boltdb 原理
简介
介绍及简单使用:https://www.cnblogs.com/daemon365/p/17690167.html
源码地址:https://github.com/etcd-io/bbolt
page
因为 boltdb 是要落盘的,所以就要操作文件。为了提高效率,boltdb 会和其他数据库一样,会按 页(page)来操作文件。而且 boltdb 使用了 linux 的 mmap 来内存映射操作文件,这样可以提高效率。
在 linux 中,每个 page 的大小是 4KB。
getconf PAGESIZE
4096
对应的每页在我们的代理里也应该有一个数据结构,来存储数据。这个数据结构就是 page。
type Pgid uint64
type Page struct {
id Pgid
flags uint16 // page 类型
count uint16 // page 中的元素数量
overflow uint32 // 是否有后序页,如果有,overflow 表示后续页的数量
}
const (
BranchPageFlag = 0x01
LeafPageFlag = 0x02
MetaPageFlag = 0x04
FreelistPageFlag = 0x10
)
Page 里面有一个 flags 字段,用来标识这个 page 是什么类型的。boltdb 里面有四种类型的 page, 分别是 分支页(BranchPageFlag)、叶子页(LeafPageFlag)、元数据页(MetaPageFlag)、空闲列表页(FreelistPageFlag)。
- 分支页:由于 boltdb 使用的是 B+ 树,所以分支页用来存储 key 和子节点的指针。
- 叶子页:叶子页用来存储 key 和 value。
- 元数据页:元数据页用来存储 boltdb 的元数据,比如 boltdb 的版本号、boltdb 的根节点等。
- 空闲列表页:由于 boltdb 使用 copy on write,所以当一个 page 被删除的时候,boltdb 并不会立即释放这个 page,而是把这个 page 加入到空闲列表页中,等到需要新的 page 的时候,再从空闲列表页中取出一个 page。
在 page 之后会存储对用的结构,比如 meta 或者 freelist。先读取 page 判断自己的结构(定长的:8 + 2 + 2 +4),然后再根据不同的数据类型读取其他的结构(比如BranchPage)。

BranchPage && LeafPage
这两个分别存储 B+ tree 的分支页和叶子页。对应结构为:
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32 // 真实数据对应的偏移量
ksize uint32 // key 的大小
pgid Pgid // 指向 page 的 id
}
// leafPageElement represents a node on a leaf page.
type leafPageElement struct {
flags uint32 // 是否是一个 bucket
pos uint32 // 真实数据对应的偏移量
ksize uint32 // key 的大小
vsize uint32 // value 的大小
}
对应的存储方式为:
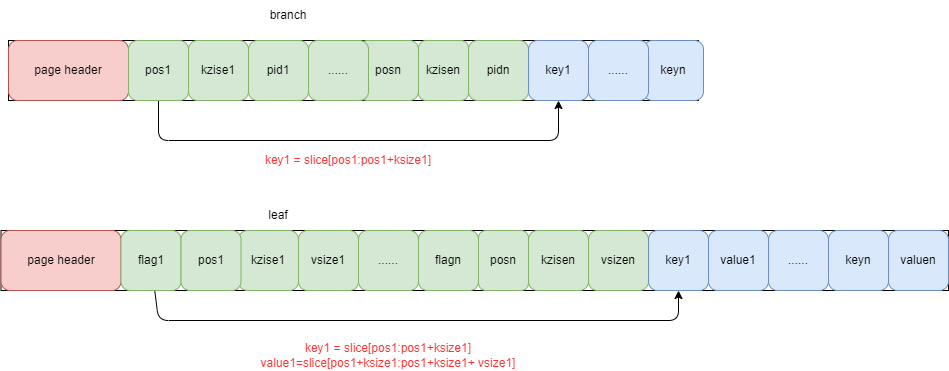
从 page 中拿取数据:
func (p *Page) LeafPageElements() []leafPageElement {
if p.count == 0 {
return nil
}
// 从 page 的指针 加上 page 的大小,就是第一个元素的地址
data := UnsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))
// 转换为 slice
elems := unsafe.Slice((*leafPageElement)(data), int(p.count))
return elems
}
func (p *Page) BranchPageElements() []branchPageElement {
if p.count == 0 {
return nil
}
data := UnsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))
elems := unsafe.Slice((*branchPageElement)(data), int(p.count))
return elems
}
MetaPage
type Meta struct {
magic uint32 // boltdb 的魔数
version uint32 // boltdb 的版本
pageSize uint32 // boltdb 的 page 大小 ,该值和操作系统默认的页大小保持一致
flags uint32
root InBucket // boltdb 的根节点
freelist Pgid // 空闲页的 id
pgid Pgid // 当前 page 的 id
txid Txid // 当前事务的 id
checksum uint64 // 用作校验的校验和
}
它是如何写到 page 中的和从 page 中读取的呢?
