的索引条目(24)插入对应的索引块里,也就是419块。
假如我们再最后不是插入12*2,而是插入9会怎么样?我们重新测试一下,返回到index_test里有11条记录的情况下,然后我们再插入9。
SQL> insert into index_test values (rpad('9',150,'a'));
这个时候,418块还是和原来一样变成了根节点,同时仍然生成出了2个叶子节点块,分别是419和420。但是有趣的是,419块里的内容与在插入9之前的叶子节点(当时的418块)的内容完全相同,而420块里则只有一个索引条目,也就是新插入的9。这也就是说,由于最后我们插入9的缘故,导致整个叶子节点发生分裂。但是分裂过程与插入12*2的情况是不一样的,这时该叶子节点的内容不进行拆分,而是直接完全拷贝到一个新的叶子节点(419)里,然后将新插入的9放入另外一个新的叶子节点(420)。我们应该注意到,插入的这个9表里所有记录里的最大字符串。
如果这时,我们再次插入12*2,则会发现419号节点的分裂过程和前面描述的一样,会将原来放在419块里的4a、6a和8a放入一个新的叶子节点里(421块),然后将12*2放入419块,于是这个时候419块所含有的索引条目为10、12、14、16、18、20、22、和2a。同时420块没有发生变化。
根据上面的测试结果,我们可以总结一下叶子节点的拆分过程。这个过程需要分成两种情况,一种是插入的键值不是最大值;另一种是插入的键值是最大值。
对于第一种情况来说,当一个非最大键值要进入索引,但是发现所应进入的索引块不足以容纳当前键值时:
1) 从索引可用列表上获得一个新的索引数据块。
2) 将当前充满了的索引中的索引条目分成两部分,一部分是具有较小键值的,另一部分是具有较大键值的。Oracle会将具有较大键值的部分移入新的索引数据块,而较小键值的部分保持不动。
3) 将当前键值插入合适的索引块中,可能是原来空间不足的索引块,也可能是新的索引块。
4) 更新原来空间不足的索引块的kdxlenxt信息,使其指向新的索引块。
5) 更新位于原来空间不足的索引块右边的索引块里的kdxleprv,使其指向新的索引块。
6) 向原来空间不足的索引块的上一级的分支索引块中添加一个索引条目,该索引条目中保存新的索引块里的最小键值,以及新的索引块的地址。
从上面有关叶子节点分裂的过程可以看出,其过程是非常复杂的。因此如果发生的是第二种情况,则为了
简化该分裂过程,oracle省略了上面的第二步,而是直接进入第三步,将新的键值插入新的索引块中。
在上例中,当叶子节点越来越多,导致原来的根节点不足以存放新的索引条目(这些索引条目指向叶子节点)时,则该根节点必须进行分裂。当根节点进行分裂时:
1) 从索引可用列表上获得两个新的索引数据块。
2) 将根节点中的索引条目分成两部分,这两部分分别放入两个新的索引块,从而形成两个新的分支节点。
3) 更新原来的根节点的索引条目,使其分别指向这两个新的索引块。
因此,这时的索引层次就变成了2层。同时可以看出,根节点索引块在物理上始终都是同一个索引块。而
随着数据量的不断增加,导致分支节点又要进行分裂。分支节点的分裂过程与根节点类似(实际上根节点分裂其实是分支节点分裂的一个特例而已):
1) 从索引可用列表上获得一个新的索引数据块。
2) 将当前满了的分支节点里的索引条目分成两部分,较小键值的部分不动,而较大键值的部分移入新的索引块。
3) 将新的索引条目插入合适的分支索引块。
4) 在上层分支索引块中添加一个新的索引条目,使其指向新加的分支索引块。
当数据量再次不断增加,导致原来的根节点不足以存放新的索引条目(这些索引条目指向分支节点)时,
再次引起根节点的分裂,其分裂过程与前面所说的由于叶子节点的增加而导致的根节点分裂的过程是一样的。
同时,根节点分裂以后,索引的层级再次递增。由此可以看出,根据B树索引的分裂机制,一个B树索引始终都是平衡的。注意,这里的平衡是指每个叶子节点与根节点的距离都是相同的。同时,从索引的分裂机制可以看出,当插入的键值始终都是增大的时候,索引总是向右扩展;而当插入的键值始终都是减小的时候,索引则总是向左扩展。
4.2 B树索引的对于删除(DELETE)的管理
上面介绍了有关插入键值时索引的管理机制,那么对于删除键值时会怎么样呢?