// 把 meta 写到 page 中
func (m *Meta) Write(p *Page) {
// 检查 root bucket 的 pgid 是否有效。
// 如果 root.root 的 pgid 大于或等于 m.pgid,这是不合理的,因为这意味着它引用了一个尚未分配的 pgid。
if m.root.root >= m.pgid {
panic(fmt.Sprintf("root bucket pgid (%d) above high water mark (%d)", m.root.root, m.pgid))
// 检查 freelist 的 pgid 是否有效。
// 如果 freelist 的 pgid 大于或等于 m.pgid 且 freelist 不是 PgidNoFreelist,
// 这同样表示它引用了一个尚未分配的 pgid,这是不合理的。
} else if m.freelist >= m.pgid && m.freelist != PgidNoFreelist {
panic(fmt.Sprintf("freelist pgid (%d) above high water mark (%d)", m.freelist, m.pgid))
}
// 指定 pageId 和 page 类型
p.id = Pgid(m.txid % 2)
p.SetFlags(MetaPageFlag)
// 计算校验和
m.checksum = m.Sum64()
m.Copy(p.Meta())
}
// 从 page 中读取 meta
func (p *Page) Meta() *Meta {
return (*Meta)(UnsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p)))
}
// 把 meta 的数据拷贝到 page 中
func (m *Meta) Copy(dest *Meta) {
*dest = *m
}
// 计算校验和
func (m *Meta) Sum64() uint64 {
var h = fnv.New64a()
_, _ = h.Write((*[unsafe.Offsetof(Meta{}.checksum)]byte)(unsafe.Pointer(m))[:])
return h.Sum64()
}
FreelistPage
type freelist struct {
// 表示 freelist 的类型,可能会有不同的策略或实现。
freelistType FreelistType
// 存储所有已释放且可供分配的页面ID。
ids []common.Pgid
// 记录哪个事务ID分配了特定的页面ID。
allocs map[common.Pgid]common.Txid
// 记录即将被释放的页面ID及其所属的事务ID。
pending map[common.Txid]*txPending
// 快速查找所有空闲和待处理页面ID的缓存。
cache map[common.Pgid]struct{}
// 按连续页面大小分类的空闲页面,键是连续页面的大小,值是具有相同大小的起始页面ID的集合。
freemaps map[uint64]pidSet
// 正向映射,键是起始页面ID,值是其span大小。
forwardMap map[common.Pgid]uint64
// 反向映射,键是结束页面ID,值是其span大小。
backwardMap map[common.Pgid]uint64
// 空闲页面的计数(基于哈希图的版本)。
freePagesCount uint64
// 分配函数,根据提供的事务ID和需求的页面数量分配页面。
allocate func(txid common.Txid, n int) common.Pgid
// 返回当前空闲页面数量的函数。
free_count func() int
// 合并连续空闲页面的函数。
mergeSpans func(ids common.Pgids)
// 获取所有空闲页面ID的函数。
getFreePageIDs func() []common.Pgid
// 读取一系列页面ID并初始化 freelist 的函数。
readIDs func(pgids []common.Pgid)
}
// FreelistType 定义了 freelist 后端的类型,用字符串表示不同的实现策略。
type FreelistType string
// 未来的开发计划:
// 1. 默认改为使用 `FreelistMapType`;
// 2. 移除 `FreelistArrayType`,不再公开 `FreelistMapType`,
// 并从 `DB` 和 `Options` 结构体中移除 `FreelistType` 字段。
const (
// FreelistArrayType 表示 freelist 的后端类型为数组。
// 这种类型可能适用于需要按顺序访问空闲页的场景。
FreelistArrayType = FreelistType("array")
// FreelistMapType 表示 freelist 的后端类型为哈希映射。
// 这种类型提供了更快的查找速度,适合于频繁、随机地访问空闲页的情况。
FreelistMapType = FreelistType("hashmap")
)
把 freelist 写到 page 中:
// write 将空闲和待处理的页面ID写入到 freelist 页面。
// 在程序崩溃的事件中,所有待处理的ID都将变成空闲的,因此这些ID都需要被保存到磁盘上。
func (f *freelist) write(p *common.Page) error {
// 设置页头中的页类型标识
p.SetFlags(common.FreelistPageFlag)
// 获取需要保存的 PageID 数量。
l := f.count()
if l == 0 {
// 没有 id 需要保存,直接返回。
p.SetCount(uint16(l))
} else if l < 0xFFFF {
// 如果数量小于 0xFFFF
// 将 id 数量写入到页头中
p.SetCount(uint16(l))
// 计算指针头
data := common.UnsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))
// 开辟一个 slice 用来存储 id
ids := unsafe.Slice((*common.Pgid)(data), l)
// 将 id 拷贝到 page 中
f.copyall(ids)
} else {
// 如果数量大于 0xFFFF ,则需要分多个 page 来保存
// 先设置本页的数量为 0xFFFF
p.SetCount(0xFFFF)
// 计算指针头
data := common.UnsafeAdd(unsafe.Pointer(p), unsafe.Sizeof(*p))
ids := unsafe.Slice((*common.Pgid)(data), l+1)
// 将ID数量存储在第一个元素中
ids[0] = common.Pgid(l)
// 将剩余的 id 拷贝到 page 中
f.copyall(ids[1:])
}
return nil
}
// copyall 将所有空闲的ID和所有待处理的ID复制到一个排序后的列表中。
// f.count 返回目标数组 dst 需要的最小长度。
func (f *freelist) copyall(dst []common.Pgid) {
// 创建一个切片用于存放待处理的ID,容量预设为待处理ID的数量。
m := make(common.Pgids, 0, f.pending_count())
// 遍历所有待处理事务,并将它们的ID加入到切片 m 中。
for _, txp := range f.pending {
m = append(m, txp.ids...)
}
// 对切片 m 进行排序。
sort.Sort(m)
// 将已经空闲的ID和刚排序的待处理ID合并到目标切片 dst 中。
common.Mergepgids(dst, f.getFreePageIDs(), m)
}
// Mergepgids 将两个已排序列表 a 和 b 的并集复制到 dst 中。
// 如果 dst 的长度不足以容纳结果,会触发 panic。
func Mergepgids(dst, a, b Pgids) {
// 检查目标切片 dst 是否足够大以容纳 a 和 b 的所有元素。
if len(dst) < len(a)+len(b) {
panic(fmt.Errorf("mergepgids bad len %d < %d + %d", len(dst), len(a), len(b)))
}
// 如果其中一个列表为空,则直接将另一个列表复制到 dst 中。
if len(a) == 0 {
copy(dst, b)
return
}
if len(b) == 0 {
copy(dst, a)
return
}
// 初始化一个切片 merged 来存储最终合并的结果。
merged := dst[:0]
// 确定哪个列表的起始值更小,并将其设为 lead,另一个设为 follow。
lead, follow := a, b
if b[0] < a[0] {
lead, follow = b, a
}
// 循环合并,直到 lead 为空。
for len(lead) > 0 {
// 合并 lead 中所有小于 follow[0] 的元素。
n := sort.Search(len(lead), func(i int) bool { return lead[i] > follow[0] })
merged = append(merged, lead[:n]...)
if n >= len(lead) {
break
}
// 交换 lead 和 follow,继续合并过程。
lead, follow = follow, lead[n:]
}
// 将剩余的 follow 元素加入到 merged 中。
_ = append(merged, follow...)
}
从 page 中读取 freelist:
// read 从 freelist 页面读取页面ID。
func (f *freelist) read(p *common.Page) {
// 首先检查是否为 freelist 页面,如果不是则抛出错误。
if !p.IsFreelistPage() {
panic(fmt.Sprintf("invalid freelist page: %d, page type is %s", p.Id(), p.Typ()))
}
// 从页面获取 freelist 页面的ID列表。
ids := p.FreelistPageIds()
// 如果获取的ID列表为空,将 f.ids 设置为 nil,表示没有空闲页面。
if len(ids) == 0 {
f.ids = nil
} else {
// 如果ID列表不为空,则创建一个新切片并复制这些ID,以避免直接修改原始页面数据。
idsCopy := make([]common.Pgid, len(ids))
copy(idsCopy, ids)
// 确保复制的ID列表是排序的。
sort.Sort(common.Pgids(idsCopy))
// 将排序后的ID列表读入 freelist 结构。
f.readIDs(idsCopy)
}
}
// hashmapReadIDs 读取输入的 pgids 并初始化 freelist(基于哈希映射的版本)。
func (f *freelist) hashmapReadIDs(pgids []common.Pgid) {
// 初始化 freelist。
f.init(pgids)
// 重建页面缓存。
f.reindex()
}
// reindex 基于可用和待处理的空闲列表重建自由缓存。
func (f *freelist) reindex() {
// 获取所有空闲页面ID。
ids := f.getFreePageIDs()
// 创建一个新的缓存映射。
f.cache = make(map[common.Pgid]struct{}, len(ids))
// 将所有空闲ID添加到缓存中。
for _, id := range ids {
f.cache[id] = struct{}{}
}
// 将所有待处理的空闲ID也添加到缓存中。
for _, txp := range f.pending {
for _, pendingID := range txp.ids {
f.cache[pendingID] = struct{}{}
}
}
}
分配页:
// hashmapAllocate 根据传入的事务ID和请求的页面数量,分配页面。
func (f *freelist) hashmapAllocate(txid common.Txid, n int) common.Pgid {
if n == 0 {
// 如果请求的页面数量为0,则直接返回0,表示没有分配任何页面。
return 0
}
// 检查是否存在完全匹配的空闲span。
if bm, ok := f.freemaps[uint64(n)]; ok {
for pid := range bm {
// 移除这个span。
f.delSpan(pid, uint64(n))
// 记录这个页面ID被哪个事务分配。
f.allocs[pid] = txid
// 从缓存中移除已分配的页面。
for i := common.Pgid(0); i < common.Pgid(n); i++ {
delete(f.cache, pid+i)
}
return pid
}
}
// 在映射中查找大于请求大小的更大span。
for size, bm := range f.freemaps {
if size < uint64(n) {
continue
}
for pid := range bm {
// 移除找到的大span。
f.delSpan(pid, size)
// 记录页面分配。
f.allocs[pid] = txid
// 计算剩余的span大小,并添加回 freelist。
remain := size - uint64(n)
f.addSpan(pid+common.Pgid(n), remain)
// 从缓存中移除已分配的页面。
for i := common.Pgid(0); i < common.Pgid(n); i++ {
delete(f.cache, pid+i)
}
return pid
}
}
return 0
}
// delSpan 从 freelist 中删除一个span。
func (f *freelist) delSpan(start common.Pgid, size uint64) {
// 更新前向和后向映射,移除对应的条目。
delete(f.forwardMap, start)
delete(f.backwardMap, start+common.Pgid(size-1))
// 从 freemaps 中移除span。
delete(f.freemaps[size], start)
if len(f.freemaps[size]) == 0 {
// 如果某个大小的span已经没有其他项,从 freemaps 中完全移除这个大小。
delete(f.freemaps, size)
}
// 更新空闲页面计数。
f.freePagesCount -= size
}
// addSpan 向 freelist 中添加一个新的span。
func (f *freelist) addSpan(start common.Pgid, size uint64) {
// 更新前向和后向映射。
f.backwardMap[start-1+common.Pgid(size)] = size
f.forwardMap[start] = size
// 确保 freemaps 中存在对应大小的映射。
if _, ok := f.freemaps[size]; !ok {
f.freemaps[size] = make(map[common.Pgid]struct{})
}
// 添加新的span到 freemaps。
f.freemaps[size][start] = struct{}{}
// 更新空闲页面计数。
f.freePagesCount += size
}
Node
page 的操作跟多都是基于磁盘设计的,在内存中使用这些数据结构并不是很方便。所以 boltdb 会把 page 的数据结构转换为 node 的数据结构,这样在内存中操作就会方便很多。
type node struct {
bucket *Bucket // bucket 的指针
isLeaf bool // 是否是叶子节点
unbalanced bool // 是否平衡
spilled bool // 是否溢出
key []byte // 该 node 的起始 key
pgid common.Pgid // 该 node 对应的 page id
parent *node // 父节点
children nodes // 子节点
inodes common.Inodes // 存储键值对的结构体数组
}
type Inode struct {
flags uint32 // 用于 leaf node 是否是一个 bucket (subbucket)
pgid Pgid // 用于 branch node, 子节点的 page id
key []byte // key
value []byte // value
}
type Inodes []Inode
page to node
func (n *node) read(p *common.Page) {
n.pgid = p.Id()
n.isLeaf = p.IsLeafPage()
// 读取 inodes
n.inodes = common.ReadInodeFromPage(p)
// 保存第一个键,以便在将节点写入到父节点时能够找到这个节点。
if len(n.inodes) > 0 {
n.key = n.inodes[0].Key()
common.Assert(len(n.key) > 0, "read: zero-length node key")
} else {
n.key = nil
}
}
func ReadInodeFromPage(p *Page) Inodes {
inodes := make(Inodes, int(p.Count()))
isLeaf := p.IsLeafPage()
for i := 0; i < int(p.Count()); i++ {
inode := &inodes[i]
if isLeaf {
// 转换为 leafPageElement 结构
elem := p.LeafPageElement(uint16(i))
inode.SetFlags(elem.Flags())
inode.SetKey(elem.Key())
inode.SetValue(elem.Value())
} else {
// 转换为 branchPageElement 结构
elem := p.BranchPageElement(uint16(i))
inode.SetPgid(elem.Pgid())
inode.SetKey(elem.Key())
}
Assert(len(inode.Key()) > 0, "read: zero-length inode key")
}
return inodes
}
node to page
// write writes the items onto one or more pages.