在介绍删除索引键值的机制之前,先介绍与索引相关的一个比较重要的视图:index_stats。该视图显示了
大量索引内部的信息,该视图正常情况下没有数据,只有在运行了下面的命令以后才会被填充数据,而且该视图中只能存放一条与分析过的索引相关的记录,不会有第二条记录。同时,也只有运行了该命令的session才能够看到该视图里的数据,其他session不能看到其中的数据。
analyze index INDEX_NAME validate structure;
不过要注意一点,就是该命令有一个坏处,就是在运行过程中,会锁定整个表,从而阻塞其他session对表进行插入、更新和删除等操作。这是因为该命令的主要目的并不是用来填充index_stats视图的,其主要作用在于校验索引中的每个有效的索引条目都对应到表里的一行,同时表里的每一行数据在索引中都存在一个对应的索引条目。为了完成该目的,所以在运行过程中要锁定整个表,同时对于很大的表来说,运行该命令需要耗费非常多的时间。
在视图index_stats中,height表示B树索引的高度;blocks表示分配了的索引块数,包括还没有被使用的;pct_used表示当前索引中被使用了的空间的百分比。其值是通过该视图中的(used_space/btree_space)*100计算而来。used_space表示已经使用的空间,而btree_space表示索引所占的总空间;del_lf_rows表示被删除的记录行数(表里的数据被删除并不会立即将其对应于索引里的索引条目清除出索引块,我们后面会说到);del_lf_rows_len表示被删除的记录所占的总空间;lf_rows表示索引中包含的总记录行数,包括已经被删除的记录行数。这样的话,索引中未被删除的记录行数就是lf_rows-del_lf_rows。同时我们可以计算未被删除的记录所对应的索引条目(也就是有效索引条目)所占用的空间为((used_space – del_lf_rows_len) / btree_space) * 100。
然后,我们还是接着上个例子(最后插入了12*2的例子)来测试一下。这时我们已经知道,该例中的索引具有两个叶子节点,一个叶子节点(块号为419)包含10、12、14、16、18、20、22、24和2a,而另一个叶子节点(块号为420)包含4a、6a和8a。我们插入41、42、43、44、45、46、47和48各8条记录,这时可以知道这8条记录所对应的索引条目将会进入索引块420中,从而该块420被充满。
SQL> begin
2 for i in 1..8 loop
3 insert into index_test values (rpad('4'||to_char(i),150,'a'));
4 end loop;
5 end;
6 /
我们先分析索引从而填充index_stats视图。
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
20 0 0 3269 5600
从上面视图可以看到,当前索引共20条记录,没有被删除的记录,共使用了3269个字节。
然后我们删除位于索引块419里的索引条目,包括10、12、14、16各4条记录。
SQL> delete index_test where substr(id,1,2) in('10','12','14','16');
SQL> commit;
SQL> alter system dump datafile 7 block 419;
打开转储出来的文件可以发现如下的内容(我们节选了部分关键内容)。可以发现,kdxconro为3,说明该索引节点里还有9个索引条目。所以说,虽然表里的数据被删除了,但是对应的索引条目并没有被删除,只是在各个索引条目上(row#一行中的flag为D)做了一个D的标记,表示该索引条目被delete了。
kdxconro 9
row#0[443] flag: ---D-, lock: 2
row#1[604] flag: ---D-, lock: 2
row#2[765] flag: ---D-, lock: 2
row#3[926] flag: ---D-, lock: 2
然后,我们再以树状结构转储索引,打开树状转储跟踪文件可以看到如下内容。可以知道,块419里包含9个索引条目(nrow为9),而有效索引条目只有5个(rrow为5),那么被删除了的索引条目就是4个(9减5)。
SQL> alter session set events 'immediate trace name treedump level 7390';
----- begin tree dump
branch: 0x1c001a2 29360546 (0: nrow: 2, level: 1)
leaf: 0x1c001a3 29360547 (-1: nrow: 9 rrow: 5)
leaf: 0x1c001a4 29360548 (0: nrow: 11 rrow: 11)
----- end tree dump
这时,我们再次分析索引,填充index_stats视图。
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
20 4 652 3269 5600
对照删除之前视图里的信息,很明显看到,当前索引仍然为20条记录,但是其中有4条为删除的,但是索引所使用的空间并没有释放被删除记录所占用的652个字节,仍然为删除之前的3269个字节。这也与转储出来的索引块的信息一致。
接下来,我们测试这个时候插入一条记录时,索引会怎么变化。分三种情况进行插入:第一种是插入一个属于原来被删除键值范围内的值,比如13,观察其会如何进入包含设置了删除标记的索引块;第二种是插入原来被删除的键值中的一个,比如16,观察其是否能够重新使用原来的索引条目;第三种是插入一个完全不属于该表中已有记录的范围的值,比如rpad('M',150,'M'),观察其对块419以及420会产生什么影响。
我们测试第一种情况:
SQL> insert into index_test values (rpad(to_char(13),150,'a'));
SQL> alter system dump datafile 7 block 419;
打开跟踪文件以后会发现419块里的内容发生了变化,如下所示。我们可以发现一个很有趣的现象,从kdxconro为6说明插入了键值13以后,导致原来四个被标记为删除的索引条目都被清除出了索引块。同时,我们也确实发现原来标记为D的四个索引条目都消失了。
……
kdxconro 6
……
kdxlende 0
……
row#0[121] flag: -----, lock: 2 被插入13
col 0; len 150; (150):
31 33 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61 61
……
我们分析索引,看看index_stats视图会如何变化。
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
17 0 0 2780 5600
很明显,原来的del_lf_rows从4变为了0,同时used_space也从原来的3269变成了2780。表示原来被删除的索引条目所占用的空间已经释放了。
我们继续测试第二种情况:
SQL> insert into index_test values (rpad(to_char(8*2),150,'a'));
SQL> alter system dump datafile 7 block 419;
打开跟踪文件以后,发现对于插入已经被标记为删除的记录来说,其过程与插入属于该索引块索引范围的键值的过程没有区别。甚至你会发现,被插入的16的键值所处的位置与插入的13的键值所在的位置完全一样(row#0[121]里的121表示在索引块中的位置)。也就是说,oracle并没有重用原来为16的键值,而是直接将所有标记为D的索引条目清除出索引块,然后插入新的键值为16的索引条目。
对于第三种情况,我们已经可以根据前面有关第一、第二种情况做出预测,由于420块已经被充满,同时所插入的键值是整个表里的最大值,因此也不会因此420号块的分裂,而是直接获取一个新的索引块来存放该键值。但是419号块里标记为D的索引条目是否能被清除出索引块呢?
SQL> insert into index_test values (rpad('M',150,'M'));
SQL> alter system dump datafile 7 block 419;
SQL> alter system dump datafile 7 block 420;
SQL> alter system dump datafile 7 block 421;
打开跟踪文件,可以清楚的看到,419号块里的标记为D的4各索引条目仍然保留在索引块里,同时420号块里的内容没有任何变化,而421号块里则存放了新的键值:rpad('M',150,'M')。
我们看看index_stats视图会如何变化。其结果也符合我们从转储文件中所看到的内容。
SQL> analyze index idx_test validate structure;
SQL> select LF_ROWS,DEL_LF_ROWS,DEL_LF_ROWS_LEN,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS DEL_LF_ROWS DEL_LF_ROWS_LEN USED_SPACE BTREE_SPACE
---------- ----------- --------------- ---------- -----------
21 4 652 3441 7456
既然当插入rpad('M',150,'M')时对419号块没有任何影响,不会将标记为D的索引条目移出索引块。那么如果我们事先将419号索引块中所有的索引条目都标记为D,也就是说删除419号索引块中索引条目所对应的记录,然后再次插入rpad('M',150,'M')时会发生什么?通过测试,我们可以发现,再次插入一个最大值以后,该最大值会进入块421里,但是块419里的索引条目则会被全部清除,变成了一个空的索引数据块。这也就是我们通常所说的,当索引块里的索引条目全部被设置为D(删除)标记时,再次插入任何一个索引键值都会引起该索引块里的内容被清除。
最后,我们来测试一下,当索引块里的索引条目全部被设置为D(删除)标记以后,再次插入新的键值时会如何重用这些索引块。我们先创建一个测试表,并插入10000条记录。
SQL> create table delete_test(id number);
SQL> begin
2 for i in 1..10000 loop
3 insert into delete_test values (i);
4 end loop;
5 commit;
6 end;
7 /
SQL> create index idx_delete_test on delete_test(id);
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