// The page should have p.id (might be 0 for meta or bucket-inline page) and p.overflow set
// and the rest should be zeroed.
func (n *node) write(p *common.Page) {
common.Assert(p.Count() == 0 && p.Flags() == 0, "node cannot be written into a not empty page")
// Initialize page.
if n.isLeaf {
p.SetFlags(common.LeafPageFlag)
} else {
p.SetFlags(common.BranchPageFlag)
}
if len(n.inodes) >= 0xFFFF {
panic(fmt.Sprintf("inode overflow: %d (pgid=%d)", len(n.inodes), p.Id()))
}
p.SetCount(uint16(len(n.inodes)))
// Stop here if there are no items to write.
if p.Count() == 0 {
return
}
// 将node的inodes写入page
common.WriteInodeToPage(n.inodes, p)
// DEBUG ONLY: n.dump()
}
func WriteInodeToPage(inodes Inodes, p *Page) uint32 {
// 计算写入的初始偏移量。
off := unsafe.Sizeof(*p) + p.PageElementSize()*uintptr(len(inodes))
isLeaf := p.IsLeafPage()
for i, item := range inodes {
Assert(len(item.Key()) > 0, "write: zero-length inode key")
// 创建一个足够大小的切片来存放键和值。
sz := len(item.Key()) + len(item.Value())
b := UnsafeByteSlice(unsafe.Pointer(p), off, 0, sz)
off += uintptr(sz)
// Write the page element.
if isLeaf {
elem := p.LeafPageElement(uint16(i))
elem.SetPos(uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))))
elem.SetFlags(item.Flags())
elem.SetKsize(uint32(len(item.Key())))
elem.SetVsize(uint32(len(item.Value())))
} else {
elem := p.BranchPageElement(uint16(i))
elem.SetPos(uint32(uintptr(unsafe.Pointer(&b[0])) - uintptr(unsafe.Pointer(elem))))
elem.SetKsize(uint32(len(item.Key())))
elem.SetPgid(item.Pgid())
Assert(elem.Pgid() != p.Id(), "write: circular dependency occurred")
}
// 将键和值数据写入到页面的末尾。
l := copy(b, item.Key())
copy(b[l:], item.Value())
}
return uint32(off)
}
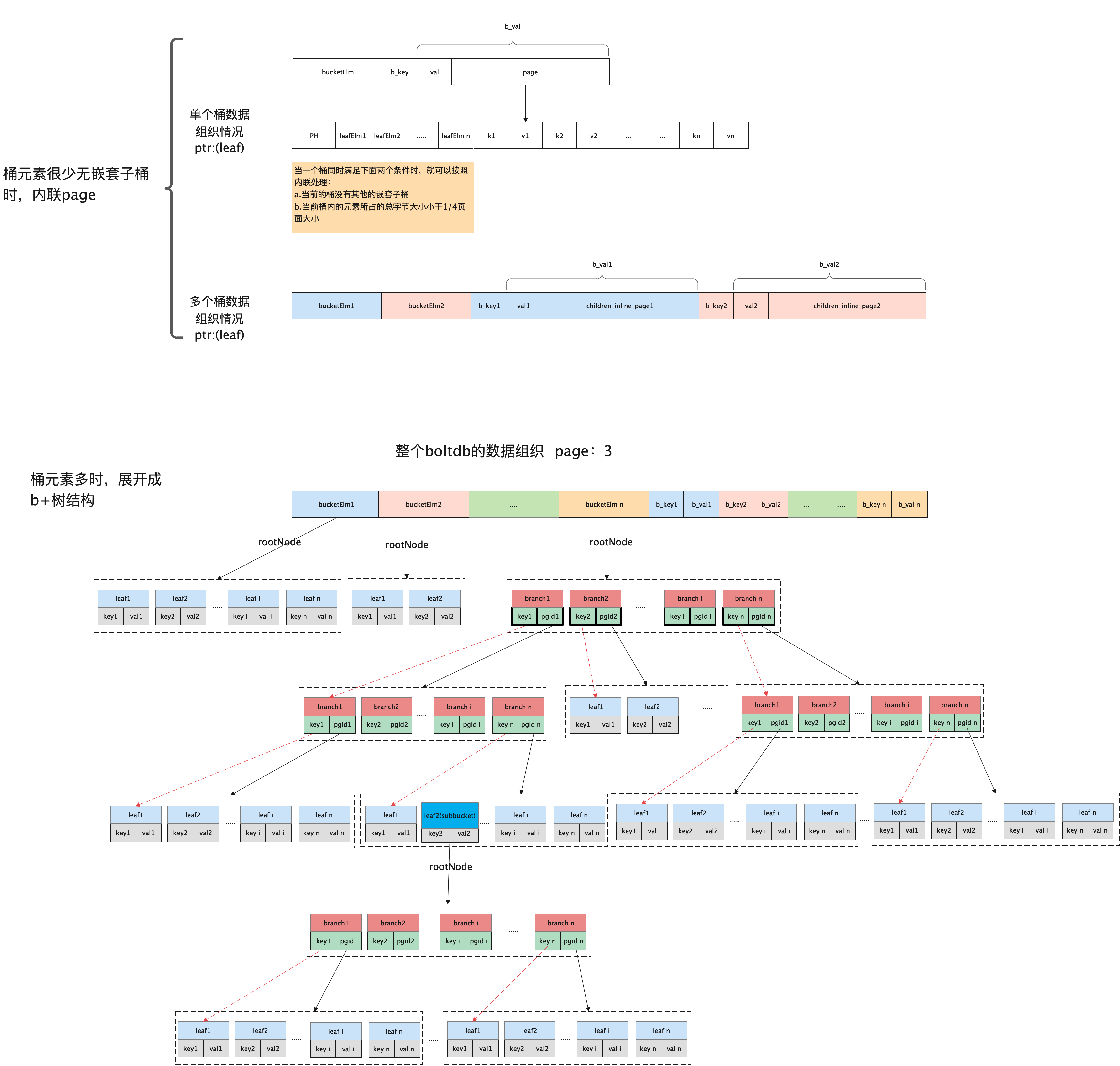
Bucket
Bucket 是 boltdb 的上层的数据结构,每个 bucket 都有一个完成的 B+ 树。将多个 page 联合起来。
type Bucket struct {
*common.InBucket
tx *Tx // 指向关联事务的指针,将 bucket 与其事务上下文连接。
buckets map[string]*Bucket // 子 bucket 缓存;允许通过名字快速访问子 bucket。
page *common.Page // 内联页面的引用,用于直接存储少量数据或作为数据节点的入口点。
rootNode *node // 根页面的已实例化节点,如果 bucket 直接存储在内存中,则此节点将被激活。
nodes map[common.Pgid]*node // 节点缓存,用于快速访问已加载的页面节点,避免重复读取磁盘。
// 设置节点分裂时的填充阈值。默认情况下,bucket 将填充至 50%,
// 但如果你知道你的写入工作负载主要是追加操作,提高这个比例可能会有用。
//
// 这个设置不会跨事务持久化,因此每个事务都必须设置它。
FillPercent float64
}
type InBucket struct {
root Pgid // bucket 根级页面的页面ID。如果 bucket 是内联的,则此值为 0。
sequence uint64 // 单调递增的序列号,用于 NextSequence() 函数。
}
Bucket 有可能是 node,也可能是 page。查找某页面的键值对时,首先检查 Bucket.nodes 缓存是否有对应的 node,如果没有,再从 page 中查找。
Bucket.FillPercent 记录 node 的填充百分比。当 node 的已用空间超过其容量的某个百分比后,节点必须分裂,以减少在 B+ Tree 中插入键值对时触发再平衡的概率。默认值是 50%,仅当大量写入操作在尾部添加时,增大该值才有帮助。
bucket 存储方式:
遍历 cursor
type Cursor struct {
bucket *Bucket
stack []elemRef
}
type elemRef struct {
page *common.Page
node *node
index int
}
cursor 分为三类,定位到某一个元素的位置、在当前位置从前往后找、在当前位置从后往前找。方法为:First、Last、Next、Prev 等。
Seek
如果该键存在,它会返回该键及其对应的值;如果键不存在,它则返回最近的后续键。
// Seek 方法使用B树搜索将光标移动到给定的键并返回它。
// 如果键不存在,则使用下一个键。如果没有更多的键,返回nil。
// 返回的键和值只在事务的生命周期内有效。
func (c *Cursor) Seek(seek []byte) (key []byte, value []byte) {
// 确保数据库事务没有关闭
common.Assert(c.bucket.tx.db != nil, "tx closed")
// 调用内部的seek方法,获取键和值
k, v, flags := c.seek(seek)
// 检查是否位于页面的最后一个元素之后,如果是,则移动到下一个元素。
if ref := &c.stack[len(c.stack)-1]; ref.index >= ref.count() {
k, v, flags = c.next()
}
// 如果k为nil,表示未找到键,返回nil。
if k == nil {
return nil, nil
} else if (flags & uint32(common.BucketLeafFlag)) != 0 {
// 如果是叶子节点,返回键和nil值。
return k, nil
}
// 返回找到的键和值。
return k, v
}
// seek 方法将光标移动到给定的键,并返回该键。
// 如果键不存在,则使用下一个键。
func (c *Cursor) seek(seek []byte) (key []byte, value []byte, flags uint32) {
// 从根页面/节点开始,遍历到正确的页面。
c.stack = c.stack[:0]
c.search(seek, c.bucket.RootPage())
// 如果是桶,则返回nil值。
return c.keyValue()
}
search
// search 方法递归地对给定的页面/节点进行二分搜索,直到找到给定的键。
func (c *Cursor) search(key []byte, pgId common.Pgid) {
p, n := c.bucket.pageNode(pgId)
if p != nil && !p.IsBranchPage() && !p.IsLeafPage() {
panic(fmt.Sprintf("invalid page type: %d: %x", p.Id(), p.Flags()))
}
e := elemRef{page: p, node: n}
c.stack = append(c.stack, e)
// 如果我们位于叶节点页面上,则在该页面内部继续查找特定节点。
if e.isLeaf() {
c.nsearch(key)
return
}
// 如果是节点,继续在节点内部搜索。
if n != nil {
c.searchNode(key, n)
return
}
// 如果是页面,继续在页面内部搜索。
c.searchPage(key, p)
}
func (c *Cursor) searchNode(key []byte, n *node) {
var exact bool
// 使用二分搜索确定键的位置。
index := sort.Search(len(n.inodes), func(i int) bool {
ret := bytes.Compare(n.inodes[i].Key(), key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// 递归搜索到下一页。
c.search(key, n.inodes[index].Pgid())
}
func (c *Cursor) searchPage(key []byte, p *common.Page) {
// 对页面进行二分搜索以确定正确的范围。
inodes := p.BranchPageElements()
var exact bool
index := sort.Search(int(p.Count()), func(i int) bool {
ret := bytes.Compare(inodes[i].Key(), key)
if ret == 0 {
exact = true
}
return ret != -1
})
if !exact && index > 0 {
index--
}
c.stack[len(c.stack)-1].index = index
// 递归搜索到下一页。
c.search(key, inodes[index].Pgid())
}
func (c *Cursor) nsearch(key []byte) {
e := &c.stack[len(c.stack)-1]
p, n := e.page, e.node
// If we have a node then search its inodes.
if n != nil {
index := sort.Search(len(n.inodes), func(i int) bool {
return bytes.Compare(n.inodes[i].Key(), key) != -1
})
e.index = index
return
}
// If we have a page then search its leaf elements.