10000 21 0 150021 176032
可以看到,该索引具有21个叶子节点。然后我们删除前9990条记录。从而使得21个叶子节点中只有最后一个叶子节点具有有效索引条目,前20个叶子节点里的索引条目全都标记为D(删除)标记。
SQL> delete delete_test where id >= 1 and id <= 9990;
SQL> commit;
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
10000 21 9990 150021 176032
最后,我们插入从20000开始到30000结束,共10000条与被删除记录完全不重叠的记录。
SQL> begin
2 for i in 20000..30000 loop
3 insert into delete_test values (i);
4 end loop;
5 commit;
6 end;
7 /
SQL> analyze index idx_delete_test validate structure;
SQL> select LF_ROWS,LF_BLKS,DEL_LF_ROWS,USED_SPACE,BTREE_SPACE from index_stats;
LF_ROWS LF_BLKS DEL_LF_ROWS USED_SPACE BTREE_SPACE
---------- ---------- ----------- ---------- -----------
10011 21 0 160302 176032
很明显的看到,尽管被插入的记录不属于被删除的记录范围,但是只要索引块中所有的索引条目都被删除了(标记为D),该索引就变成可用索引块而能够被新的键值重新利用了。
因此,根据上面我们所做的试验,可以对索引的删除情况总结如下:
1) 当删除表里的一条记录时,其对应于索引里的索引条目并不会被物理的删除,只是做了一个删除标记。
2) 当一个新的索引条目进入一个索引叶子节点的时候,oracle会检查该叶子节点里是否存在被标记为删除的索引条目,如果存在,则会将所有具有删除标记的索引条目从该叶子节点里物理的删除。
3) 当一个新的索引条目进入索引时,oracle会将当前所有被清空的叶子节点(该叶子节点中所有的索引条目都被设置为删除标记)收回,从而再次成为可用索引块。
尽管被删除的索引条目所占用的空间大部分情况下都能够被重用,但仍然存在一些情况可能导致索引空间
被浪费,并造成索引数据块很多但是索引条目很少的后果,这时该索引可以认为出现碎片。而导致索引出现碎片的情况主要包括:
1) 不合理的、较高的PCTFREE。很明显,这将导致索引块的可用空间减少。
2) 索引键值持续增加(比如采用sequence生成序列号的键值),同时对索引键值按照顺序连续删除,这时可能导致索引碎片的发生。因为前面我们知道,某个索引块中删除了部分的索引条目,只有当有键值进入该索引块时才能将空间收回。而持续增加的索引键值永远只会向插入排在前面的索引块中,因此这种索引里的空间几乎不能收回,而只有其所含的索引条目全部删除时,该索引块才能被重新利用。
3) 经常被删除或更新的键值,以后几乎不再会被插入时,这种情况与上面的情况类似。
对于如何判断索引是否出现碎片,方法非常简单:直接运行ANALYZE INDEX … VALIDATE STRUCTURE
命令,然后检查index_stats视图的pct_used字段,如果该字段过低(低于50%),则说明存在碎片。
4.3 B树索引的对于更新(UPDATE)的管理
而对于值被更新对于索引条目的影响,则可以认为是删除和插入的组合。也就是将被更新的旧值对应的索
引条目设置为D(删除)标记,同时将更新后的值按照顺序插入合适的索引块中。这里就不重复讨论了。
5. 重建B树索引
5.1如何重建B树索引
重建索引有两种方法:一种是最简单的,删除原索引,然后重建;第二种是使用ALTER INDEX … REBUILD
命令对索引进行重建。第二种方式是从oracle 7.3.3版本开始引入的,从而使得用户在重建索引时不必删除原索引再重新CREATE INDEX了。ALTER INDEX … REBUILD相对CREATE INDEX有以下好处:
1) 它使用原索引的叶子节点作为新索引的数据来源。我们知道,原索引的叶子节点的数据块通常都要比表里的数据块要少很多,因此进行的I/O就会减少;同时,由于原索引的叶子节点里的索引条目已经排序了,因此在重建索引的过程中,所做的排序工作也要少的多。
2) 自从oracle 8.1.6以来,ALTER INDEX … REBUILD命令可以添加ONLINE短语。这使得在重建索引的过程中,用户可以继续对原来的索引进行修改,也就是说可以继续对表进行DML操作。
而同时,ALTER INDEX … REBUILD与CREATE INDEX也有很多相同之处:
1) 它们都可以通过添加PARALLEL提示进行并行处理。
2) 它们都可以通过添加NOLOGGING短语,使得重建索引的过程中产生最少的重做条目(redo entry)。
3) 自从oracle 8.1.5以来,它们都可以田间COMPUTE STATISTICS短语,从而在重建索引的过程中,就生成CBO所需要的统计信息,这样就避免了索引创建完毕以后再次运行analyze或dbms_stats来收集统计信息。
当我们重建索引以后,在物理上所能获得的好处就是能够减少索引所占的空间大小(特别是能够减少叶子
节点的数量)。而索引大小减小以后,又能带来以下若干好处:
1) CBO对于索引的使用可能会产生一个较小的成本值,从而在执行计划中选择使用索引。
2) 使用索引扫描的查询扫描的物理索引块会减少,从而提高效率。
3) 由于需要缓存的索引块减少了,从而让出了内存以供其他组件使用。
尽管重建索引具有一定的好处,但是盲目的认为重建索引能够解决很多问题也是不正确的。比如我见过一
个生产系统,每隔一个月就要重建所有的索引(而且我相信,很多生产系统可能都会这么做),其中包括一些100GB的大表。为了完成重建所有的索引,往往需要把这些工作分散到多个晚上进行。事实上,这是一个7×24的系统,仅重建索引一项任务就消耗了非常多的系统资源。但是每隔一段时间就重建索引有意义吗?这里就有一些关于重建索引的很流行的说法,主要包括:
1) 如果索引的层级超过X(X通常是3)级以后需要通过重建索引来降低其级别。
2) 如果经常删除索引键值,则需要定时重建索引来收回这些被删除的空间。
3) 如果索引的clustering_factor很高,则需要重建索引来降低该值。
4) 定期重建索引能够提高性能。
对于第一点来说,我们在前面已经知道,B树索引是一棵在高度上平衡的树,所以重建索引基本不可能降
低其级别,除非是极特殊的情况导致该索引有非常大量的碎片,导致B树索引“虚高”,那么这实际又来到第二点上(因为碎片通常都是由于删除引起的)。实际上,对于第一和第二点,我们应该通过运行ALTER INDEX … REBUILD命令以后检查indest_stats.pct_used字段来判断是否有必要重建索引。
5.2重建B树索引对于clustering_factor的影响
而对于clustering_factor来说,它是用来比较索引的顺序程度与表的杂乱排序程度的一个度量。Oracle在计算某个clustering_factor时,会对每个索引键值查找对应到表的数据,在查找的过程中,会跟踪从一个表的数据块跳转到另外一个数据块的次数(当然,它不可能真的这么做,源代码里只是简单的扫描索引,从而获得ROWID,然后从这些ROWID获得表的数据块的地址)。每一次跳转时,有个计数器就会增加,最终该计数器的值就是clustering_factor。下图四描述了这个原理。
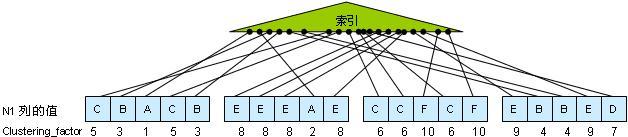
图四
在上图四中,我们有一个表,该表有4个数据块,以及20条记录。在列N1上有一个索引,上图中的每个小黑点就表示一个索引条目。列N1的值如图所示。而N1的索引的叶子节点包含的值为:A、B、C、D、E、F。如果oracle开始扫描索引的底部,叶子节点包含的第一个N1值为A,那么根据该值可以知道对应的ROWID位于第一个数据块的第三行里,所以我们的计数器增加1。同时,A值还对应第二个数据块的第四行,由于跳转到了不同的数据块上,所以计数器再加1。同样的,在处理B时,可以知道对应第一个数据块的第二行,由于我们从第二个数据块跳转到了第一个数据块,所以计数器再加1。同时,B值还对应了第一个数据块的第五行,由于我们这里没有发生跳转,所以计数器不用加1。
在上面的图里,在表的每一行的下面都放了一个数字,它用来显示计数器跳转到该行时对应的值。当我们处理完索引的最后一个值时,我们在数据块上一共跳转了十次,所以该索引的clustering_factor为10。
注意第二个数据块,clustering_factor为8出现了4次。因为在索引里N1为E所对应的4个索引条目都指向了同一个数据块。从而使得clustering_factor不再增长。同样的现象出现在第三个数据块中,它包含三条记录,它们的值都是C,对应的clustering_factor都是6。
从clustering_factor的计算方法上可以看出,我们可以知道它的最小值就等于表所含有的数据块的数量;而最大值就是表所含有的记录的总行数。很明显,clustering_factor越小越好,越小说明通过索引查找表里的数据行时需要访问的表的数据块越少。
我们来看一个例子,来说明重建索引对于减小clustering_factor没有用处。首先我们创建一个测试表:
SQL> create table clustfact_test(id number,name varchar2(10));
SQL> create index idx_clustfact_test on clustfact_test(id);
然后,我们插入十万条记录。
SQL> begin
2 for i in 1..100000 loop
3 insert into clustfact_test values(mod(i,200),to_char(i));
4 end loop;
5 commit;
6 end;
7 /
因为使用了mod的关系,最终数据在表里排列的形式为:
0,1,2,3,4,5,…,197,198,199,0,1,2,3,…, 197,198,199,0,1,2,3,…, 197,198,199,0,1,2,3,…
接下来,我们分析表。
SQL> exec dbms_stats.gather_table_stats(user,'clustfact_test',cascade=>true);
这个时候,我们来看看该索引的clustering_factor。
SQL> select num_rows, blocks from user_tables where table_name = 'CLUSTFACT_TEST';
NUM_ROWS BLOCKS
---------- ----------
100000 202
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