inodes := p.LeafPageElements()
index := sort.Search(int(p.Count()), func(i int) bool {
return bytes.Compare(inodes[i].Key(), key) != -1
})
e.index = index
}
keyValue
func (c *Cursor) keyValue() ([]byte, []byte, uint32) {
ref := &c.stack[len(c.stack)-1]
// 如果索引超出范围,则返回nil。
if ref.count() == 0 || ref.index >= ref.count() {
return nil, nil, 0
}
// 从node中获取键值对。
if ref.node != nil {
inode := &ref.node.inodes[ref.index]
return inode.Key(), inode.Value(), inode.Flags()
}
// 从 page 中获取键值对。
elem := ref.page.LeafPageElement(uint16(ref.index))
return elem.Key(), elem.Value(), elem.Flags()
}
创建 bucket 如果不存在
// CreateBucketIfNotExists 如果指定的存储桶不存在,则创建它,并返回一个对它的引用。
// 如果存储桶名为空或太长,则返回错误。
// 存储桶实例仅在事务的生命周期内有效。
func (b *Bucket) CreateBucketIfNotExists(key []byte) (rb *Bucket, err error) {
// 如果日志不是被丢弃,记录创建存储桶的尝试。
if lg := b.tx.db.Logger(); lg != discardLogger {
lg.Debugf("Creating bucket if not exist %q", key)
defer func() {
if err != nil {
lg.Errorf("Creating bucket if not exist %q failed: %v", key, err)
} else {
lg.Debugf("Creating bucket if not exist %q successfully", key)
}
}()
}
// 检查数据库是否关闭,检查事务是否可写,检查键名是否为空。
if b.tx.db == nil {
return nil, errors.ErrTxClosed
} else if !b.tx.writable {
return nil, errors.ErrTxNotWritable
} else if len(key) == 0 {
return nil, errors.ErrBucketNameRequired
}
// 使用克隆的键而不是原始键,以避免内存泄漏。
newKey := cloneBytes(key)
// 检查键是否已存在。
if b.buckets != nil {
if child := b.buckets[string(newKey)]; child != nil {
return child, nil
}
}
// 使用光标寻找正确的位置。
c := b.Cursor()
k, v, flags := c.seek(newKey)
// 如果找到的键相同,检查是否已有相同名字的非存储桶键。
if bytes.Equal(newKey, k) {
if (flags & common.BucketLeafFlag) != 0 {
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(newKey)] = child
}
return child, nil
}
return nil, errors.ErrIncompatibleValue
}
// 创建空的内联存储桶。
var bucket = Bucket{
InBucket: &common.InBucket{},
rootNode: &node{isLeaf: true},
FillPercent: DefaultFillPercent,
}
var value = bucket.write()
// 在当前节点上插入键、值、标志。
c.node().put(newKey, newKey, value, 0, common.BucketLeafFlag)
// 如果存在内联页面,取消引用它,使得存储桶被视为常规非内联存储桶。
b.page = nil
// 返回新创建的存储桶。
return b.Bucket(newKey), nil
}
// node方法返回光标当前定位的节点。
func (c *Cursor) node() *node {
// 确保光标栈长度大于0,否则抛出异常。
common.Assert(len(c.stack) > 0, "accessing a node with a zero-length cursor stack")
// 如果栈顶是叶子节点,直接返回该节点。
if ref := &c.stack[len(c.stack)-1]; ref.node != nil && ref.isLeaf() {
return ref.node
}
// 从根开始,向下遍历层级结构。
var n = c.stack[0].node
if n == nil {
n = c.bucket.node(c.stack[0].page.Id(), nil)
}
for _, ref := range c.stack[:len(c.stack)-1] {
common.Assert(!n.isLeaf, "expected branch node")
n = n.childAt(ref.index)
}
common.Assert(n.isLeaf, "expected leaf node")
return n
}
// put方法在节点中插入键值对。
func (n *node) put(oldKey, newKey, value []byte, pgId common.Pgid, flags uint32) {
// 检查pgId是否超出限制。
if pgId >= n.bucket.tx.meta.Pgid() {
panic(fmt.Sprintf("pgId (%d) above high water mark (%d)", pgId, n.bucket.tx.meta.Pgid()))
} else if len(oldKey) <= 0 {
panic("put: zero-length old key")
} else if len(newKey) <= 0 {
panic("put: zero-length new key")
}
// 寻找插入的位置。
index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].Key(), oldKey) != -1 })
// 如果没有找到确切匹配,增加容量并移动节点。
exact := len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].Key(), oldKey)
if !exact {
n.inodes = append(n.inodes, common.Inode{})
copy(n.inodes[index+1:], n.inodes[index:])
}
// 设置inode的属性。
inode := &n.inodes[index]
inode.SetFlags(flags)
inode.SetKey(newKey)
inode.SetValue(value)
inode.SetPgid(pgId)
common.Assert(len(inode.Key()) > 0, "put: zero-length inode key")
}
// Bucket方法通过名称检索嵌套桶。
// 如果桶不存在,返回nil。
// 返回的桶实例只在事务生命周期内有效。
func (b *Bucket) Bucket(name []byte) *Bucket {
// 如果已有桶缓存,则直接返回对应桶。
if b.buckets != nil {
if child := b.buckets[string(name)]; child != nil {
return child
}
}
// 移动光标到键位置。
c := b.Cursor()
k, v, flags := c.seek(name)
// 如果键不存在或者不是桶标志,则返回nil。
if !bytes.Equal(name, k) || (flags & common.BucketLeafFlag) == 0 {
return nil
}
// 否则创建并缓存桶。
var child = b.openBucket(v)
if b.buckets != nil {
b.buckets[string(name)] = child
}
return child
}
插入 key/value
func (b *Bucket) Put(key []byte, value []byte) (err error) {
if lg := b.tx.db.Logger(); lg != discardLogger {
lg.Debugf("Putting key %q", key)
defer func() {
if err != nil {
lg.Errorf("Putting key %q failed: %v", key, err)
} else {
lg.Debugf("Putting key %q successfully", key)
}
}()
}
if b.tx.db == nil {
return errors.ErrTxClosed
} else if !b.Writable() {
return errors.ErrTxNotWritable
} else if len(key) == 0 {
return errors.ErrKeyRequired
} else if len(key) > MaxKeySize {
return errors.ErrKeyTooLarge
} else if int64(len(value)) > MaxValueSize {
return errors.ErrValueTooLarge
}
newKey := cloneBytes(key)
// 移动光标到键位置。
c := b.Cursor()
k, _, flags := c.seek(newKey)
// Return an error if there is an existing key with a bucket value.