100000 200 1 198 39613
从上面的avg_data_blocks_per_key的值为198可以知道,每个键值平均分布在198个数据块里,而整个表也就202个数据块。这也就是说,要获取某个键值的所有记录,几乎每次都需要访问所有的数据块。从这里已经可以猜测到clustering_factor会非常大。事实上,该值近4万,也说明该索引并不会很有效。
我们来看看下面这句SQL语句的执行计划。
SQL> select count(name) from clufac_test where id = 100;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE (Cost=32 Card=1 Bytes=9)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'CLUFAC_TEST' (Cost=32 Card=500 Bytes=4500)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
205 consistent gets
……
很明显,CBO弃用了索引,而使用了全表扫描。这实际上已经说明由于索引的clustering_factor过高,导致通过索引获取数据时跳转的数据块过多,成本过高,因此直接使用全表扫描的成本会更低。
这时我们来重建索引看看会对clustering_factor产生什么影响。从下面的测试中可以看到,没有任何影响。
SQL> alter index idx_clustfact_test rebuild;
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
100000 200 1 198 39613
那么当我们将表里的数据按照id的顺序(也就是索引的排列顺序)重建时,该SQL语句会如何执行?
SQL> create table clustfact_test_temp as select * from clustfact_test order by id;
SQL> truncate table clustfact_test;
SQL> insert into clustfact_test select * from clustfact_test_temp;
SQL> exec dbms_stats.gather_table_stats(user,'clustfact_test',cascade=>true);
SQL> select num_rows, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key,
2 clustering_factor from user_indexes where index_name = 'IDX_CLUSTFACT_TEST';
NUM_ROWS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR
---------- ------------- ----------------------- ----------------------- -----------------
100000 200 1 1 198
很明显的,这时的索引里每个键值只分布在1个数据块里,同时clustering_factor也已经降低到了198。这时再次执行相同的查询语句时,CBO将会选择索引,同时可以看到consistent gets也从205降到了5。
SQL> select count(name) from clustfact_test where id = 100;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT ptimizer=CHOOSE (Cost=2 Card=1 Bytes=9)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (BY INDEX ROWID) OF 'CLUSTFACT_TEST' (Cost=2 Card=500 Bytes=4500)
3 2 INDEX (RANGE SCAN) OF 'IDX_CLUSTFACT_TEST' (NON-UNIQUE) (Cost=1 Card=500)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
5 consistent gets
……
所以我们可以得出结论,如果仅仅是为了降低索引的clustering_factor而重建索引没有任何意义。降低clustering_factor的关键在于重建表里的数据。只有将表里的数据按照索引列排序以后,才能切实有效的降低clustering_factor。但是如果某个表存在多个索引的时候,需要仔细决定应该选择哪一个索引列来重建表。
5.3重建B树索引对于查询性能的影响
最后我们来看一下重建索引对于性能的提高到底会有什么作用。假设我们有一个表,该表具有1百万条记录,占用了100000个数据块。而在该表上存在一个索引,在重建之前的pct_used为50%,高度为3,分支节点块数为40个,再加一个根节点块,叶子节点数为10000个;重建该索引以后,pct_used为90%,高度为3,分支节点块数下降到20个,再加一个根节点块,而叶子节点数下降到5000个。那么从理论上说:
1) 如果通过索引获取单独1条记录来说:
重建之前的成本:1个根+1个分支+1个叶子+1个表块=4个逻辑读
重建之后的成本:1个根+1个分支+1个叶子+1个表块=4个逻辑读
性能提高百分比:0
2) 如果通过索引获取100条记录(占总记录数的0.01%)来说,分两种情况:
最差的clustering_factor(即该值等于表的数据行数):
重建之前的成本:1个根+1个分支+0.0001*10000(1个叶子)+100个表块=103个逻辑读
重建之后的成本:1个根+1个分支+0.0001*5000(1个叶子)+100个表块=102.5个逻辑读
性能提高百分比:0.5%(也就是减少了0.5个逻辑读)
最好clustering_factor(即该值等于表的数据块):
重建之前的成本:1个根+1个分支+0.0001*10000(1个叶子)+0.0001*100000(10个表块)=13个逻辑读
重建之后的成本:1个根+1个分支+0.0001*5000(1个叶子)+0.0001*100000(10个表块)=12.5个逻辑读
性能提高百分比:3.8%(也就是减少了0.5个逻辑读)
3) 如果通过索引获取10000条记录(占总记录数的1%)来说,分两种情况:
最差的clustering_factor(即该值等于表的数据行数):
重建之前的成本:1个根+1个分支+0.01*10000(100个叶子)+10000个表块=10102个逻辑读
重建之后的成本:1个根+1个分支+0.01*5000(50个叶子)+10000个表块=10052个逻辑读
性能提高百分比:0.5%(也就是减少了50个逻辑读)
最好clustering_factor(即该值等于表的数据块):
重建之前的成本:1个根+1个分支+0.01*10000(100个叶子)+0.01*100000(1000个表块)=1102个逻辑读
重建之后的成本:1个根+1个分支+0.01*5000(50个叶子)+0.01*100000(1000个表块)=1052个逻辑读
性能提高百分比:4.5%(也就是减少了50个逻辑读)
4) 如果通过索引获取100000条记录(占总记录数的10%)来说,分两种情况:
最差的clustering_factor(即该值等于表的数据行数):
重建之前的成本:1个根+1个分支+0.1*10000(1000个叶子)+100000个表块=101002个逻辑读
重建之后的成本:1个根+1个分支+0.1*5000(500个叶子)+100000个表块=100502个逻辑读
性能提高百分比:0.5%(也就是减少了500个逻辑读)
最好clustering_factor(即该值等于表的数据块):
重建之前的成本:1个根+1个分支+0.1*10000(1000个叶子)+0.1*100000(10000个表块)=11002个逻辑读
重建之后的成本:1个根+1个分支+0.1*5000(500个叶子)+0.1*100000(10000个表块)=10502个逻辑读
性能提高百分比:4.5%(也就是减少了500个逻辑读)
5) 对于快速全索引扫描来说,假设每次获取8个数据块:
重建之前的成本:(1个根+40个分支+10000个叶子)/ 8=1256个逻辑读
重建之后的成本:(1个根+40个分支+5000个叶子)/ 8=631个逻辑读
性能提高百分比:49.8%(也就是减少了625个逻辑读)
从上面有关性能提高的理论描述可以看出,对于通过索引获取的记录行数不大的情况下,索引碎片对于性能的影响非常小;当通过索引获取较大的记录行数时,索引碎片的增加可能导致对于索引逻辑读的增加,但是索引读与表读的比例保持不变;同时,我们从中可以看到,clustering_factor对于索引读取的性能有很大的影响,并且对于索引碎片所带来的影响具有很大的作用;最后,看起来,索引碎片似乎对于快速全索引扫描具有最大的影响。
我们来看两个实际的例子,分别是clustering_factor为最好和最差的两个例子。测试环境为8KB的数据块,表空间采用ASSM的管理方式。先做一个最好的clustering_factor的例子,创建测试表并填充1百万条数据。
SQL> create table rebuild_test(id number,name varchar2(10));
SQL> begin
2 for i in 1..1000000 loop
3 insert into rebuild_test values(i,to_char(i));
4 if mod(i,10000)=0 then
5 commit;
6 end if;
7 end loop;
8 end;
9 /
该表具有1百万条记录,分布在2328个数据块中。同时由于我们的数据都是按照顺序递增插入的,所以可以知道,在id列上创建的索引都是具有最好的clustering_factor值的。我们运行以下查询测试语句,分别返回1、100、1000、10000、50000、100000以及1000000条记录。
select * from rebuild_test where id = 10;
select * from rebuild_test where id between 100 and 199;
select * from rebuild_test where id between 1000 and 1999;
select * from rebuild_test where id between 10000 and 19999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 50000 and 99999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 100000 and 199999;