if bytes.Equal(newKey, k) && (flags&common.BucketLeafFlag) != 0 {
return errors.ErrIncompatibleValue
}
// gofail: var beforeBucketPut struct{}
c.node().put(newKey, newKey, value, 0, 0)
return nil
}
事务
BoltDB 支持 ACID 事务,并采用了使用读写锁机制,支持多个读操作与一个写操作并发执行,让应用程序可以更简单的处理复杂操作。每个事务都有一个 txid,其中db.meta.txid 保存了最大的已提交的写事务 id。BoltDB 对写事务和读事务执行不同的 id 分配策略:
- 读事务:txid == db.meta.txid;
- 写事务:txid == db.meta.txid + 1;
- 当写事务成功提交时,会更新了db.meta.txid为当前写事务 id。
数据库初始化时会将页号为 0 和 1 的两个页面设置为meta页,每个事务会获得一个txid,并选取txid % 2的meta页做为该事务的读取对象,每次写数据后会交替更新meta页。当其中一个出现数据校验不一致时会使用另一个meta页。
BoltDB 的写操作都是在内存中进行,若事务未 commit 时出错,不会对数据库造成影响;若是在 commit 的过程中出错,BoltDB 写入文件的顺序也保证了不会造成影响:因为数据会写在新的 page 中不会覆盖原来的数据,且此时 meta中的信息不发生变化。
- 开始一份写事务时,会拷贝一份 meta数据;
- 从 rootBucket 开始,遍历 B+ Tree 查找数据位置并修改;
- 修改操作完成后会进行事务 commit,此时会将数据写入新的 page;
- 最后更新meta的信息。
// Tx 代表数据库上的一个只读或读写事务。
// 只读事务可用于检索键值和创建光标。
// 读写事务可以创建和删除桶以及创建和删除键。
//
// 重要:必须在使用完事务后提交或回滚事务。
// 只有当没有事务在使用页面时,写入者才能回收这些页面。
// 长时间运行的读事务可能会导致数据库迅速增长。
type Tx struct {
writable bool // 是否为可写事务
managed bool // 是否为管理事务
db *DB // 关联的数据库实例
meta *common.Meta // 元数据指针
root Bucket // 根桶
pages map[common.Pgid]*common.Page // 页面映射
stats TxStats // 事务统计
commitHandlers []func() // 提交处理程序列表
// WriteFlag 指定写相关方法(如 WriteTo())的标志。
// Tx 使用指定的标志打开数据库文件以复制数据。
//
// 默认情况下,此标志未设置,适合主要在内存中的工作负载。
// 对于大于可用 RAM 的数据库,可以设置为 syscall.O_DIRECT 来避免淘汰页面缓存。
WriteFlag int
}
Begin
// Begin 开始一个新事务。
// 多个只读事务可以并发使用,但一次只能使用一个写事务。
// 启动多个写事务会导致调用阻塞,并序列化直到当前写事务完成。
//
// 事务不应该彼此依赖。在同一个goroutine中打开一个读事务和一个写事务可能会导致写入者死锁,
// 因为数据库需要定期重新映射自身以应对增长,并且在读事务打开的时候无法进行。
//
// 如果需要长时间运行的读事务(例如,快照事务),你可能想要将DB.InitialMmapSize设置为足够大的值
// 以避免写事务的潜在阻塞。
//
// 重要:你必须在完成后关闭只读事务,否则数据库将无法回收旧页面。
func (db *DB) Begin(writable bool) (t *Tx, err error) {
if lg := db.Logger(); lg != discardLogger {
lg.Debugf("Starting a new transaction [writable: %t]", writable)
defer func() {
if err != nil {
lg.Errorf("Starting a new transaction [writable: %t] failed: %v", writable, err)
} else {
lg.Debugf("Starting a new transaction [writable: %t] successfully", writable)
}
}()
}
if writable {
return db.beginRWTx()
}
return db.beginTx()
}
func (db *DB) beginRWTx() (*Tx, error) {
// If the database was opened with Options.ReadOnly, return an error.
if db.readOnly {
return nil, berrors.ErrDatabaseReadOnly
}
// Obtain writer lock. This is released by the transaction when it closes.
// This enforces only one writer transaction at a time.
db.rwlock.Lock()
// Once we have the writer lock then we can lock the meta pages so that
// we can set up the transaction.
db.metalock.Lock()
defer db.metalock.Unlock()
// Exit if the database is not open yet.
if !db.opened {
db.rwlock.Unlock()
return nil, berrors.ErrDatabaseNotOpen
}
// Exit if the database is not correctly mapped.
if db.data == nil {
db.rwlock.Unlock()
return nil, berrors.ErrInvalidMapping
}
// Create a transaction associated with the database.
t := &Tx{writable: true}
t.init(db)
db.rwtx = t
db.freePages()
return t, nil
}
// freePages 释放与已关闭的只读事务关联的任何页面。
func (db *DB) freePages() {
sort.Sort(txsById(db.txs))
minid := common.Txid(0xFFFFFFFFFFFFFFFF)
if len(db.txs) > 0 {
minid = db.txs[0].meta.Txid()
}
if minid > 0 {
db.freelist.release(minid - 1)
}
for _, t := range db.txs {
db.freelist.releaseRange(minid, t.meta.Txid()-1)
minid = t.meta.Txid() + 1
}
db.freelist.releaseRange(minid, common.Txid(0xFFFFFFFFFFFFFFFF))
}
func (db *DB) beginTx() (*Tx, error) {
// Lock the meta pages while we initialize the transaction. We obtain
// the meta lock before the mmap lock because that's the order that the
// write transaction will obtain them.
db.metalock.Lock()
// Obtain a read-only lock on the mmap. When the mmap is remapped it will
// obtain a write lock so all transactions must finish before it can be
// remapped.
db.mmaplock.RLock()
// Exit if the database is not open yet.
if !db.opened {
db.mmaplock.RUnlock()
db.metalock.Unlock()
return nil, berrors.ErrDatabaseNotOpen
}
// Exit if the database is not correctly mapped.
if db.data == nil {
db.mmaplock.RUnlock()
db.metalock.Unlock()
return nil, berrors.ErrInvalidMapping
}
// Create a transaction associated with the database.
t := &Tx{}
t.init(db)
// Keep track of transaction until it closes.
db.txs = append(db.txs, t)
n := len(db.txs)
// Unlock the meta pages.
db.metalock.Unlock()
// Update the transaction stats.