select /*+ index(rebuild_test) */ * from rebuild_test where id between 1 and 1000000;
select /*+ index_ffs(rebuild_test) */ id from rebuild_test where id between 1 and 1000000;
在运行这些测试语句前,先创建一个pctfree为50%的索引,来模拟索引碎片,分析并记录索引信息。
SQL> create index idx_rebuild_test on rebuild_test(id) pctfree 50;
SQL> exec dbms_stats.gather_table_stats(user,'rebuild_test',cascade=>true);
然后运行测试语句,记录每条查询语句所需的时间;接下来以pctfree为10%重建索引,来模拟修复索引碎片,分析并记录索引信息。
SQL> alter index idx_rebuild_test rebuild pctfree 10;
SQL> exec dbms_stats.gather_table_stats(user,'rebuild_test',cascade=>true);
接着再次运行这些测试语句,记录每条查询语句所需的时间。下表显示了两个索引信息的对比情况。
|
pctfree |
Height |
blocks |
br_blks |
lf_blks |
pct_used |
clustering_factor |
|
50% |
3 |
4224 |
8 |
4096 |
49% |
2326 |
|
10% |
3 |
2304 |
5 |
2226 |
90% |
2326 |
下表显示了不同的索引下,运行测试语句所需的时间对比情况。
|
记录数 |
占记录总数的百分比 |
pctused(50%) |
pctused(90%) |
性能提高百分比 |
|
1条记录 |
0.0001% |
0.01 |
0.01 |
0.00% |
|
100条记录 |
0.0100% |
0.01 |
0.01 |
0.00% |
|
1000条记录 |
0.1000% |
0.01 |
0.01 |
0.00% |
|
10000条记录 |
1.0000% |
0.02 |
0.02 |
0.00% |
|
50000条记录 |
5.0000% |
0.06 |
0.06 |
0.00% |
|
100000条记录 |
10.0000% |
1.01 |
1.00 |
0.99% |
|
1000000条记录 |
100.0000% |
13.05 |
11.01 |
15.63% |
|
1000000条记录(FFS) |
100.0000% |
7.05 |
7.02 |
0.43% |
上面是对最好的clustering_factor所做的测试,那么对于最差的clustering_factor会怎么样呢?我们将rebuild_test中的id值反过来排列,也就是说,比如对于id为3478的记录,将id改为8743。这样的话,就将把原来按顺序排列的id值彻底打乱,从而使得id上的索引的clustering_factor变成最差的。为此,我写了一个函数用来反转id的值。
create or replace function get_reverse_value(id in number) return varchar2 is
ls_id varchar2(10);
ls_last_item varchar2(10);
ls_curr_item varchar2(10);
ls_zero varchar2(10);
li_len integer;
lb_stop boolean;
begin
ls_id := to_char(id);
li_len := length(ls_id);
ls_last_item := '';
ls_zero := '';
lb_stop := false;
while li_len>0 loop
ls_curr_item := substr(ls_id,li_len,1);
if ls_curr_item = '0' and lb_stop = false then
ls_zero := ls_zero || ls_curr_item;
else
lb_stop := true;
ls_last_item:=ls_last_item||ls_curr_item;
end if;
ls_id := substr(ls_id,1,li_len-1);
li_len := length(ls_id);
end loop;
return(ls_last_item||ls_zero);
end get_reverse_value;
接下来,我们创建我们第二个测试的测试表。并按照与第一个测试案例相同的方式进行测试。注意,对于测试查询来说,要把表名(包括提示里的)改为rebuild_test_cf。
SQL> create table rebuild_test_cf as select * from rebuild_test;
SQL> update rebuild_test_cf set name=get_reverse_value(id);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号