db.statlock.Lock()
db.stats.TxN++
db.stats.OpenTxN = n
db.statlock.Unlock()
return t, nil
}
Commit
// Commit 将所有更改写入磁盘,更新元数据页,并关闭事务。
// 如果磁盘写入发生错误,或者在只读事务上调用Commit,将返回错误。
func (tx *Tx) Commit() (err error) {
txId := tx.ID() // 获取事务ID
lg := tx.db.Logger() // 获取日志记录器
if lg != discardLogger {
lg.Debugf("Committing transaction %d", txId)
defer func() {
if err != nil {
lg.Errorf("Committing transaction failed: %v", err)
} else {
lg.Debugf("Committing transaction %d successfully", txId)
}
}()
}
// 检查是否为管理事务,不允许提交。
common.Assert(!tx.managed, "managed tx commit not allowed")
if tx.db == nil {
return berrors.ErrTxClosed // 事务已关闭错误
} else if !tx.writable {
return berrors.ErrTxNotWritable // 非写事务错误
}
// TODO: 使用向量化I/O写出脏页
// 重新平衡删除后的节点
var startTime = time.Now()
tx.root.rebalance()
if tx.stats.GetRebalance() > 0 {
tx.stats.IncRebalanceTime(time.Since(startTime))
}
opgid := tx.meta.Pgid() // 获取旧的页面ID
// 将数据溢出到脏页
startTime = time.Now()
if err = tx.root.spill(); err != nil {
lg.Errorf("spilling data onto dirty pages failed: %v", err)
tx.rollback()
return err
}
tx.stats.IncSpillTime(time.Since(startTime))
// 释放旧的根桶
tx.meta.RootBucket().SetRootPage(tx.root.RootPage())
// 释放旧的自由列表,因为提交会写出一个新的自由列表
if tx.meta.Freelist() != common.PgidNoFreelist {
tx.db.freelist.free(tx.meta.Txid(), tx.db.page(tx.meta.Freelist()))
}
if !tx.db.NoFreelistSync {
err = tx.commitFreelist()
if err != nil {
lg.Errorf("committing freelist failed: %v", err)
return err
}
} else {
tx.meta.SetFreelist(common.PgidNoFreelist)
}
// 如果高水位标记已上移,则尝试扩大数据库
if tx.meta.Pgid() > opgid {
if err = tx.db.grow(int(tx.meta.Pgid()+1) * tx.db.pageSize); err != nil {
lg.Errorf("growing db size failed, pgid: %d, pagesize: %d, error: %v", tx.meta.Pgid(), tx.db.pageSize, err)
tx.rollback()
return err
}
}
// 将脏页写入磁盘
startTime = time.Now()
if err = tx.write(); err != nil {
lg.Errorf("writing data failed: %v", err)
tx.rollback()
return err
}
// 如果启用了严格模式,则执行一致性检查
if tx.db.StrictMode {
ch := tx.Check()
var errs []string
for {
chkErr, ok := <-ch
if !ok {
break
}
errs = append(errs, chkErr.Error())
}
if len(errs) > 0 {
panic("check fail: " + strings.Join(errs, "\n"))
}
}
// 将元数据写入磁盘
if err = tx.writeMeta(); err != nil {
lg.Errorf("writeMeta failed: %v", err)
tx.rollback()
return err
}
tx.stats.IncWriteTime(time.Since(startTime))
// 结束事务
tx.close()
// 执行提交处理程序,锁已经移除
for _, fn := range tx.commitHandlers {
fn()
}
return nil
}
Rollback
// Rollback 关闭事务并忽略所有之前的更新。
// 只读事务必须回滚而不是提交。
func (tx *Tx) Rollback() error {
common.Assert(!tx.managed, "managed tx rollback not allowed") // 断言此事务不是管理型事务
if tx.db == nil {
return berrors.ErrTxClosed // 如果数据库已关闭,返回错误
}
tx.nonPhysicalRollback() // 执行非物理性回滚
return nil
}
// nonPhysicalRollback 在用户直接调用Rollback时被调用,在这种情况下,我们不需要从磁盘重新加载自由页面。
func (tx *Tx) nonPhysicalRollback() {
if tx.db == nil {
return // 如果数据库已关闭,直接返回
}
if tx.writable {
tx.db.freelist.rollback(tx.meta.Txid()) // 如果事务是可写的,回滚自由列表
}
tx.close() // 关闭事务
}
// rollback 从给定的挂起事务中移除页面。
func (f *freelist) rollback(txid common.Txid) {
// 从缓存中移除页面ID。
txp := f.pending[txid]
if txp == nil {
return // 如果没有挂起的事务,直接返回
}
var m common.Pgids
for i, pgid := range txp.ids {
delete(f.cache, pgid) // 从缓存中删除页面ID
tx := txp.alloctx[i]
if tx == 0 {
continue // 如果未分配事务ID,继续下一个
}
if tx != txid {
// 如果待释放页面被中断,恢复页面回分配列表。
f.allocs[pgid] = tx
} else {
// 如果释放的页面由此事务分配,可以安全地丢弃。
m = append(m, pgid)
}
}
// 从挂起列表中移除页面,并将其标记为由txid分配的自由页面。
delete(f.pending, txid)
f.mergeSpans(m)
}
View && Update
// View 在管理的只读事务上下文中执行一个函数。
// 从函数返回的任何错误都会从View()方法返回。
//
// 尝试在函数内手动回滚会导致panic。
func (db *DB) View(fn func(*Tx) error) error {
t, err := db.Begin(false) // 开始一个只读事务
if err != nil {
return err // 如果无法开始事务,返回错误
}
// 确保在发生panic的情况下事务能够回滚。
defer func() {
if t.db != nil {
t.rollback() // 执行回滚操作
}
}()
// 标记为管理的事务,以便内部函数不能手动回滚。
t.managed = true
// 如果函数返回错误,则传递该错误。
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback() // 执行回滚
return err
}
return t.Rollback() // 完成后回滚事务
}
// Update 在读写管理事务的上下文中执行一个函数。
// 如果函数没有返回错误,则提交事务。
// 如果返回了错误,则整个事务被回滚。
// 从函数返回的任何错误或从提交返回的错误都会从Update()方法返回。
//
// 尝试在函数内手动提交或回滚将导致panic。
func (db *DB) Update(fn func(*Tx) error) error {
t, err := db.Begin(true) // 开始一个读写事务
if err != nil {
return err // 如果无法开始事务,返回错误
}
// 确保在发生panic的情况下事务能够回滚。
defer func() {
if t.db != nil {
t.rollback() // 执行回滚操作
}
}()
// 标记为管理的事务,以便内部函数不能手动提交。
t.managed = true
// 如果函数返回错误,则回滚并返回错误。
err = fn(t)
t.managed = false
if err != nil {
_ = t.Rollback() // 执行回滚
return err
}
return t.Commit() // 无错误时提交事务
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号